
Einfaches Workflow Scheduling via Apache Airflow – ein Usecase aus dem Data Science Umfeld
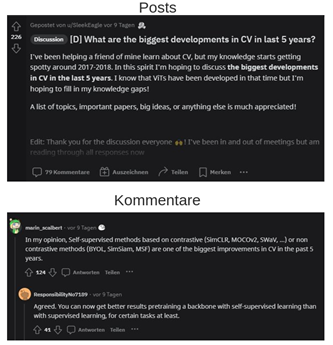
Im vorangegangenen Blogartikel haben wir Ihnen die Grundlagen der Workflow-Management-Plattform Apache Airflow vorgestellt. In diesem Artikel gehen wir detaillierter auf das Workflow-Scheduling ein und stellen es anhand eines Use Cases aus dem Text- und Webmining Bereich vor. Kernidee des Use Cases ist es, aktuell diskutierte Themen und Trends aus dem Data Science Umfeld des Online Forums Reddit abzuleiten. Dabei werden verschiedene Subreddits, wie beispielsweise Data Science und Machine Learning, gecrawlt und Analysen mit diesen Daten durchgeführt. Die Daten sind dabei wie folgt strukturiert: Zu einem Post können beliebig viele Kommentare und Subkommentare existieren. Einen exemplarischen Post aus dem Bereich "Computer Vision" und die dazugehörigen Kommentare können Sie Abbildung 1 entnehmen. Des Weiteren ermöglichen Metadaten, wie die Anzahl der Kommentare, Postfrequenz und das Upvote zu Downvote Verhältnis, die Evaluation von Datenqualität bzw. der Relevanz eines Beitrags.
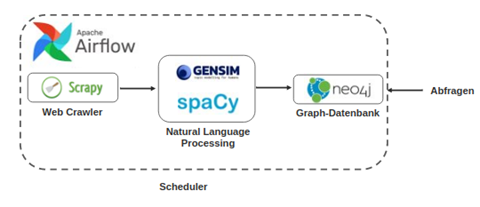
Eine Skizzierung des Ablaufs des Anwendungsbeispiels ist in Abbildung 2 dargestellt. Dabei werden zu Beginn Text- und Metadaten durch einen Webcrawler gesammelt. Der Webcrawler selbst wurde hierbei unter Verwendung des Python-Frameworks Scrapy entwickelt. Die aus dem Web extrahierten Textdaten werden im darauffolgenden Schritt mittels Natural Language Processing weiterverarbeitet. Dieses Pre-Processing wird zunächst mittels spaCy durchgeführt. Anschließend werden die Textdaten durch ein Topic Model, welches unter Verwendung von Gensim generiert wurde, bewertet, sodass den einzelnen Textdaten unterschiedliche Kategorien zugeordnet werden.
Die so vorverarbeiteten und angereicherten Daten werden schließlich in einer Neo4j Graph-Datenbank persistiert. Für den skizzierten Use Case eignet sich die Neo4j-Datenbank aus den folgenden Gründen gut als "Speichermedium": Zum einen bietet die Graph-Datenbank selbst eigene NLP-Funktionalitäten an. Zum anderen können unstrukturierte Textdaten effizient durchsucht werden. Folglich stellt das Datenbanksystem selbst ein hilfreiches Werkzeug bei der "Data Discovery" dar. Anschließend können verschiedene Abfragen auf die Daten durchgeführt werden und als Grundlage für weitere Analysen dienen.
Der gesamte beschriebene Prozess soll dabei zyklisch durchlaufen werden, sodass die Datenbestände in der Neo4j-Datenbank stetig erweitert werden, um nicht an Aktualität zu verlieren. An dieser Stelle kommt Apache Airflow als Workflow Scheduler ins Spiel, welcher den beschriebenen Workflow automatisiert in einem definierten Zeitintervall wiederholen soll. Da der gesamte Use Case auf Python basiert, eignet sich Airflow besonders gut. Denn auch hier werden Workflows in sogenannten Directed Acyclic Graphs (DAGs) mittels der Programmiersprache Python definiert. Falls Ihnen der Begriff DAG noch unbekannt ist, schauen Sie gerne noch einmal in unseren vorherigen Blogartikel zu Apache Airflow.
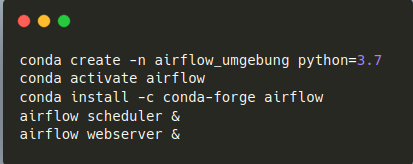
In unserem Use Case sind wir nach dem KISS-Prinzip ("keep it simple and stupid") vorgegangen. Dementsprechend wurde das Airflow-Setup so einfach wie möglich gestaltet. Die Installation erfolgte direkt in unserer virtuellen Conda-Umgebung. Anschließend erfolgte der Start des Airflow-Schedulers und des Webservers manuell.
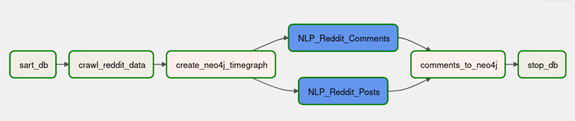
Webansicht des Workflows:
Damit der Workflow automatisiert ablaufen kann, müssen die einzelnen Schritte in einem DAG, unter Berücksichtigung der verschiedenen Abhängigkeiten, zusammengeführt werden. Wie der für unser Projekt ausgearbeitete DAG in der Airflow Webserver Ansicht aussieht, ist anhand der Abbildung 4 zu erkennen. Dabei gilt als Best Practice, dass Tasks möglichst atomar, also pro Task ein Arbeitsschritt, definiert werden. Unser DAG besteht demnach aus den folgenden Komponenten (Tasks):
1. `start_db` - Start der Neo4j Datenbank
2. `crawl_reddit_data` - Crawlen der Rohdaten
3. ` create_neo4j_timegraph` - Generierung eines Zeitgrafen in der Datenbank, welcher später mit den Reddit Post- und Kommentar-Daten versehen wird.
4. Blau hinterlegte Task-Gruppen:
A. `NLP_Reddit_Posts` - Gliederung von zusammengehörigen Tasks, die das Processing der Post-Textdaten und deren Persistenz in der Graph-Datenbank betreffen.
B. `NLP_Reddit_Comments`- Analog zu 4A werden Tasks, welche das Pre-Processing der Kommentar-Textdaten betreffen, in eine Task-Gruppe zusammengefügt.
5. `Comments_to_neo4j`- Persistieren der Kommentare in Abhängigkeit zu den bereits erstellten Post-Knoten in der Graph-Datenbank.
6. `stop_db`- Stoppen der Datenbank
Die Task-Gruppen helfen maßgeblich den Workflow-Graph übersichtlicher zu gestalten. Diese sogenannten Taskgroups sind dabei ausschließlich ein Gruppierungskonzept im Userinterface des Webservers. Eine Verwendung dieser Abhängigkeitsgruppierungen gilt als eine „Good Practice“.
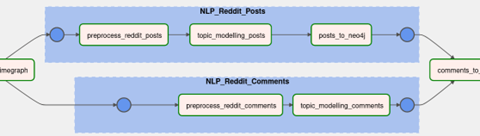
Abbildung 5 zeigt, welche Tasks sich in den jeweiligen Gruppen befinden. Weiterhin fällt auf, dass die jeweiligen Task-Gruppen unabhängig voneinander bearbeitet werden können. Dies eröffnet die Möglichkeit, eine Parallelisierung von Aufgaben vorzunehmen. Da die Kommentare in Abhängigkeit zu den Posts im Graphen hinzugefügt werden, stellt `comments_to_neo4j`den vorletzten Schritt dar. Abschließend wird die Datenbank gestoppt. Bevor wir uns mit dem zum DAG zugehörigen Code beschäftigen, noch ein kurzer Ausflug in die Fehlermittlung von Workflows:
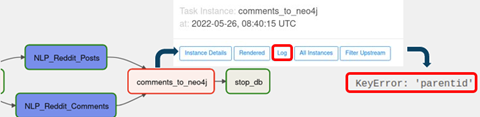
In der Webansicht werden die Status, durch eine farbliche Umrandung der einzelnen Tasks, visuell hervorgehoben. Im obenstehenden Fall sind alle Tasks des Workflows mit einem "success" gekennzeichnet worden. Diese Ansicht ist äußerst hilfreich, um sich Workflow Abhängigkeiten vor Augen zu führen und um aufgetretene Komplikationen spezifischen Tasks zuzuordnen und zu beheben. Falls ein Task fehlerhaft war, kann die Ursache direkt im Log des jeweiligen Tasks über die Weboberfläche nachvollzogen werden. Als Beispiel wurde ein Fehler in der Codebasis der Task "comments_to_neo4j" eingeführt. Dieses Problem könnte exemplarisch bei einer Codewartung / -anpassung entstanden sein. Abbildung 6 führt vor Augen, wie man effizient den Fehler ermitteln kann, indem man auf den Task klickt, in dem erscheinenden Menü das Log auswählt und dort die Fehlermeldung betrachtet. In unserem Beispiel kann so ein „KeyError“ detektiert werden, welcher die Zuordnung von Kommentar und zugehörigen Post verhindert. Somit können Fehler im Workflow direkt auf einen Task zurückgeführt werden, was die Wartbarkeit und Problemanalyse von Workflows deutlich erleichtert.
Nun haben wir die Struktur des DAGs kennengelernt. Als Nächstes schauen wir uns interessante Code-Ausschnitte aus der DAG-Definition an.
Code des DAGs:
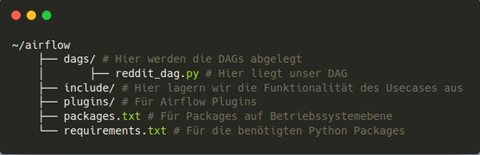
Der DAG selbst wird in einem Python-Skript definiert. Der Abbildung 7 kann eine empfohlene Organisation für das Dateisystem entnommen werden. Diese grundlegende Struktur wird von Airflow selbst angelegt. Hervorzuheben ist die Auslagerung der Funktionalität in den Include-Ordner. Alle Funktionen, welche zur Umsetzung des Workflows programmiert wurden, werden innerhalb des reddit_dag.py-Skriptes importiert. Demnach werden lediglich die Abhängigkeiten zwischen den einzelnen Arbeitsschritten im DAG-Skript definiert, sodass die Wartbarkeit und Lesbarkeit des DAG-Files erhöht wird.
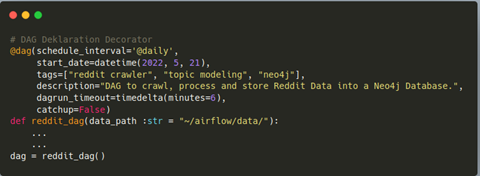
Seit Airflow 2.0 kann der DAG selbst mittels DAG-Decorator definiert werden. In Abbildung 8 wird die DAG-Deklaration unseres Workflows dargestellt. Wie man sieht, wirkt die neue Deklaration sauberer und übersichtlicher. Als Argument haben wir dem DAG ein tägliches Schedule-Intervall übergeben, wobei Airflow, eine im Vergleich zu CRON, wesentlich lesbarere Intervallangabe ermöglicht. Dennoch ist die altbekannte Cron-Schreibweise möglich. Weiterhin wird das initiale Startdatum im "start_date" Parameter angegeben. Tags und Beschreibung, welche in der Webserver Ansicht angezeigt werden, können hier ebenfalls spezifiziert werden. Das "dagrun_timeout" Argument spezifiziert, wie lange ein "DagRun" aktiv sein soll. Da wir das Catchup Argument auf "False" gesetzt haben, wird kein Backfilling durchgeführt. Fehlerhafte DagRuns werden so nicht zu einem anderen Zeitpunkt wiederholt. Der DAG-Funktion können anschließend Parameter übergeben werden, welche dann in allen Tasks erreichbar sind. Wir haben hier den Pfad, in dem Daten zwischengespeichert werden sollen, festgelegt. Im DAG-File muss die DAG-Funktion aufgerufen werden und als Top-Level Object vorliegen (siehe Snippet in Abbildung 8).
Innerhalb der DAG-Funktion können nun die einzelnen Tasks definiert werden. Die Tasks selbst basieren dabei auf verschiedenen Operatoren. Es stehen zahlreiche Built-in Operatoren zur Verfügung, welche sich durch „community provider packages“ erweitern lassen. Für unsere Zwecke genügen dieser - sowie der Pythonoperator. Wir nutzen bei den Pythonoperatoren die neue Taskflow-API, welche seit Airflow 2.0 zur Verfügung steht.
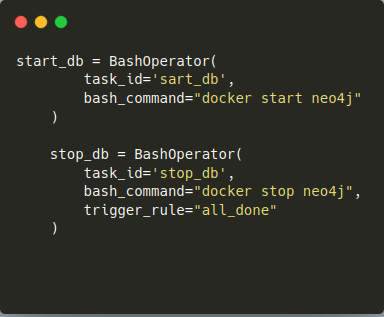
Der Bashoperator wurde zum Starten und Stoppen der Neo4j Datenbank verwendet, diese Operatoren wurden gem. Abbildung 9 definiert. Es wurden lediglich Parameter zur Definition der TaskID und des auszuführenden Bash-Befehls übergeben. Wie im Bash-Befehl ersichtlich, wird somit der Docker-Container "neo4j" gestartet bzw. gestoppt. Zusätzlich wurde im "stop_db task" die Default Trigger Rule mit dem Argument "all_done" überschrieben. Dadurch wird die Datenbank, unabhängig davon, ob alle vorherigen Tasks erfolgreich waren oder nicht, heruntergefahren.
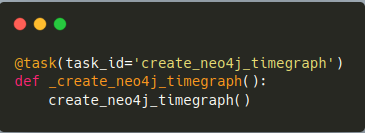
Sämtliche anderen Tasks wurden mittels der Taskflow API definiert. Die Taskflow API ist dabei, eine neue Art Pythonoperatoren mittels Task-Decorator zu definieren, wie in Abbildung 10 zu sehen ist. Diese Art der Operator Definition ermöglicht eine elegante Kommunikation zwischen den einzelnen Tasks. Daten können damit über ein einfaches Return-Statement an andere Tasks weitergegeben werden. Auch wenn diese Art der Kommunikation zwischen Tasks in unserem Use Case nicht notwendig war, wirkt die Taskflow-API wesentlich lesbarer, als die traditionelle Definition (Siehe Bashoperator). Da zurzeit leider nur Pythonoperatoren mittels TaskFlow-API definiert werden können, ist es umständlich die Kommunikation zwischen der alten und neuen Weise umzusetzen.
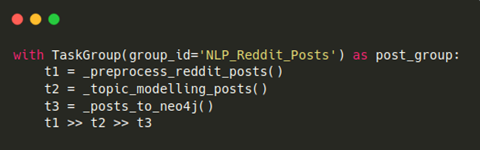
Wie bereits erwähnt, können Task-Gruppen verwendet werden, sodass zusammengehörende Tasks in Gruppen gegliedert werden. Damit ist es möglich, längere DAGs wesentlich übersichtlicher zu gestalten. Abbildung 11 zeigt, wie dabei die Taskgroup für die NLP-Berarbeitungsschritte der Reddit Posts implementiert wurde. Mit der Kontextmanager-Schreibweise wird eine Task-Gruppe eröffnet und mit einer geeigneten GruppenID versehen. Dort werden die einzelnen Tasks Objekten zugeordnet und aufgerufen. Letztlich werden die Abhängigkeiten mit dem überladenen Bitwise-Vergleichsoperator `>>` beschrieben. So wird erst Task1, dann Task2 und abschließend Task3 ausgeführt.
Abschließend werden alle Abhängigkeiten inklusive der Task-Gruppen definiert, wie in der nächsten Abbildung zu sehen ist. Mit den eckigen Klammern wird definiert, dass die Post-Gruppe und Comment-Gruppe nebenläufig abgearbeitet werden können.

Fazit:
Mittels Apache Airflow lassen sich Workflows elegant schedulen, monitoren und automatisieren. Die programmatische Art und Weise der Definition ist dabei unkompliziert und übersichtlich. Die in Airflow 2.0 neu eingeführten Decorator überzeugen durch eine saubere Definition von DAGs und Tasks. Wünschenswert wäre eine Erleichterung der Kommunikation zwischen den traditionellen Tasks und den neuen Taskflow-API-Tasks. Zudem bieten die zahlreichen Operatoren für fast jeden Verwendungszweck die passende Auswahl. Über die Webansicht behält man stets einen Überblick über alle Workflows. Aufgetretene Probleme können dort leicht identifiziert werden. Vor allem die Möglichkeit, in die Logfiles der einzelnen Tasks zu schauen, ist dabei sehr hilfreich. Auch das einfache Setup zum Testen von Apache Airflow bietet einen leichten Einstieg in die Workflow-Scheduling-Plattform. Eine Vereinfachung könnte die Erweiterung des Setups mittels Docker Container darstellen, wobei man das Docker Image in der Cloud hosten könnte. Falls noch nicht geschehen, können Sie grundlegende Informationen zu Apache Airflow in diesem Blogartikel nachlesen.
Kommentare