
Die Stackable Data Platform: Deployments in die Cloud mit nur einem Befehl.
Im Rahmen meiner Praxisphase habe ich mich intensiv mit Themen rund um Big Data-Infrastrukturen und verschiedenen Datenplattformen auseinandergesetzt. Der Schwerpunkt lag dabei auf dem Aufbau, dem Testen und der Evaluierung der Stackable Data Platform: Einer lizenzfreien Open-Source-Lösung.
Es gibt nicht nur die großen Player
Das Verwenden verschiedener Hadoop-Distributionen ist oft mit hohen Lizenzkosten verbunden, was gerade für Projekte mit begrenztem Budget eine Herausforderung darstellt. Alternativ bleibt die Möglichkeit, eine native Hadoop-Umgebung eigenständig aufzusetzen. Allerdings ist dieser Ansatz mit erheblichem Aufwand verbunden. Die Kompatibilität der einzelnen Komponenten muss gewährleistet sein und der Support für die Plattform muss selbst geleistet werden. Entwickler sehen sich daher oft in einem Dilemma zwischen einem hohen Arbeitsaufwand oder hohen Lizenzkosten.
Im Juni 2022 veröffentlichte das in Europa ansässige Unternehmen Stackable ihre eigene Hadoop-Distribution. Die Stackable Data Platform (SDP) zeichnet sich durch eine Open-Source-Lizenz aus und bietet zudem optionale Support-Angebote, welche individuell mit Stackable vereinbart werden können.
Die SDP basiert auf Kubernetes, um die einzelnen Komponenten der Datenplattform aufzusetzen und zu verwalten. Dadurch wird nicht nur ein Deployment der Plattform in der Cloud ermöglicht, sondern auch eine gute Skalierbarkeit.
Die Stackable Data Platform
Die SDP nutzt das Operator Pattern von Kubernetes, um einzelne Komponenten auf einem Kubernetes Cluster aufzusetzen und zu verwalten. Aktuell stehen folgende Big Data-Komponenten zur Verfügung:
- Apache Kafka
- Apache Spark
- Hadoop Distributed File System
- Apache Hive Metastore
- Apache Superset
- Apache NiFi
- Apache ZooKeeper
- Apache Airflow
- Apache Druid
- Apache HBase
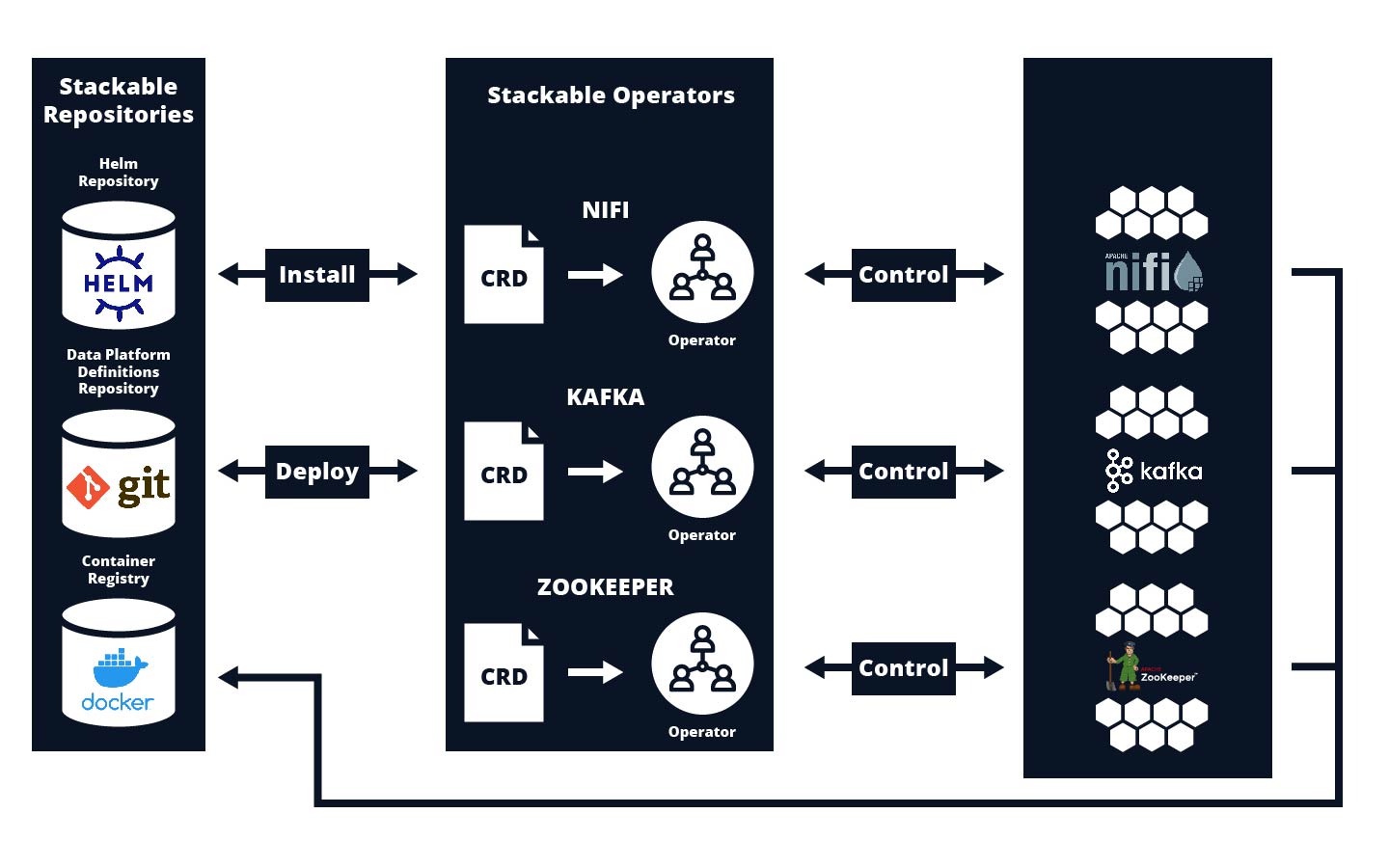
Die Installation der verschiedenen Komponenten kann über verschiedene Methoden erfolgen, darunter Container Images, Helm Charts, das Github Repository oder mithilfe des von Stackable entwickelten Commandline-Tools [2], „stackablectl“. Instanzen der jeweiligen Operatoren können anschließend mithilfe von Kubernetes-typischen YAML-Dateien konfiguriert und aufgesetzt werden.
Ein weiterer Vorteil der SDP liegt in der Aktualität der angebotenen Komponenten. Die Versionen von Komponenten wie Apache Spark oder Kafka sind im Vergleich zu anderen Datenplattformen wesentlich aktueller.
Zu schön, um wahr zu sein? Es gibt noch mehr!
Die SDP zeichnet sich zusätzlich durch ihre einfache Einrichtung aus. Wie bereits erwähnt, besteht die Möglichkeit, die Plattform durch die Installation einzelner Operatoren und dem Schreiben von Konfigurationsdateien einzurichten. Allerdings bietet Stackable auch die Nutzung von sogenannten „Stacks“ an. Diese ermöglichen es, ganze Datenplattformen mit nur einem Befehl einzurichten, was die Inbetriebnahme und den Betrieb erheblich vereinfacht.
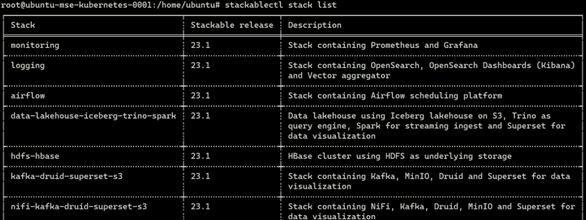
Stacks [3] sind vorkonfigurierte Definitionen einer Datenplattform von Stackable, die mithilfe des Commandline-Tools „stackablectl“ schnell und einfach hochgefahren werden können. Eine Liste der verschiedenen verfügbaren Stacks lässt sich wie folgt anzeigen:
$ stackablectl stack list
Für das folgende Beispiel wird der Stack „kafka-druid-superset-s3“ mit Monitoring aufgebaut. Dazu sind die folgenden Befehle erforderlich:
$ stackablectl stack install monitoring
$ stackablectl stack install kafka-druid-superset-s3
Nach Ausführung dieser Befehle werden die benötigten Stackable-Operatoren installiert und vorkonfigurierte Instanzen dieser Operatoren initialisiert und gestartet.
Nach einer kurzen Wartezeit lässt sich eine Auflistung der verfügbaren Komponenten folgendermaßen anzeigen:
$ stackablectl svc list
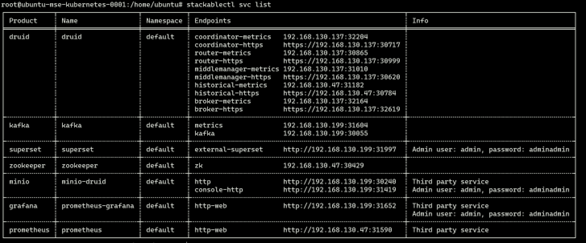
Die aufgelisteten Komponenten sind über die entsprechenden Endpunkte erreichbar. Damit stehen die gewünschten Services der Stackable Data Platform einsatzbereit zur Verfügung.
Fazit
Die Stackable Data Platform ist eine kostengünstige Alternative zu bestehenden Hadoop-Distributionen. Zwar wird nicht die gleiche Breite an Komponenten angeboten, wie bei anderen Datenplattformen, jedoch ist die Menge an angebotenen Komponenten für viele Anwendungsfälle völlig ausreichend. Dies macht Stackable insbesondere für Projekte mit beschränktem Budget interessant.
Natürlich ist die SDP durchaus komplexer als in diesem Blogartikel dargestellt. Stackable bietet beispielsweise mehrere Möglichkeiten den Cluster und die einzelnen Komponenten abzusichern (LDAP, Open Policy Agent, etc.). Außerdem bietet Stackable verschiedene Qualitätssicherungsmaßnahmen, wie beispielsweise ein Loggingsystem mit OpenSearch-Dashboards an. Die verschiedenen Komponenten besitzen für spezifische Anwendungsfälle zahlreiche Konfigurationsparameter, welche mitgegeben werden können. Des Weiteren wird die SDP ständig weiterentwickelt. Erst im Juli 2023 wurde ein neues Release mit neuen Features, wie Pod Overrides und OpenShift-Zertifizierungen veröffentlicht.
Für weitere Informationen und umfangreichere Einblicke in die Stackable Data Platform stehen die Demos [4] von Stackable zur Verfügung. Diese Demos beinhalten eine Reihe von vorkonfigurierten Datenplattformen, die mit Testdaten befüllt sind und einen praxisnahen Eindruck der Möglichkeiten der Plattform vermitteln.
Links
[1] https://stackable.tech/en/platform/
[2] https://docs.stackable.tech/stackablectl/stable/installation.html
[3] https://docs.stackable.tech/stackablectl/stable/commands/stack.html
Seminarempfehlungen
HADOOP GRUNDLAGEN HADOOP-01
ZUM SEMINARHADOOP ADMINISTRATION HADOOP-02
ZUM SEMINARKUBERNETES ESSENTIALS KUB-01
ZUM SEMINARJunior Consultant bei ORDIX
Kommentare