
ELT vs. ETL in der Cloud (2/2): Azure Data Factory v2 und zu erwartende Kosten
Als ETL-Werkzeug in der Azure Cloud bietet die Azure Data Factory v2 eine Reihe von Features, die klassischen ELT-Ansätzen fehlen, wie z. B. die Einbindung von weiteren Cloud-Diensten, die Flexibilität hinsichtlich der Ausführung auf eigener Hardware oder auf Azure Clustern oder die Einsicht in Metadaten zu den Ausführungen von Pipelines. Dass die Nutzung dieser Funktionalitäten Kosten verursacht, ist selbstredend. Dieser Blogartikel soll eine Übersicht über potenziell anfallende Kosten sowie damit verbundenen möglichen Nebeneffekten geben. Im ersten Teil „ELT vs. ETL in der Cloud (1/2): Datentransformation mit Azure Data Factory v2“ berichteten wir bereits über die Beladung eines Data Warehouses.
Kostenmodell der Azure Data Factory v2
Generell berechnet Microsoft einen geringen Fixbetrag für das Ausführen einer Aktivität. Hinzu kommen jedoch Kosten, basierend auf der Laufzeit. Da für verschiedene Aktivitäten unterschiedliche Raten berechnet werden können, kann die Prognose der zu erwartenden Kosten aufwändig werden. Hinzu kommt, dass Microsoft die Raten regelmäßig anpasst. Die folgend verwendeten Preise entsprechen dem Stand vom 25.05.2024.
- Orchestrationen: Jede einzelne ausgeführte Aktivität, unabhängig von Ausführungsdauer, kostet knapp einen Zehntel Cent (0,9363 € pro 1000 Aktivitäten).
- Daten-Bewegung: Bei einer Kopieraktivität werden eine variable Anzahl an Data Integration Units (DIUs) eingesetzt. Die Kosten basieren auf der akkumulierten Laufzeit, mit 0,235 € pro DIU-Stunde, sowie einem Aufschlag, wenn Daten aus der Azure Cloud herauskopiert werden. Achtung: Laufzeiten werden auf die nächste volle Minute aufgerundet. Bei vielen kleinen Kopiervorgängen (z.B. von REST-Schnittstellen) können Kosten daher schneller ansteigen als erwartet.
- Pipeline-Aktivitäten: Pipeline-Aktivitäten (z.B. Lookup, Skript, GetMetadata) werden in der Regel auf einer Integration Runtime ausgeführt. Der Preis dafür liegt bei 0,005 € pro Stunde, allerdings wird auch hier auf die nächste volle Minute aufgerundet.
- Externe Pipeline Aktivitäten: Alle Aktivitäten, die lediglich andere Azure Dienste starten, verursachen zwar theoretisch auch laufende Kosten, allerdings sind diese mit einer Höhe von 0,000235 € pro Stunde eher zu vernachlässigen, da die tatsächlich genutzte Rechenleistung von den ausgeführten Diensten separat in Rechnung gestellt wird.
- Datenflüsse: Ähnlich der Kopieraktivität entstehen bei Datenflüssen Kosten basierend auf der akkumulierten Laufzeit aller Kerne im definierten Rechencluster. Unterschieden wird zwischen General-Purpose-Clustern für 0,25 € pro vCore-Stunde und Speicher-Optimierten-Clustern für 0,312 € pro vCore-Stunde. Ein Cluster kann zwischen 8 und 272 Kerne besitzen.
Wichtig hier: Auch der Debug-Modus von Datenflüssen startet ein Cluster, dessen Laufzeit Kosten verursacht. Das Beispiel hier berechnet über einen acht-stündigen Arbeitstag Kosten bis zu 12,35 $ oder umgerechnet 11,38 €.
Nachverfolgungsprobleme durch TTL
Innerhalb der Data Factory v2 entsteht der Großteil der Kosten in der Regel durch Datenflüsse, was bei der Kostenanalyse zu Irritation führen kann. Zwar gibt es die Möglichkeit, durch eine Option in der Data Factory Kosten in der Analyse der Ressourcen Gruppe pro Pipeline darzustellen, allerdings sind Datenflüsse meist davon ausgenommen und werden unter einer Data-Factory-Ressource zusammengefasst, was eine genaue Analyse verkompliziert.
Die Ursache dafür ist die Time-To-Live eines Clusters. Da es aufwändig wäre für jeden Datenfluss ein neues Cluster hochzufahren, sorgt die TTL dafür, dass Cluster nicht direkt heruntergefahren werden und stattdessen auf weitere auszuführende Datenflüsse warten. Pipelines können jedoch verschachtelt werden, was dazu führen kann, dass ein Cluster Datenflüsse aus mehreren Pipelines verarbeitet. Die genaue Zuordnung wird dadurch erschwert.
Eine mögliche Lösung wäre, die TTL auf 0 zu setzen, was jedoch dazu führen würde, dass für jeden Datenfluss ein neues Cluster hochgefahren werden muss. Das Ergebnis wäre eine höhere, zusätzliche Laufzeit von zwei bis fünf Minuten, die pro Kern als Kosten berechnet werden würden.
Kostenanalyse über REST-Schnittstelle
Zwar keine Lösungen im eigentlichen Sinne, aber ein valider Workaround, ist die Nutzung der von Azure angebotenen REST-Schnittstellen. In Azure Data Factory v2 generiert jede Aktivität eine Ausgabe im JSON-Format, die neben tatsächlich errechneten Werten auch Metadaten, wie Art und Anzahl der genutzten Ressourcen, enthält.
Möchte man diese Daten nun programmatisch verarbeiten, dann bietet Azure eine Reihe von Endpunkten zum Verwalten einer Data-Factory-Instanz, wie dem Erstellen oder Löschen von Pipelines, aber auch dem Abfragen der Ergebnisse abgeschlossener Durchläufe.
Relevant sind hier zwei Endpunkte: Pipeline Runs - Get und Activity Runs - Query by Pipeline Run. Der eine gibt alle Pipelinedurchläufe in einem definierten Intervall zurück, und mit den Run-IDs lassen sich die Ausgaben, und damit die Ressourcen, aller von der Pipeline ausgeführten Aktivitäten erhalten.

Im nächsten Schritt werden die Preise pro Ressource aus einer separaten REST-Schnittstelle, der Azure Retail Prices API, ausgelesen, mit den Aktivitäten verrechnet, und zum Schluss für Pipelines aufaddiert.
So erhält man eine deutlich granulare Übersicht über Laufzeiten und Kosten, als es die Kostenanalyse sonst ermöglicht. Auf dieser Basis können ohne großen Mehraufwand weitere Erkenntnisse aus den Daten gezogen werden, wie zum Beispiel die Transformationsdauer einzelner Tabellen.
Auch wenn die Datentransformation durch ADF nicht mehr auf der Datenbank stattfindet, so muss sie trotzdem in der Lage sein, die transformierten Daten möglichst schnell aufzunehmen. Was sie vorher in Rechenkapazität leisten musste, wird nun im I/O benötigt.
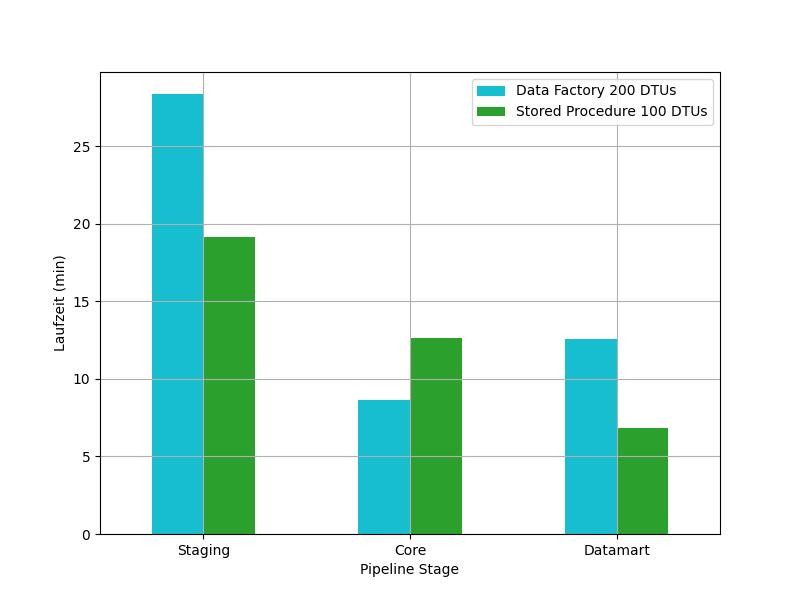
In Abb. 2 sind die Laufzeiten der Phasen einer täglichen Data Warehouse Beladung zu sehen. Die blauen Säulen stellen die Laufzeiten der Azure Data Factory v2 dar, die grünen Säulen die gleichen Operationen, jedoch als Stored Procedure direkt auf der Datenbank implementiert. Die Beladung erfolgte aus insgesamt 2,5 GB an Daten verteilt über 50 Dateien im JSON-Format in einem Azure Blob Storage. Die Datenflüsse der Data Factory Instanz lief mit acht Kernen, der kleinstmöglichen Skalierung. Zu beobachten ist, dass das Lesen und Schreiben der Daten in Azure Data Factory v2 deutlich länger benötigt als die Stored Procedures. Diese Erkenntnis veränderte sich auch dann nicht, als bei der Ausführung der Pipelines die zugrundeliegende Datenbank höher skaliert wurde, als sie es bei der Ausführung der Stored Procedures war. Nicht direkt ablesbar ist hier der Kostenunterschied, der jedoch signifikant ist. Während die Stored Procedures für einen Durchlauf 0,1571 € an Kosten verursacht haben, lag die Data Factory bei 6,2072 €. Enthalten sind bei beiden Werten sowohl die Datenbankkosten als auch, bei den Prozeduren, die Kosten der Azure Automation Runbooks, von welchen die Prozeduren gestartet worden sind.
Interessant ist hier, dass die Azure Data Factory v2 bei einer niedrigeren Datenbankskalierung nicht nur länger benötigt, sondern auch höhere Kosten verursacht. Besser veranschaulicht wird das Phänomen bei der initialen Beladung eines zunächst leeren Data Warehouses, wo weniger Compute und mehr I/O Ressourcen benötigt werden. In Abb. 3 sind erneut Laufzeiten zu sehen.
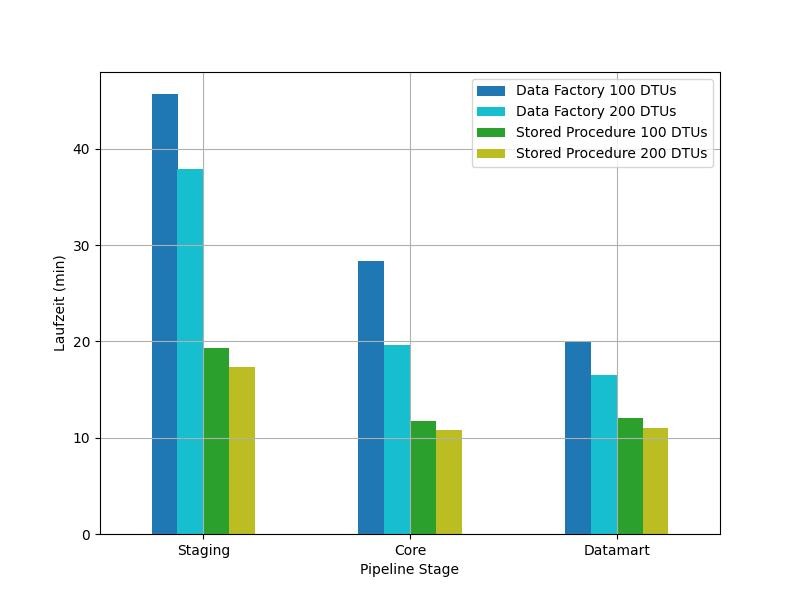
Für die Stored Procedures machte das Hochskalieren auf 200 DTUs nur einen geringfügigen Unterschied: sie liefen etwas schneller durch, und kamen dafür auf 0,28 €. Bei der Azure Data Factory v2 verhielt es sich anders. Für einer Skalierung von 100 DTU benötigte Azure Data Factory v2 01:38h und verursachte Kosten in Höhe von 8,886 €, für 200 DTU betrug die Laufzeit 01:17h und es entstanden Kosten in Höhe von 7,2813 €.
Die Redewendung „Zeit ist Geld“ trifft also auch im Cloud-Umfeld zu: Je länger ein Datenfluss zum Lesen und Schreiben auf eine Datenbank benötigt, desto höher sind die entstehenden Kosten, da in dieser Zeit die Rechencluster trotzdem aktiv sind und Cluster-Kosten deutlich stärker skalieren. Schon bei der geringsten Anzahl an Kernen akkumulieren jede Minute acht vCore-Minuten. Hinzu kommt, dass mehrere Cluster parallel je einen Datenfluss ausführen können. Unter diesen Voraussetzungen kann es Sinn machen, die Datenbank höher zu skalieren als bei rein ELT-basierten Verfahren nötig wäre.
Fazit
SaaS-Lösungen haben in der Regel höhere Nutzungskosten als lokale Alternativen. Mit anderen Worten: das ist der Preis dafür, dass Themen wie Infrastruktur, Lizenzen oder Ressourcen-Verwaltung in den Hintergrund rücken.
Die Azure Data Factory v2 bietet eine No-Code Oberfläche für die Implementierung von Datentransformationen sowie derzeit 103 Konnektoren zu anderen Services, auch außerhalb von Azure. Zusammenfassend lässt sich feststellen, dass es für kleine Datenmengen oder einfache Transformationen wahrscheinlich kosteneffektivere Alternativen auf dem Markt gibt. Letztendlich muss je nach Anwendungsfall die Entscheidung getroffen werden, ob die Kosten in einem sinnvollen Verhältnis zu den Anforderungen stehen.
Sollten Sie Fragen zu Kosten oder anderen Themen rund um die Azure Data Factory haben, zögern Sie nicht uns zu kontaktieren.
Seminarempfehlung
CLOUD COMPUTING ESSENTIALS CLOUD-COMP
Mehr erfahrenWerkstudent
Kommentare