
Apache Hive 3 Transactional Tables - Ein Elefant im Bienenstock
Mit dem Release 3.1.0 der Hortonworks Data Platform (HDP) hat auch Hive 3 Einzug in die Hadoop-Distribution gehalten. Mit Hive 3 wurde die ACID-Funktionalität stark verbessert, sodass Transactional Tables nun der Standard-Tabellentyp sind. Wie Transactional Tables verwendet werden, was es bezüglich des darunterliegenden Dateisystems zu beachten gibt und wie die Compactions in Hive 3 funktionieren, erklärt dieser Beitrag.
Grundlagen zum Verständnis
Was ist Hive?
Hive ist ein Datawarehouse-System für Hadoop. Es stellt eine SQL-ähnliche Schnittstelle (HiveQL/HQL) für die Abfrage und Analyse der Daten bereit. Hive übersetzt die HQL-Befehle in performante Hadoop-Jobs. Durch die großen Ähnlichkeiten können Anwender, die bereits SQL-Kenntnisse haben, ohne intensiven Einarbeitungsaufwand mit Hive arbeiten. Hive stellt eine Vielzahl von Funktionen für die Analyse von Daten bereit.
Grundlagen: Tabellentypen in Hive 3
Es gibt in Hive 3 vier unterschiedliche Tabellentypen:
| Table Type | ACID | File Format | INSERT | UPDATE/DELETE |
| Managed: CRUD transactional | Yes | ORC | Yes | Yes |
| Managed: Insert-only transactional | Yes | Any | Yes | No |
| Managed: Temporary | No | Any | Yes | No |
| External | No | Any | Yes | No |
Managed bedeutet, dass die Daten durch Hive verwaltet werden. Die Daten liegen im Hive-Warehouse-Verzeichnis im HDFS (Hadoop Distributed File System). Wird eine Tabelle nun gelöscht (Drop Table), dann sind alle Daten der Tabelle gelöscht.
External bedeutet, dass die Daten nicht von Hive verwaltet werden. Wird eine External Table gelöscht, dann sind die Quelldaten nicht automatisch auch gelöscht. Externe Tabellen können für Daten im HDFS und auch für Daten in anderen Systemen, wie zum Beispiel HBase, genutzt werden.
Managed: CRUD transactional tables mit Update- und Delete-Funktionalität sind nur im ORC-Dateiformat möglich. Die Standard-Pfade für die Tabellen im HDFS haben sich geändert, sie liegen nun unter /warehouse/tablespace/[managed|external]/hive/
Any beinhaltet die folgenden Dateiformate: TXT, CSV, AVRO, ORC, PARQUET und JSON. Insert-only Transactional Tables konnten in Hive 2 nur im ORC-Format angelegt werden, seit Hive 3 können alle Dateiformate verwendet werden.
Grundlagen: Was sind Buckets und Partitions in Hive?
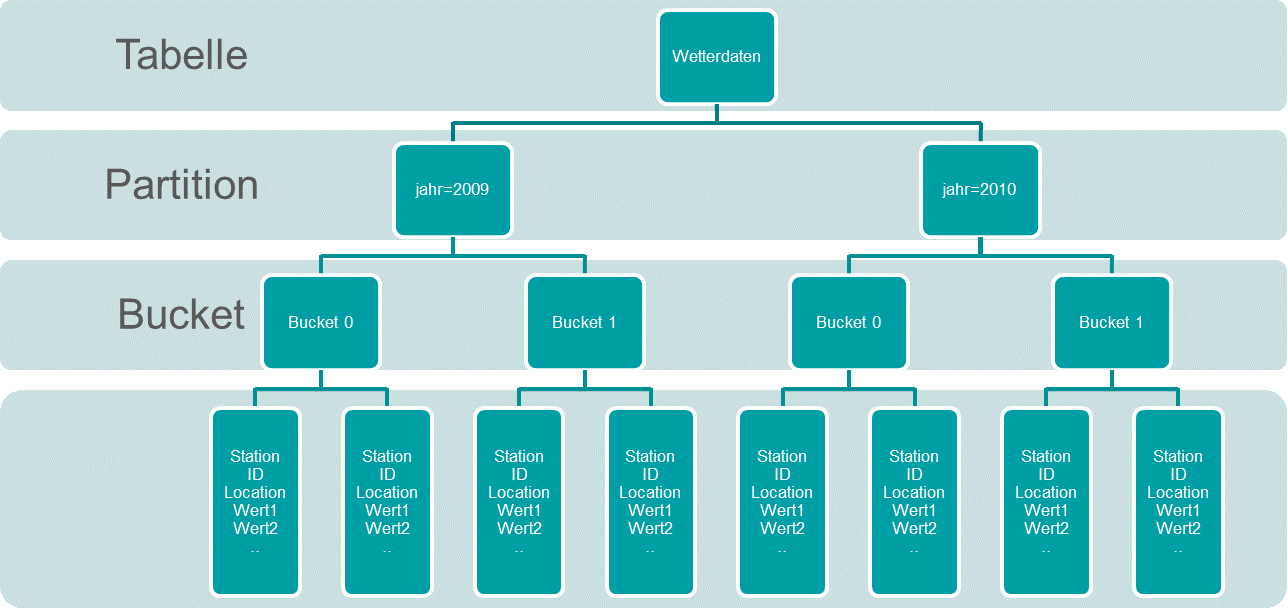
Die Daten können nach einer Spalte partitioniert werden, zum Beispiel nach Jahr – alle Daten von allen enthaltenen Jahren liegen dann jeweils zusammen in einer Partition, die sich auf das jeweilige Jahr bezieht.
Technisch ist eine Partition ein weiteres Verzeichnis im HDFS.
/warehouse/tablespace/managed/hive/Wettterdaten/jahr=2009/ /warehouse/tablespace/managed/hive/Wettterdaten/jahr=2010/
Bucket wird die Datei genannt, in der die Daten gespeichert sind. Im obigen Beispiel sind die Daten eines Jahres auf zwei Buckets verteilt. Die Daten werden anhand einer Spalte mit einer Hash-Funktion auf die Buckets verteilt, zum Beispiel die StationID. Damit liegen alle Daten einer Messstation eines Jahres in einer Datei.
/warehouse/tablespace/managed/hive/Wettterdaten/jahr=2010/ /base_0000002/bucket_00000 /warehouse/tablespace/managed/hive/Wettterdaten/jahr=2010/ /base_0000002/bucket_00001
Hier gibt es weitere Informationen bezüglich Bucketed Tables: Hive/LanguageManual+DDL+BucketedTables. (siehe Abbildung 1).
Hive 3: Transactional Tables
In Hive 3 wurde die Funktionalität der Transactional Tables deutlich verbessert und erweitert. Damit gibt es nun volle CRUD (Create, Retrieval, Update, Delete) -Funktionalität. Die folgenden Abschnitte widmen sich der Frage, was im HDFS passiert, wenn Transactional Tables in Hive 3 erstellt werden, wenn Daten eingefügt, gelöscht oder verändert werden. Beispielhaft wird dies mit Standorten von Wetterstationen durchgeführt. Damit die jeweiligen Beispiele übersichtlich bleiben, wurde nach den jeweiligen Schritten eine Compaction durchgeführt.
Erstellen von Transactional Tables
Im Beispiel wird eine CRUD Transactional Table im Standardverzeichnis im Dateiformat ORC angelegt. Dieses Dateiformat ist das einzige, das für diesen Tabellentyp in Frage kommt.
CREATE TABLE IF NOT EXISTS station ( id STRING, name STRING, region STRING);
Es haben sich wichtige Standardwerte in Hive 3 geändert:
- Das Standarddateiformat ist nun ORC
- TBLPROPERTIES ('transactional'='true') ist standardmäßig gesetzt
- Der Datei-Pfad im HDFS hat sich geändert: /warehouse/tablespace/managed/hive/
Skripte werden dann auch nach Änderung der Standardwerte korrekt ausgeführt und nicht jedem sind alle Standardwerte geläufig.
CREATE TABLE IF NOT EXISTS station ( id STRING, name STRING, region STRING)
STORED AS ORC
LOCATION 'hdfs://localhost:8020/warehouse/tablespace/managed/hive/station'
TBLPROPERTIES ('transactional'='true');
Mit Erstellen der Tabelle wird der folgende Ordner im HDFS angelegt:
hdfs dfs -ls /warehouse/tablespace/managed/hive/ -rw-rw-rw-+ 1 hive hadoop 1 2020-05-13 16:28 /warehouse/tablespace/managed/hive/station/
Der folgende Befehl zeigt die Tabelle, die noch leer ist:
select * from station;
Einfügen von Daten
Insert INTO station (id, name, region) values
('232', 'Augsburg', 'Bayern'),
('282', 'Bamberg', 'Bayern'),
('1420', 'Frankfurt', 'Hessen'),
('2667', 'Köln-Bonn', 'NRW'),
('3028', 'Bad Lippspringe', 'NRW'),
('3404', 'Münster', 'NRW'),
('5541', 'Wiesbaden-Auringen', 'Hessen'),
('5543', 'Wiesbaden-Dotzheim', 'Hessen');
Mit dem Einfügen der Daten werden diese im HDFS zunächst in einem Delta-Verzeichnis gespeichert:
hdfs dfs -ls /warehouse/tablespace/managed/hive/station/*/ Found 2 items -rw-rw-rw-+ 1 hive hadoop 1 2020-05-13 17:10 /warehouse/tablespace/managed/hive/station/delta_0000001_0000001_0000/_orc_acid_version -rw-rw-rw-+ 1 hive hadoop 1096 2020-05-13 17:10 /warehouse/tablespace/managed/hive/station/delta_0000001_0000001_0000/bucket_00000
In der ORC-Datei bucket_00000 sind folgende Daten enthalten:
hive --orcfiledump -d /warehouse/tablespace/managed/hive/station/delta_0000001_0000001_0000/bucket_00000
Processing data file /warehouse/tablespace/managed/hive/station/delta_0000001_0000001_0000/bucket_00000 [length: 1096]
{"operation":0,"originalTransaction":1,"bucket":536870912,"rowId":0,"currentTransaction":1,"row":{"id":"232","name":"Augsburg","region":"Bayern"}}
{"operation":0,"originalTransaction":1,"bucket":536870912,"rowId":1,"currentTransaction":1,"row":{"id":"282","name":"Bamberg","region":"Bayern"}}
{"operation":0,"originalTransaction":1,"bucket":536870912,"rowId":2,"currentTransaction":1,"row":{"id":"1420","name":"Frankfurt","region":"Hessen"}}
{"operation":0,"originalTransaction":1,"bucket":536870912,"rowId":3,"currentTransaction":1,"row":{"id":"2667","name":"Köln-Bonn","region":"NRW"}}
{"operation":0,"originalTransaction":1,"bucket":536870912,"rowId":4,"currentTransaction":1,"row":{"id":"3028","name":"Bad Lippspringe","region":"NRW"}}
{"operation":0,"originalTransaction":1,"bucket":536870912,"rowId":5,"currentTransaction":1,"row":{"id":"3404","name":"Münster","region":"NRW"}}
{"operation":0,"originalTransaction":1,"bucket":536870912,"rowId":6,"currentTransaction":1,"row":{"id":"5541","name":"Wiesbaden-Auringen","region":"Hessen"}}
{"operation":0,"originalTransaction":1,"bucket":536870912,"rowId":7,"currentTransaction":1,"row":{"id":"5543","name":"Wiesbaden-Dotzheim","region":"Hessen"}}
Löschen von Daten
DELETE FROM station where id = "2667";
Beim Löschen des Datensatzes aus der Tabelle wird im HDFS der betreffende Datensatz als gelöscht markiert:
hdfs dfs -ls /warehouse/tablespace/managed/hive/station/*/ Found 2 items -rw-rw-rw-+ 1 hive hadoop 1 2020-05-13 17:49 /warehouse/tablespace/managed/hive/station/delete_delta_0000002_0000002_0000/_orc_acid_version -rw-rw-rw-+ 1 hive hadoop 723 2020-05-13 17:49 /warehouse/tablespace/managed/hive/station/delete_delta_0000002_0000002_0000/bucket_00000 Found 2 items -rw-rw-rw-+ 1 hive hadoop 1 2020-05-13 17:10 /warehouse/tablespace/managed/hive/station/delta_0000001_0000001_0000/_orc_acid_version -rw-rw-rw-+ 1 hive hadoop 1096 2020-05-13 17:10 /warehouse/tablespace/managed/hive/station/delta_0000001_0000001_0000/bucket_00000
Es ist ein Delete-Ordner dazugekommen. In der ORC-Datei sind folgende Daten enthalten:
hive --orcfiledump -d /warehouse/tablespace/managed/hive/station/delete_delta_0000002_0000002_0000/bucket_00000
Processing data file /warehouse/tablespace/managed/hive/station/delete_delta_0000002_0000002_0000/bucket_00000 [length: 723] {"operation":2,"originalTransaction":1,"bucket":536870912,"rowId":3,"currentTransaction":2,"row":null}
Im Original-Datensatz in der ORC-Datei ist Folgendes unter rowId 3 zu finden:
{"operation":0,"originalTransaction":1,"bucket":536870912,"rowId":3,"currentTransaction":1,"row":{"id":"2667","name":"Köln-Bonn","region":"NRW"}}
Konkret in dem Beispiel wird also der Datensatz mit der ID 2667 als gelöscht markiert.
Aktualsieren von Daten
Um Daten zu verändern, erhält die Station in Augsburg exemplarisch eine neue ID:
UPDATE station set id = "3333" where name = "Augsburg";
Im HDFS wird diese Änderung im Datensatz wie folgt abgebildet:
hdfs dfs -ls /warehouse/tablespace/managed/hive/station/*/ Found 3 items -rw-rw-rw-+ 1 hive hadoop 48 2020-05-13 18:01 /warehouse/tablespace/managed/hive/station/base_0000002/_metadata_acid -rw-rw-rw-+ 1 hive hadoop 1 2020-05-13 18:01 /warehouse/tablespace/managed/hive/station/base_0000002/_orc_acid_version -rw-rw-rw-+ 1 hive hadoop 1080 2020-05-13 18:01 /warehouse/tablespace/managed/hive/station/base_0000002/bucket_00000 Found 2 items -rw-rw-rw-+ 1 hive hadoop 1 2020-05-13 18:12 /warehouse/tablespace/managed/hive/station/delete_delta_0000004_0000004_0000/_orc_acid_version -rw-rw-rw-+ 1 hive hadoop 725 2020-05-13 18:12 /warehouse/tablespace/managed/hive/station/delete_delta_0000004_0000004_0000/bucket_00000 Found 2 items -rw-rw-rw-+ 1 hive hadoop 1 2020-05-13 18:12 /warehouse/tablespace/managed/hive/station/delta_0000004_0000004_0000/_orc_acid_version -rw-rw-rw-+ 1 hive hadoop 858 2020-05-13 18:12 /warehouse/tablespace/managed/hive/station/delta_0000004_0000004_0000/bucket_00000

Die Basisdatei station/base_0000002/bucket_00000 wird nicht verändert, es sind zwei Dateien dazu gekommen, delete_delta_0000004_0000004_0000/bucket_00000 für die Löschung und delta_0000004_0000004_0000/bucket_00000 für das neue Einfügen des Datensatzes (siehe Abbildung 2).
Auswirkungen von Einfügen, Löschen und Aktualisieren von Daten in Transactional Tables auf das HDFS
Durch jede Veränderung wird mindestens eine neue Datei angelegt (Delta-Datei). Das HDFS hält die Metainformationen, zum Beispiel den Speicherort der Datei, im Hauptspeicher des NameNodes vor. Wenn der Hauptspeicher voll ist, können keine neuen Daten durch das HDFS angelegt werden und somit auch keine Daten mehr in Hive geschrieben, verändert oder gelöscht werden. In der Dokumentation von Cloudera gibt es Beispiele für die Berechnung des Hauptspeichers des NameNodes.
Damit Hive den aktuellen Stand der Daten ausgeben kann, müssen sowohl die Basisdatei als auch alle Delta-Dateien verarbeitet werden. Dies hat Auswirkungen auf die Performanz der Abfrage. Um einerseits eine hohe Abfragegeschwindigkeit zu gewährleisten und andererseits den Speicherplatz sinnvoll zu nutzen, gibt es in Hive Compactions.
In Hive 3 gibt es zwei Arten von Compactions:
- Minor Compaction: Zusammenfassen der Delta-Dateien eines Buckets in eine Datei
- Major Compaction: Zusammenfassen aller Delta-Dateien eines Buckets in die Basis-Datei des Buckets
Bei der Installation ist Auto-Compaction als Standardwert gesetzt. Es gibt allerdings eine Vielzahl von Szenarien, bei denen es sinnvoll ist, diese zu deaktivieren und Compactions manuell durchzuführen. In den Hive Settings lässt sich Auto-Compaction global deaktivieren, dafür muss in der hive-site.xml der Wert von NO_AUTO_COMPACTION auf true gestellt werden. Für einzelne Tabellen kann der Compactions-Automatismus beim Erstellen über die TBLPROPERTIES der jeweiligen Tabelle de-/aktiviert werden.
Compactions können auch eingeschränkt auf eine Partition durchgeführt werden, die TBLPROPERTIES werden dann nur für diesen Befehl überschrieben.
Zum Beispiel auf die Partition year=2020 und mit Maximum Heap Size des Compaction Map Jobs auf 1024m eingestellt.
ALTER TABLE PARTITION (year=2020) COMPACT ['major'|'minor'] WITH OVERWRITE TBLPROPERTIES ('compactor.mapreduce.map.java.opts'='-Xmx1024m');
Minor Compactions in Hive 3
Im Beispiel wird eine Minor Compaction nach dem Daten-Update der Station in Augsburg sowie einer Änderung der Stations-ID der Bamberger Station durchgeführt. Dies liegt daran, dass eine Minor Compaction nur nach einem Einfügen, einer Änderung oder einer Löschung von mindestens zwei Datensätzen sinnvoll ist.
ALTER TABLE station COMPACT 'minor'
Die Veränderungen vor und nach der Minor Compaction im HDFS:
| Files Before Minor Compaction |
Files After Minor Compaction |
| station/base_0000006/_metadata_acid | station/base_0000006/_metadata_acid |
| station/base_0000006/_orc_acid_version | station/base_0000006/_orc_acid_version |
| station/base_0000006/bucket_00000 | station/base_0000006/bucket_00000 |
| station/delete_delta_0000008_0000008/_orc_acid_version | |
| station/delete_delta_0000008_0000008/bucket_00000 | |
| station/delete_delta_0000009_0000009_0000/bucket_00000 | |
| station/delta_0000008_0000008/_orc_acid_version | |
| station/delta_0000009_0000009_0000/_orc_acid_version | |
| station/delta_0000009_0000009_0000/bucket_00000 | |
| station/delete_delta_0000008_0000009/_orc_acid_version | |
| station/delete_delta_0000008_0000009/bucket_00000 | |
| station/delta_0000008_0000009/_orc_acid_version | |
| station/delta_0000008_0000009/bucket_00000 |
Die Basis-Datei ist unverändert geblieben, alle Delta-Dateien wurden zu einer Delta-Datei zusammengefasst.
In der ORC-Datei sind nun beide Änderungen enthalten:
hive --orcfiledump -d station/delta_0000008_0000009/bucket_00000
Processing data file station/delta_0000008_0000009/bucket_00000 [length: 689]
{"operation":0,"originalTransaction":8,"bucket":536870912,"rowId":0,"currentTransaction":8,"row":{"id":"3333","name":"Augsburg","region":"Bayern"}}
{"operation":0,"originalTransaction":9,"bucket":536870912,"rowId":0,"currentTransaction":9,"row":{"id":"3399","name":"Bamberg","region":"Bayern"}}
Major Compactions in Hive 3
Anschließend wird eine Major Compaction durchgeführt:
ALTER TABLE station COMPACT 'major'
Alle Daten sind dadurch in der Basis-Datei zusammengefasst:
hdfs dfs -ls station/*/
Found 3 items
station/base_0000009/_metadata_acid
station/base_0000009/_orc_acid_version
station/base_0000009/bucket_00000
hive --orcfiledump -d station/base_0000009/bucket_00000
Processing data file station/base_0000009/bucket_00000 [length: 1084]
{"operation":0,"originalTransaction":1,"bucket":536870912,"rowId":2,"currentTransaction":1,"row":{"id":"1420","name":"Frankfurt","region":"Hessen"}}
{"operation":0,"originalTransaction":1,"bucket":536870912,"rowId":4,"currentTransaction":1,"row":{"id":"3028","name":"Bad Lippspringe","region":"NRW"}}
{"operation":0,"originalTransaction":1,"bucket":536870912,"rowId":5,"currentTransaction":1,"row":{"id":"3404","name":"Münster","region":"NRW"}}
{"operation":0,"originalTransaction":1,"bucket":536870912,"rowId":6,"currentTransaction":1,"row":{"id":"5541","name":"Wiesbaden-Auringen","region":"Hessen"}}
{"operation":0,"originalTransaction":1,"bucket":536870912,"rowId":7,"currentTransaction":1,"row":{"id":"5543","name":"Wiesbaden-Dotzheim","region":"Hessen"}}
{"operation":0,"originalTransaction":8,"bucket":536870912,"rowId":0,"currentTransaction":8,"row":{"id":"3333","name":"Augsburg","region":"Bayern"}}
{"operation":0,"originalTransaction":9,"bucket":536870912,"rowId":0,"currentTransaction":9,"row":{"id":"3399","name":"Bamberg","region":"Bayern"}}
Die Status des aktuellen Compaction Jobs und aller bereits gelaufenen Compactions zeigt der folgende Befehl:
show compactions;
| id |
Database | Table | Partition | Type | State | WorkerID | starttime | duration |
| 4 | default | station | --- | MAJOR | working | localhost | 15894 21555000 | --- |
| 3 | default | station | --- | MAJOR | succeeded | --- | 15894 10256000 | 23000 |
| 2 | default | station | --- | MAJOR | succeeded | --- | 15894 04101000 | 630000 |
| 1 | default | station | --- | MAJOR | succeeded | --- | 15894 02592000 | 428000 |
Fazit
Hive 3 hat mit den Transactional Tables eine tolle Neuerung erhalten, denn Updates und Deletes können einfach und performant durchgeführt werden.
Auch wenn automatische Compactions von Haus aus eingestellt sind, hat es sich in der Praxis doch mehrfach gezeigt, dass es sinnvoll ist, diesen Automatismus auszuschalten, da jede Tabelle und jede Partition andere Größen hat.
Daher ist oft der administrative Aufwand, ein für den produktiven Betrieb stabiles Regelwerk für Auto-Compactions zu erstellen, zu hoch.
Gleichzeitig ist die Compaction jedoch so wichtig, dass, wenn sie ignoriert wird, nicht nur zu langsamen Abfragen auf die Tabelle, sondern auch zu clusterweiten Problemen führen kann.
Daher ist ein Monitoring des HDFS sehr wichtig, um dann gezielt dort Compactions durchzuführen, wo sie benötigt werden und die Compactions dann durchzuführen, wann es am sinnvollsten ist.
Kommentare