
Data Science Workbench in der Google Cloud
Für interne Data-Science-Arbeiten soll eine Data Science Workbench in Form einer verwalteten JupyterLab-Instanz in der Google Cloud erstellt werden. Die JupyterLab Instanzen sollen automatisiert gestartet und gestoppt werden können, um dem jeweils aktuellen Bedarf gerecht werden zu können und um Kosten einzusparen. Doch wie könnte eine solche Workbench in der Google Cloud umgesetzt werden?
Jupyter Notebooks
Kern der Data Science Workbench soll eine JupyterLab Instanz sein. Doch was genau ist eigentlich ein JupyterLab? Hierzu schauen wir uns als Erstes die Jupyter Notebooks an.
Ein (Jupyter) Notebook ist allgemein gesagt ein Notizbuch, welches verschiedene Daten beinhalten kann. Eigentlich besteht ein solches Notebook lediglich aus einer Liste von Zellen, wobei jede Zelle Code, Text (in Markdown), Bilder oder andere Daten beinhalten kann. Zusätzlich können zu jeder Zelle noch weitere Metadaten oder auch Anhänge gespeichert werden. Eine Code-Zelle speichert z.B. neben dem eigentlichen Programmcode auch alles, was der enthaltene Code an Aufgaben produziert.
Ein wesentlicher Punkt der Philosophie hinter Notebooks als Programmierumgebung stellt die Interaktivität dar. Code-Zellen in einem Notebook können also interaktiv programmiert und unabhängig vom Rest des Notebooks ausgeführt werden. Realisiert wird diese Interaktivität durch die Trennung von der Notebook-Oberfläche und einem Kernel, der den Code am Ende ausführt. Im Hintergrund kommuniziert das Notebook über das Interactive Computing Protocol über ZMQ und Websockets mit dem Kernel, wobei der Kernel keine Informationen über das eigentliche Notebook hat. Ein Kernel kann damit theoretisch viele verschiedene Notebooks parallel bedienen.
Neben dem Standardkernel (IPython) gibt es verschiedene andere Optionen, die teilweise auch von Third-Party-Entwicklern stammen, über die weitere Programmiersprachen unterstützt werden. So gibt es beispielsweise Kernel für Julia, R, Scala oder DotNet.
Die interaktiven Notebooks wurden ursprünglich im IPython-Projekt entwickelt und 2014 als Project Jupyter ausgegliedert. Der Name Jupyter setzt sich aus den drei wesentlichen Programmiersprachen Julia, Python und R zusammen, ist aber auch eine Anspielung auf die Notizbucheinträge von Galileo zur Entdeckung der Jupitermonde, bei denen er seine Beobachtungen zusätzlich mit Metadaten beschrieb.
Das Project Jupyter verwaltet und entwickelt das Jupyter-Notebook-JSON-Format sowie die Tools Jupyter Notebook, JupyterLab, JupyterHub und andere als Open-Source-Software. Das Jupyter Notebook wird bei einer Anaconda-Installation standardmäßig mitgeliefert und lässt sich über den Befehl jupyter notebook starten. JupyterLab ist das "neue" Webinterface für Jupyter Notebooks und kann, sofern es nicht bereits installiert ist, mit conda install -c conda-forge jupyterlab installiert und dann mit jupyter lab gestartet werden.
Die Anzeige von Jupyter Notebooks wird auch direkt in u.a. Github oder Visual Studio Code unterstützt.
Google AI Platform Notebooks
Google bietet mit den AI Platform Notebooks eine verwaltete JupyterLab-Instanz an. Intern wird dafür eine Compute-Engine-Instanz erzeugt, die auf den Deep Learning VM Images von Google basiert. Populäre Frameworks wie pandas, scikit-learn, NLTK, TensorFlow und PyTorch sind bereits vorinstalliert, wobei für TensorFlow und PyTorch jeweils eigene Images bereitstehen. Weitere Pakete können über die Anaconda-Instanz nachinstalliert werden. Als Betriebssystem stehen Debian 10 oder Ubuntu 18.04 zur Verfügung, allerdings ist Ubuntu zum aktuellen Zeitpunkt (07.06.2021) als experimental gekennzeichnet.
Für die Compute- Engine-Instanz können Maschinentypen der Kategorien N1, N2, E2, C2 (Compute-Optimized) oder M1 (Memory-Optimized) gewählt werden. Einige Maschinentypen (z.B. N1 Standard) können auch mit GPUs erweitert werden, wobei in einigen Google-Cloud-Regionen nicht alle GPUs zur Auswahl stehen.
Die AI Platform Notebooks können auch über die neue Vertex-AI-Schnittstelle verwendet werden.
Automatisierte AI Platform Notebooks mit Terraform
Ein wesentlicher Bestandteil der Data Science Workbench ist das automatisierte Aufsetzen und Verwalten der JupyterLab Instanzen. Eine Instanz soll zusätzlich auch mit einer GPU ausgestattet werden können, um das Training von Modellen zu beschleunigen. Neben dem eigentlichen Notebook sollen Google Cloud Storage Buckets für Daten verwendet werden. Die AI Platform Notebooks in der Google Cloud bietet sich dafür an.
Der Aufbau einer solchen Workbench ist dann wie folgt:
- AI Platform Notebook
- Privater Cloud Storage Bucket für Daten
- Geteilter Cloud Storage Bucket für Daten
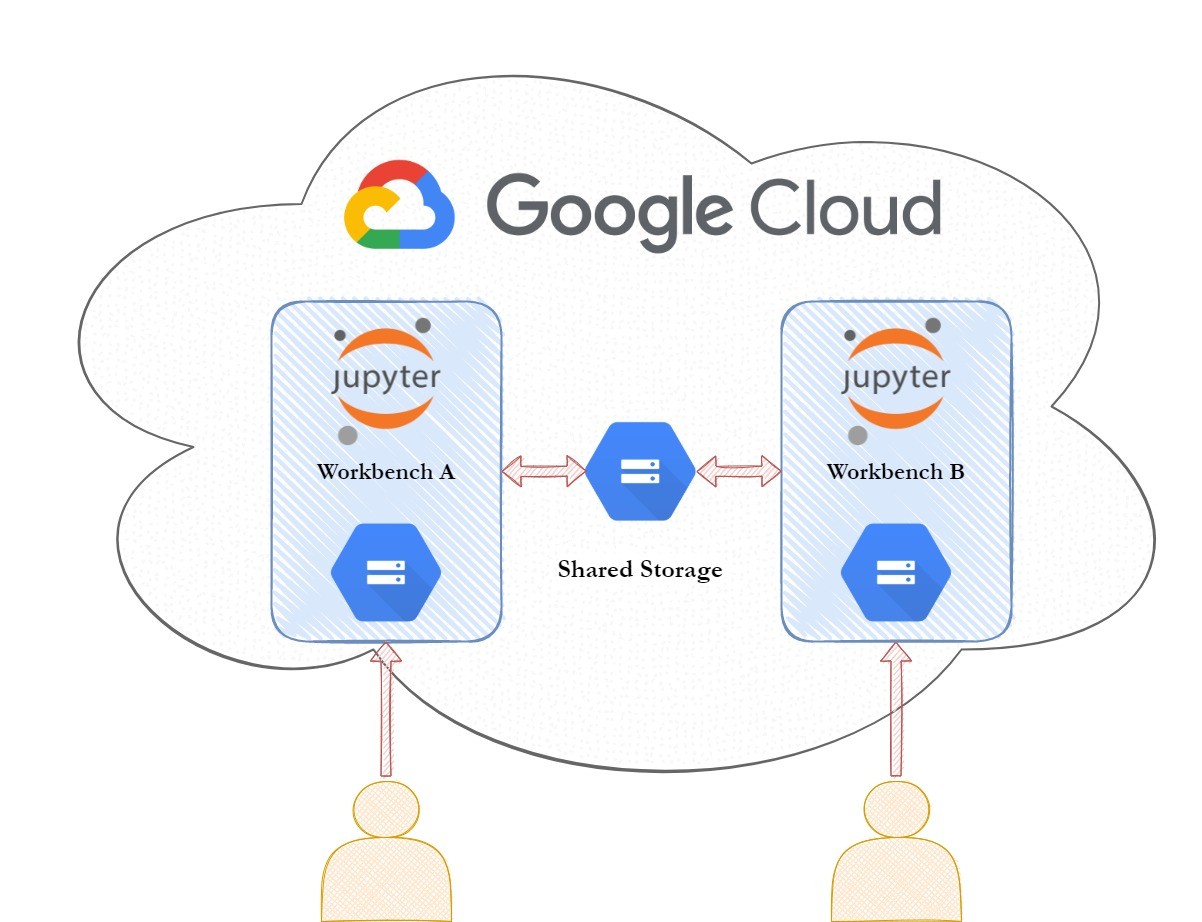
Ein Arbeitsplatz sollte automatisiert erstellt und gelöscht werden können, wobei die Storage Buckets möglicherweise weiter bestehen müssen.
Für die Automatisierung bietet sich Terraform an. Terraform ist ein Infrastructure-as-Code-Tool, mit dem Infrastrukturen bei verschiedenen Cloud Providern erstellt und verwaltet werden kann. Die benötigte Infrastruktur wird dabei in der Hashicorp Configuration Language (HCL) beschrieben, die dem JSON Format ähnelt. Über den Google Cloud Provider können mit Terraform auch direkt AI Platform Notebooks erstellt werden.
Die Terraform Struktur
Um Infrastruktur provisionieren zu können, müssen erstmal die verwendeten Provider definiert werden. In unserem Anwendungsfall ist dies nur die Google Cloud Platform, wofür der offizielle Google Cloud Provider verwendet wird. Der Provider wird in einem Terraform Block als required_providers gekennzeichnet.
terraform {
required_providers {
google = {
source = "hashicorp/google"
version = "3.66.1"
}
}
}
provider "google" {
credentials = file("key.json")
project = "example_google_cloud_project"
region = "us-central1"
zone = "us-central1-a"
}
Zusätzlich müssen weitere Metadaten für den jeweiligen Provider hinterlegt werden. Im Fall der Google Cloud sind dies die credentials, das project, die region und die zone. Als Credentials wird hier ein Google Service Account verwendet, der in der Datei key.json definiert ist. Diese Datei lässt sich beim Erstellen eines Service-Accounts in der Google Cloud Console direkt herunterladen. Das Projekt wird für die Abrechnung der genutzten Cloud Services verwendet. Als Region muss natürlich nicht us-central1 verwendet werden. Hier muss lediglich beachtet werden, dass in einigen Regionen (z.B. europe-west3 [Frankfurt]) nur wenige oder gar keine Grafikkarten auswählbar sind. Wenn also ein Notebook mit GPU-Unterstützung benötigt wird, können diese Regionen ggfs. nicht genutzt werden. Die Auswahlmöglichkeiten für GPUs variieren auch nach Zone. Eine Übersicht, welche GPUs in welcher Region und Zone verfügbar sind, findet sich hier.
Die gezeigte Konfiguration genügt bereits, um Infrastruktur in der Google Cloud zu verwalten. Nun wird also noch ein Storage Bucket und ein Notebook benötigt. Der geteilte Storage Bucket besteht bereits und muss daher nicht für jedes Notebook extra erstellt werden. Zusätzlich soll ein Skript im privaten Storage Bucket abgelegt werden, welches beim Starten des Notebooks den Linux-Benutzer ändert, über den das JupyterLab ausgeführt wird und es soll ein Beispieldatensatz in den Storage Bucket geladen werden. Fangen wir also als Erstes mit dem Storage Bucket an:
resource "google_storage_bucket" "private_bucket" {
name = "example-name-bucket"
location = "us-central1"
force_destroy = true
uniform_bucket_level_access = true
}
Hier wird als Ressource ein google_storage_bucket angelegt, der private_bucket genannt wird. Diese Benennung wird nur in Terraform verwendet. In der Google Cloud wird der Bucket dann nach dem angegebenen name benannt, in diesem Fall hier example-name-bucket. Da Storage Buckets unabhängig von der globalen Region und auch regionsübergreifend erstellt werden können, muss die Region hier als location nochmal explizit angegeben werden.
Der uniform_bucket_level_access ist die von Google empfohlene Zugriffsbeschränkung. Dabei werden Zugriffsrechte pro Bucket und nicht pro Datei vergeben. Die Rechte werden dann direkt über die Google-IAM-Richtlinien erstellt. Weitere Zugriffsrechte, wie z.B. über ACLs, auf Dateiebene sind dann aber nicht möglich.
Als Nächstes wird das bereits erwähnte Startup-Skript und ein Beispieldatensatz, in diesem Fall der Iris-Datensatz, in den erstellten Bucket geladen.
resource "google_storage_bucket_object" "iris_dataset" {
name = "iris"
source = "iris_csv.csv"
bucket = google_storage_bucket.private_bucket.name
depends_on = [
google_storage_bucket.private_bucket,
]
}
resource "google_storage_bucket_object" "startup_script" {
name = "configure_jupyter"
source = "configure_jupyter.sh"
bucket = google_storage_bucket.private_bucket.name
depends_on = [
google_storage_bucket.private_bucket,
]
}
Hier wird direkt auf die Ressource google_storage_bucket.private_bucket zugegriffen, wodurch Terraform den Namen des Buckets direkt lesen kann. Über das depends_on wird sichergestellt, dass der Storage Bucket bereits erstellt wurde. Wenn der Bucket nicht im depends_on eingetragen wäre, könnte es sein, dass Terraform die Dateien bereits hochlädt, bevor der Bucket in der Lage ist, die Dateien anzunehmen.
Als Letztes muss jetzt noch das eigentliche Notebook erstellt werden.
resource "google_notebooks_instance" "my_notebook" {
name = "terraform-notebook-test"
location = "us-central1-a"
machine_type = "n1-standard-1"
no_remove_data_disk = false
vm_image {
project = "deeplearning-platform-release"
image_family = "tf-latest-cpu"
}
metadata = {
ssh-keys = <<EOT
user1:${file("~/.ssh/id_ed25519.pub")}
EOT
}
post_startup_script = "gs://${google_storage_bucket.private_bucket.name}/${google_storage_ bucket_object.startup_script.name}"
}
Ein AI Platform Notebook wird standardmäßig mit einer Boot-Disk und einer Data-Disk erstellt. Da in unserem Anwendungsfall die Daten aber in einem Storage Bucket gespeichert werden, wird die Data-Disk hier nur für temporäre Daten benötigt und kann entsprechend gelöscht werden, wenn das Notebook an sich gelöscht wird. Dazu wird die Einstellung no_remove_data_disk auf false gesetzt.
Für ein AI Platform Notebook muss ein VM Image ausgewählt werden. Dies kann entweder ein selbst erstelltes Container Image oder ein Image der Deep-Learning-Platform sein. Wenn eigene Images verwendet werden sollen, sollte das eigene Image auf einem Deep-Learning-Common-Image basieren, da dort schon verschiedene von den AI Platform Notebooks benötigte Details vorkonfiguriert sind. Eine Übersicht über die möglichen Images gibt es hier.
In diesem Beispiel wird ein TensorFlow Image ohne GPU Unterstützung gewählt.
Zusätzlich zum Image wird hier ein SSH Key für den Benutzer user1 in den Metadaten hinterlegt. Wenn kein SSH-Zugang zur unterliegenden Compute-Engine-Instanz benötigt wird, kann der metadata-Block einfach weggelassen werden.
Als post_startup_script wird das Skript angegeben, welches in den privaten Storage Bucket geladen wurde. Dafür wird die gsutils URL in der Form gs://{bucket}/{file} aus den jeweiligen Attributen des Buckets und der Datei zusammengesetzt.
Mit der bisher gezeigten Konfiguration kann jetzt ein Storage Bucket aufgesetzt und mit Daten gefüllt werden. Zusätzlich wird eine AI-Platform-Notebook-Instanz erstellt, die auf einer konfigurierbaren Compute-Engine-Instanz basiert. Als Letztes soll Terraform jetzt noch die Proxy URL ausgeben, über die die JupyterLab-Instanz erreicht werden kann. Dazu wird der folgende Output Block verwendet:
output "proxy_url" {
description = "URL of the JupyterLab Proxy"
value = google_notebooks_instance.my_notebook.proxy_uri
depends_on = [
google_notebooks_instance.my_notebook
]
}
Auch hier wird wieder ein depends_on angegeben, wobei es an dieser Stelle eher weniger bringt, da Terraform in der Notebook API Drifts teilweise nicht erkennt. Von einem Drift spricht man im Terraform-Umfeld, wenn der tatsächliche Status der Infrastruktur nicht dem gespeicherten Status in Terraform entspricht. Der proxy_uri scheint ein Attribut zu sein, bei dem Drifts nicht erkannt werden. Beim ersten Ausführen wird als URL also nichts angezeigt, mit dem Command terraformrefresh lässt sich der gespeicherte Zustand aber aktualisieren und zeigt dann auch entsprechend die Proxy URL als Output an.
Die Terraform-Datei ist damit erstmal fertig. Vor dem ersten Ausführen (oder wenn sich z.B. Provider-Informationen ändern) muss der Befehl terraforminit ausgeführt werden. terraforminit installiert u.a. die entsprechenden Provider-Plugins aus der Terraform Registry und erstellt grundsätzliche Ordnerstrukturen.
Zum Starten der Infrastruktur kann jetzt das Command terraformapply verwendet werden. Mit terraformdestroy wird die Infrastruktur wieder entfernt. Zu beachten ist, dass beide Befehle interaktiv sind und Nutzereingaben benötigen. Im einfachsten Fall muss lediglich bestätigt werden, dass Infrastruktur erstellt oder zerstört werden soll, wenn Variablen verwendet und nicht ausgefüllt werden, werden diese interaktiv abgefragt. Dieses Verhalten kann mit -auto-approve und -input=false geändert werden. Wenn die Infrastruktur vollautomatisiert, z.B. über eine CI-Pipeline, erstellt werden soll, müssen die Befehle entsprechend angepasst werden.
Fazit
Der gezeigte Aufbau einer Data Science Workbench ist relativ einfach gehalten. Es wird lediglich ein JupyterLab mit Cloud-Storage-Anbindung in der Google Cloud erstellt, da dies für unseren Anwendungsfall genau das Richtige ist. Dadurch ist der Konfigurationsaufwand in Terraform eher gering. Das Ganze gibt trotzdem eine gute Übersicht über die Möglichkeiten von automatisierter Data-Science-Infrastruktur mit Terraform. Die gezeigte Terraform-Konfiguration stellt hier nur ein Beispiel dar. Für einen produktiven Einsatz müsste die Konfiguration mindestens um verschiedene Variablen, z.B. für Benutzer, Region, Zone, Maschinentyp und VM-Image, erweitert werden.
Die AI-Platform (oder auch Vertex-AI) in der Google Cloud bietet einfache Tools für Data Scientisten, wie z.B. die verwalteten JupyterLab-Instanzen in Form der AI Platform Notebooks. Ein richtiger „Cloud-Native"-Ansatz würde aber anstelle der Notebooks die einzelnen Komponenten der Vertex-AI Plattform verwenden.
Eine "plattformunabhängige" Infrastruktur kann an der Stelle mit Terraform natürlich nicht aufgebaut werden, beim Wechsel des Cloud Providers ist es aber mit Terraform deutlich einfacher, als wenn explizite Skripte zum Erstellen von Infrastruktur für jeden Cloud Provider geschrieben werden müssten.
Zu beachten ist noch, dass die Quotas in der Google Cloud gerade für Grafikkarten ziemlich begrenzt sind. Wenn auf GPUs verzichtet werden kann, sollte dies tunlichst gemacht werden. Alternativ könnte auch eine geteilte Notebook-Instanz mit GPU erstellt werden, die von allen Anwendern verwendet wird, wenn eine GPU benötigt wird.
Sie haben Interesse an einer Weiterbildung oder Fragen zum Thema Cloud Computing? Sprechen Sie uns an oder besuchen Sie einen unserer Kurse aus unserem Seminarshop:
Zu unserem Cloud-Computing-Seminar
Junior Consultant bei ORDIX
Kommentare