
Doppelt gemoppelt: Wie man Cluster “clustered”. MySQL-InnoDB-ClusterSets
Über den MySQL-InnoDB-Cluster und die zugehörigen Komponenten wie die MySQL-Shell und den MySQL-Router haben wir an dieser Stelle bereits mehrfach berichtet (z.B. https://blog.ordix.de/mysql-shell-cluster-your-application-in-40-minutes). Mit der Version 8.0.28 gibt es eine weitere Neuerung bei diesem "Dreigestirn". Die InnoDB-ClusterSets. Damit ist der DBA komfortabel in der Lage eine asynchrone Replikation zwischen zwei InnoDB-Clustern mit wenigen Kommandos aufzubauen.
Ein Cluster kommt selten allein...
Nehmen wir einmal an, dass wir für unseren "Use-Case" bereits ein InnoDB-Cluster in einer Region wie z.B. Deutschland betreiben. Dieser Cluster besteht aus drei Knoten, welche über mehrere Standorte verteilt (Frankfurt, Berlin, Hamburg) aufgebaut wurden. Auf den Cluster greift neben einer schreibenden Applikation auch eine "Reporting"-Anwendung lesend zu. Die Verteilung (Lesende vs. Schreibende Applikation) wird vom MySQL Router transparent erledigt (Abb. 1 aus PPT).
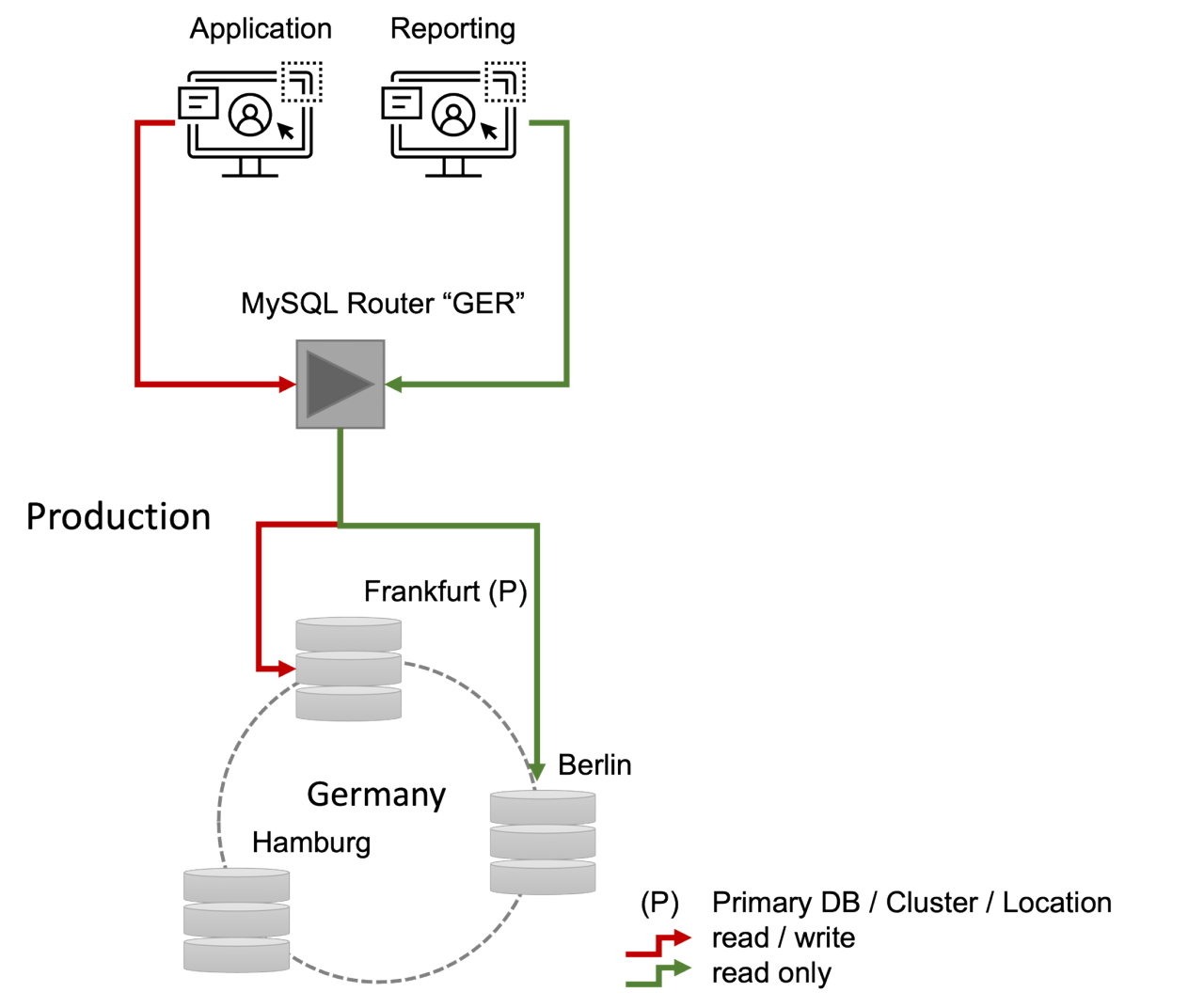
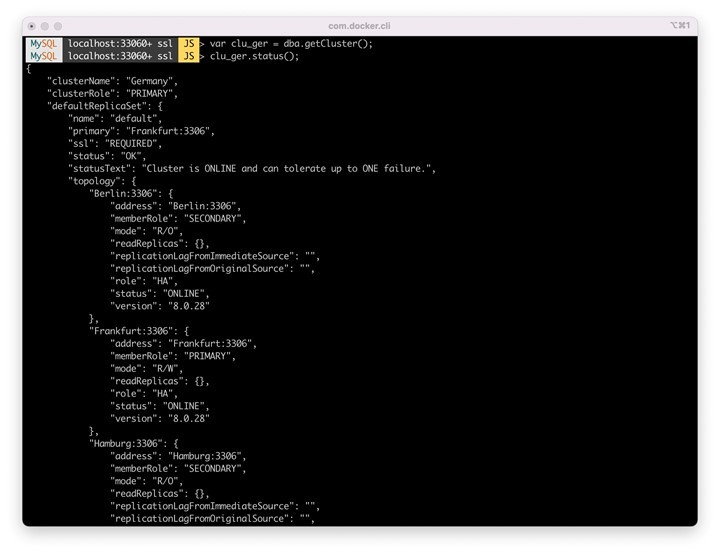
Wir sehen im folgendem die aktuelle Konfiguration unseres Clusters. Er besteht aus den drei oben genannten Knoten. Der Knoten "Frankfurt" ist in der Rolle des "Primary"-Servers und kann lesend und schreibend verwendet werden.
Nun möchten wir unser Geschäftsmodell auch auf die USA ausweiten und dort ebenfalls lokal einen Cluster betreiben. Gründe hierfür könnten eine Ausweitung des DR (Desaster Recovery) Konzeptes und/oder eine bessere Performance (für die lesende) Applikation sein.
Auf in die "neue Welt"....
Wir gehen davon aus, dass in der neuen Region "Amerika" bereits drei Datenbanken zur Verfügung gestellt wurden (NewYork, Boston, LasVegas). Zu diesem Zeitpunkt handelt es sich um drei vollkommen unabhängige Datenbank-Instanzen, die keinerlei Beziehungen zueinander und vor allem nicht zu dem Cluster in Deutschland haben.
Im ersten Schritt nutzen wir unseren vorhandenen Cluster "Germany" und teilen ihm mit, dass ein "ClusterSet" "Production" aufgebaut werden soll:
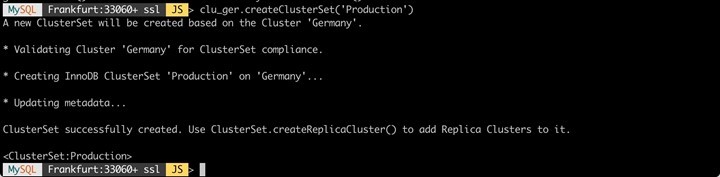
Aktuell hat sich am physikalischen Setup der Infrastruktur (Anzahl der DB-Systeme) nichts geändert. Aus diesem Grund fügen wir nun den ersten (!) Server aus "Übersee" als "Cluster" hinzu.
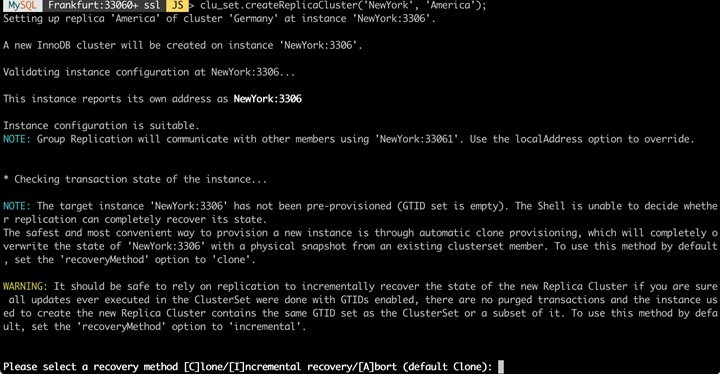
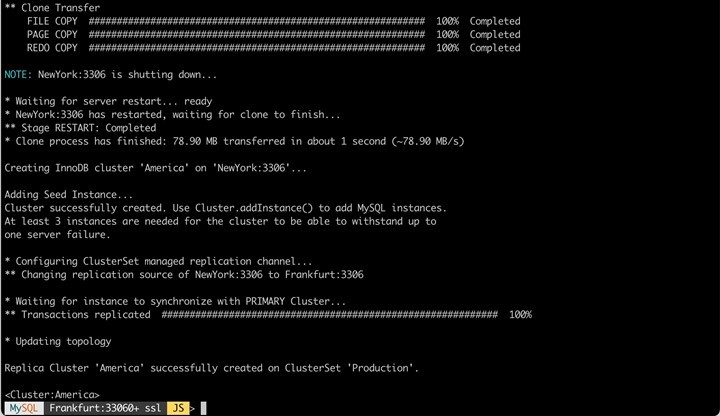
Damit "hängt" an unserem "deutschen", ein "amerikanischer" Cluster, welcher aktuell aber nur aus einem Knoten "NewYork" besteht. Das ändern wir, indem wir zwei weitere Knoten anhängen (hier wird nur der Vorgang für ein Knoten "Boston" dargestellt).
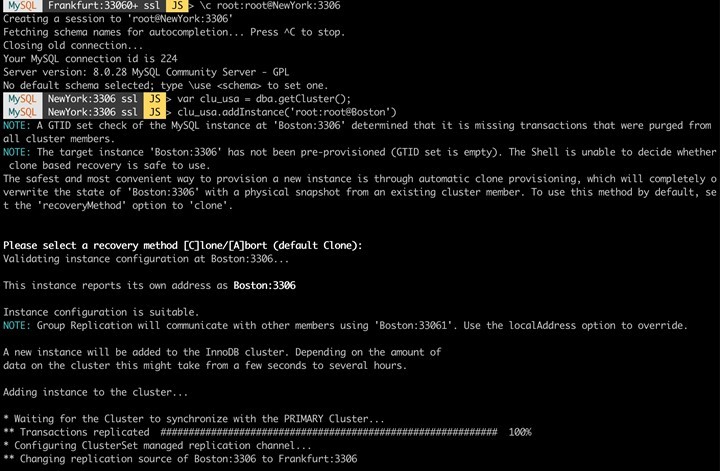
Nach dem erfolgreichen Aufbau ist unser ClusterSet "Production" nun mit zwei Clustern in zwei Regionen in Betrieb. Es ist klar zu erkennen, dass der Cluster "Germany" führend ist und "America" derzeit als Replikat fungiert.
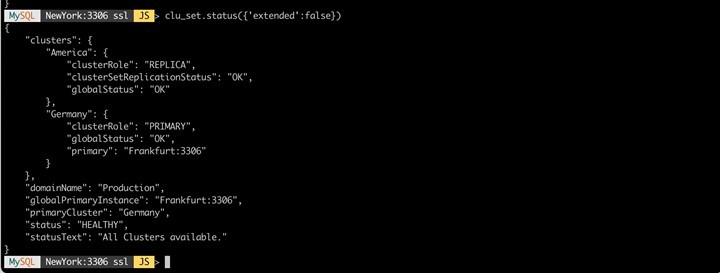
Unser Setup sieht damit wie folgt aus:
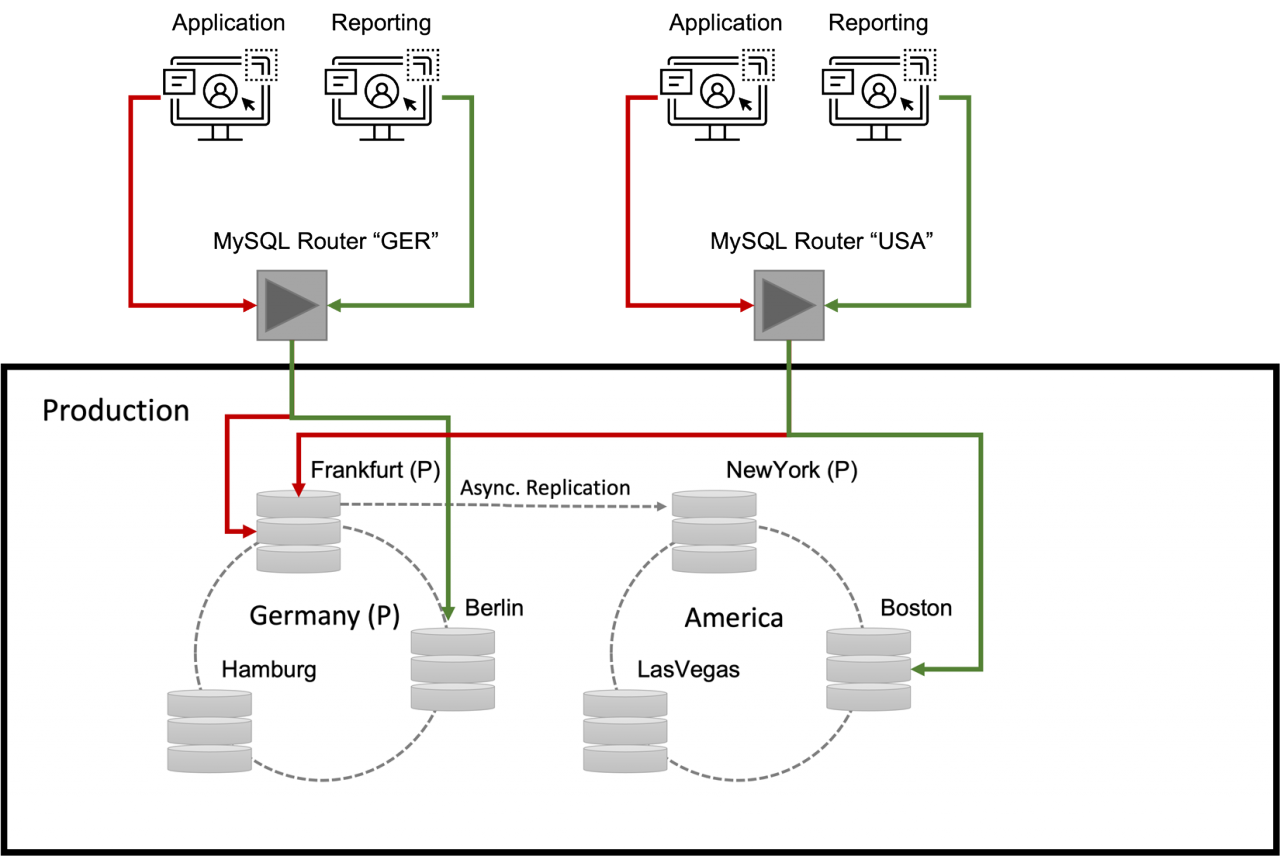
Zu beachten ist, dass die Verbindung zwischen den beiden Clustern "Germany" und "America" asynchron ist. Das bedeutet, dass beim Ausfall der Region "Deutschland", zwar auf der anderen Seite des "großen Teiches" wieder eine (hoch-)verfügbare Umgebung (das Cluster "America") bereitsteht, allerdings kann es beim Switch bzw. Failover dorthin durchaus zu einem (minimalen) Datenverlust gekommen sein, sodass es einige wenige Transaktionen ggfs. Nicht mehr auf die "andere Seite" geschafft haben.
Die Route wird berechnet...
Die Router (die im Zusammenhang mit Clustern quasi zwingend sind) werden im einfachsten Fall wie gehabt aufgebaut. Beim "bootstrapen" erkennen sie das Setup des ClusterSets und leiten schreibende Anfragen verlässlich auf den primären (!) Knoten im primären (!) Cluster. Weitere Router (z.B. für lesende Anfragen) können wahlweise auf die sekundären Knoten des primären oder sekundären Clusters verwiesen werden. Auch diese Routing-Strategien können direkt über die MySQL-Shell definiert werden.
Selbstverständlichen können auch die Rollen der Datenbanken in Ihren Clustern aber auch die Rollen der Cluster innerhalb des Sets verändert werden. Im Fehlerfall erfolgt eine Neu-Konfiguration natürlich ebenfalls automatisch. So wird z.B. beim Ausfall eines Knotens, innerhalb eines Clusters, eine andere Instanz primär. Fällt das primäre Cluster (!) aus, so wird ein anderes Set des Clusters (ein ClusterSet kann natürlich aus mehr als zwei Sets von Clustern bestehen) als primär definiert. Die Router erkennen diese Veränderungen eigenständig und leiten die entsprechenden Applikationen dementsprechend um.
Cluster, clustern?!
Wieder einmal wurde die Funktionalität des InnoDB-Clusters sinnvoll erweitert. Natürlich ist zu beachten, dass ein Replikation-Set nicht synchron arbeitet und damit eher eine Art von DR-Lösung darstellt (aus Sicht des primären Clusters) und nicht wirklich ein "geclustertes Cluster" ist.
Nichtsdestotrotz ist es in Zeiten von virtuellen und/oder Cloud-Umgebungen beeindruckend wie schnell und transparent solch komplexe Umgebungen bereitgestellt und verwaltet werden können.
Seminarempfehlung
Sie haben Fragen rund um den Betrieb von MySQL?
Sprechen Sie uns an oder besuchen Sie eines unserer Seminare zu diesem Thema:
MYSQL ADMINISTRATION DB-MY-01
Zum Seminar-sHOPPrincipal Consultant bei ORDIX
Kommentare