
Datenmigration nach Exasol – Welche Migrationsmöglichkeiten gibt es? – Teil 2: ETL-Tools
Im ersten Teil dieser Blogartikel-Reihe wurde bereits gezeigt, wie mithilfe der in Exasol integrierten Import-Statements Datenmigrationen durchgeführt werden können. Der zweite Teil stellt vor, wie Sie ihre Daten über ETL-Tools in eine Exasol-Datenbank laden können.
Ausgangssituation
In unserem Beispiel liegen Daten in unterschiedlichen Quellen, die nach Exasol überführt werden sollen. Dazu gehören lokale CSV-Dateien, Daten in einer PostgreSQL-Datenbank und Daten aus einer Hadoop-Umgebung. In der Hadoop-Umgebung liegen die Daten in verschiedenen Dateiformaten im HDFS vor. Möchten Sie selbst einige Migrationsmöglichkeiten ausprobieren, können Sie sich die kostenlose Exasol-Community-Edition von hier herunterladen.
Warum ETL?
ETL steht für Extract, Transform, Load. Es beschreibt einen dreistufigen Prozess. Im ersten Schritt werden Daten aus verschiedenen Quellen entnommen. Anschließend werden in einem zweiten Schritt die Daten aufbereitet, sodass sie in der passenden Form für das Zielsystem vorliegen. Zuletzt werden sie im Zielsystem bereitgestellt. Dieses Vorgehen hilft dabei, verschiedenste Datenquellen in einem Zielsystem zusammenzuführen. Außerdem eignet sich dieses Verfahren, um große Datenmengen zu verarbeiten, da viele ETL-Tools darauf ausgelegt sind, im Cluster zu arbeiten, um Last zu parallelisieren. Exasol lässt sich mit verschiedensten ETL-Tools integrieren (siehe hier). Im Folgenden wird die Datenmigration am Beispiel von Apache NiFi und Talend Open Studio for Data Integration bzw. Open Studio for Big Data vorgestellt.
Datenmigration mit Apache NiFi
Apache NiFi ist ein Open-Source-Tool zur Automatisierung des Datenflusses zwischen Systemen. Es bietet eine webbasierte Benutzeroberfläche, in der sich einfach und schnell DataFlows per „Drag and Drop" erstellen lassen. Der Fokus von NiFi liegt in der schnellen Verteilung beliebiger Daten. Es werden aber auch viele Prozessoren zur Datentransformation bereitgestellt.
Der erste Schritt der Datenmigration ist die Konvertierung des Datenbankschemas. Exasol stellt Skripte bereit, die für die Generierung der DDL-Statements genutzt werden können (siehe hier). Diese Statements können in ein DDL-Skript eingebaut werden, welches mit dem ExecuteScript-Prozessor ausgeführt werden kann. Einfacher ist es, die Tabellen über eine direkte Datenbankverbindung in der Zieldatenbank anzulegen.
Als Nächstes kann der DataFlow gebaut werden. Dazu müssen zunächst zwei DBCPConnectionPool-Controller-Services angelegt werden, damit Verbindungen zu den Datenbanken hergestellt werden können. Zum Anlegen der Services werden verschiedene Parameter wie ein JDBC-Treiber, eine Verbindungs-URL oder der Datenbankbenutzer benötigt. Anschließend kann mit den geeigneten Prozessoren ein DataFlow zur Datenmigration erstellt werden:
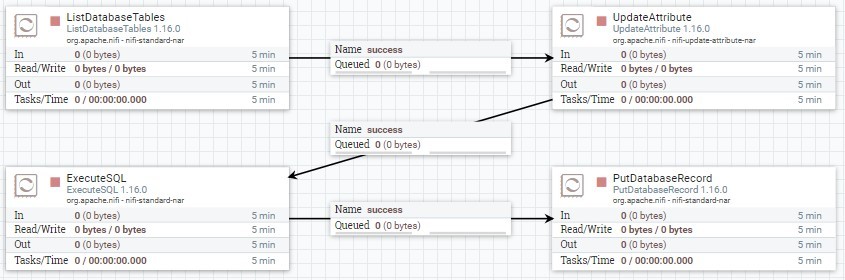
Zuerst werden mit dem ListDatabaseTables-Prozessor die zu migrierenden Tabellen aus der Quelldatenbank gefiltert. Die Tabellen werden als sogenannte FlowFiles, welche die um weitere Attribute ergänzten Daten enthalten, an den UpdateAttribute-Prozessor weitergereicht. Dieser kann die FlowFile-Attribute bearbeiten. So kann dem FlowFile beispielsweise das Schema der Zieldatenbank hinzugefügt werden. Anschließend führt der ExecuteSQL-Prozessor SELECT-Statements auf die zu migrierenden Tabelle aus. Die abgefragten Daten werden zuletzt per INSERT-Statement mit einem PutDatabaseRecord-Prozessor in die Zieldatenbank migriert. In diesem Prozessor lässt sich auch das Importverhalten anhand verschiedener Parameter konfigurieren. So lässt sich beispielsweise mit „Translate Field Names“ einstellen, dass ähnliche Spaltennamen der Quell- und Zieldaten übersetzt werden und nicht zu einem Fehler führen.
Auch zur Migration von Daten aus dem HDFS einer Hadoop-Umgebung ist NiFi geeignet. Mit entsprechenden Prozessoren wie ListHDFS oder FetchHDFS können ähnliche DataFlows zusammengestellt werden.
Datenmigration mit „Talend Open Studio"
Talend bietet sowohl Lizenz- als auch Open-Source-Versionen seiner Produkte an. Die Open-Source-Produkte erscheinen mit dem Namenszusatz „Open Studio“. Für den Anwendungsfall der PostgreSQL-Migration wird das „Talend-Open-Studio for Data Integration“ benötigt. Zur Migration von Daten aus Hadoop wird das „Talend-Open-Studio for Big Data“ eingesetzt. Auch diese beiden Produkte lassen sich über eine grafische Benutzeroberfläche bedienen, mit der sich einzelne Komponenten via „Drag and Drop“ zu einem Job zusammenstellen lassen. Es wird eine Vielzahl an Komponenten bereitgestellt, durch die auch komplexe Transformationen ermöglicht werden.
Nachdem die Datenmigration von PostgreSQL nach Exasol bereits via NiFi durchgeführt wurde, sollen nun Daten aus dem HDFS mittels „Talend Open Studio for Big Data“ migriert werden. Dazu empfiehlt es sich, die Exasol- und Hadoop-HDFS-Verbindungen in den Meta-Daten zu spezifizieren. Somit können sie in weiteren Jobs einfach wiederverwendet werden.
Die Handhabung der Tabellenschemata in „Talend Open Studio“ unterscheidet sich zu NiFi. Während in NiFi die Möglichkeit besteht, Tabellenschemata dynamisch zu lesen, ohne sie explizit anzugeben, muss in den kostenlosen Versionen von Talend in jedem Fall ein Schema angegeben werden. Dies hat leider zur Folge, dass nur einzelne Tabellen/Dateien migriert werden können. Somit ergibt sich zur Migration einer Datei aus dem HDFS folgender Job:

Mit einer tHDFSInput-Komponente wird eine Datei aus dem HDFS ausgelesen. Dazu müssen die Verbindung, der Dateipfad und das Schema angegeben werden. Eine tDBOutput-Komponente fügt die Daten in die Zieldatenbank ein. Auch hierzu müssen eine Verbindung, ein Schema und zusätzlich die Zieltabelle angegeben werden. Die Komponente bietet darüber hinaus die Möglichkeit, die Zieltabelle mittels CREATE-Statements zu erstellen, sodass zuvor keine Schemakonvertierung notwendig ist. Eine Einschränkung für die Migration aus dem HDFS stellt die geringe Anzahl unterstützter Datentypen dar. So werden in der Open Studio-Version zum Beispiel keine Komponenten für Avro- oder Parquet-Dateiformate bereitgestellt, die in Hadoop-Umgebungen nicht unüblich sind.
Liegen die zu migrierenden Daten nicht im HDFS, sondern in einer Quelldatenbank wie PostgreSQL, stellt Ihnen das „Talend Open Studio for Data Integration“ die passenden Komponenten zur Verfügung. Mit einer tDBInput-Komponente können die Daten einer entsprechenden Verbindung extrahiert und wieder mit der tDBOutput-Komponente in Exasol eingefügt werden.
Fazit
Mit den Streaming- bzw. ETL-Tools Apache NiFi und „Talend Open Studio for Data Integration/Big Data“ lassen sich Datenmigrationen nach Exasol relativ schnell über grafische Oberflächen umsetzen. Verfolgen Sie „nur“ das Ziel, Daten von einer Quelle nach Exasol zu migrieren, empfiehlt es sich, die Möglichkeiten der Exasol-Import-Statements zu verwenden, wie in Teil 1 dieser Blogreihe beschrieben. Wenn Ihre Anforderungen auch Transformationen von Daten umfassen und/oder Sie Daten aus vielen verschiedenen Quellen migrieren wollen, können ETL-Tools vorteilhaft sein. Falls die vorgefertigten Prozessoren/Komponenten nicht ausreichende Funktionalitäten für Ihren Anwendungsfall bereitstellen, soll an dieser Stelle noch auf die Möglichkeit hingewiesen werden, eigene UDF-Skripte in Exasol zu schreiben. Nähere Information dazu finden Sie hier.
Seminarempfehlungen
APACHE NIFI GRUNDLAGEN - KOSTENLOSES WEBINAR W-NIFI-01
Zum SeminarAPACHE NIFI GRUNDLAGEN DB-BIG-07
Zum SeminarTALEND - EINE EINFÜHRUNG IN DAS GRAFISCHE ETL-TOOL - KOSTENLOSES WEBINAR W-TALEND-1
Zum SeminarJunior Consultant bie ORDIX
Kommentare