
ksqlDB, die Superkraft im Kafka Universum - Part 2
KsqlDB ist eine Event-Streaming-Datenbank zum Aufbau von Datenstromverarbeitungsanwendungen auf Apache Kafka. Im vorangegangenen Artikel wurde ksqlDB vorgestellt und die Vorteile sowie die Gründe für die Existenz einer weiteren Lösung zur Datenstromverarbeitung innerhalb des Kafka-Universums dargelegt. Im Vergleich zu Kafka Streams verfolgt ksqlDB einen anderen Ansatz.
In diesem Artikel wird die Darstellung von ksqlDB vertieft: ein detailliertes Bild der ksqlDB-Architektur und der Konzepte, die für ein besseres Verständnis erforderlich sind, wird angeboten. Ferner wird auch hier, wie beim ersten Artikel das gleiche Ziel verfolgt: Ein Verständnis der Unterschiede zwischen Stream-Processing-Lösungen innerhalb des Kafka-Ökosystems (Kafka Streams und ksqlDB) zu schaffen.
Dieser Artikel ist Teil einer dreiteiligen Serie. Für ein besseres Verständnis ist es empfohlen, den vorherigen Beitrag zu lesen. Am Ende dieses Artikels sollten Sie ein besseres Verständnis von ksqlDB, den Anwendungsfällen und den Problemstellungen haben, die damit gelöst werden.
ksqlDB Architektur
ksqlDB bietet eine SQL-Schnittstelle zur Datenstromverarbeitung, die Filterung, Aggregationen und Joins ermöglicht. ksqlDB nutzt Kafka als persistenten Speicher, um Berechnungen durchzuführen.
Eine ksqlDB-Lösung kann als einfache zweistufige Architektur mit einer Rechenschicht (ksqlDB) und einer Speicherebene (Kafka) betrachtet werden. Die Daten werden in Kafka gespeichert und die Verarbeitung der Daten erfolgt in ksqlDB.
Abbildung 1 zeigt diese zweischichtige Architektur. Es ist wichtig zu beachten, dass beide Schichten und deren Infrastruktur unabhängig voneinander elastisch skaliert werden können.
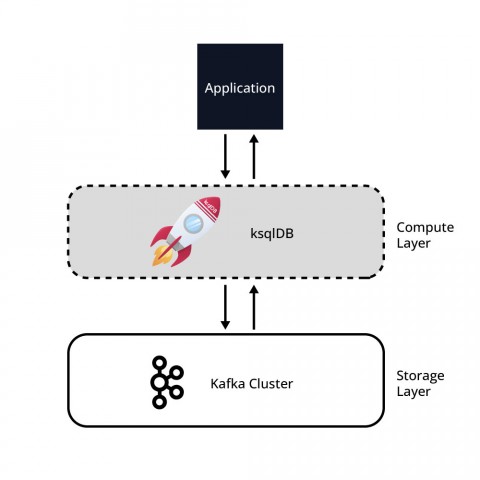
ksqlDB besteht aus vier Komponenten, die in zwei Hauptgruppen unterteilt sind: ksqlDB-Server und ksqlDB-Clients: eine SQL-Engine, ein REST-Dienst, eine Befehlszeilenschnittstelle und eine Benutzerschnittstelle.
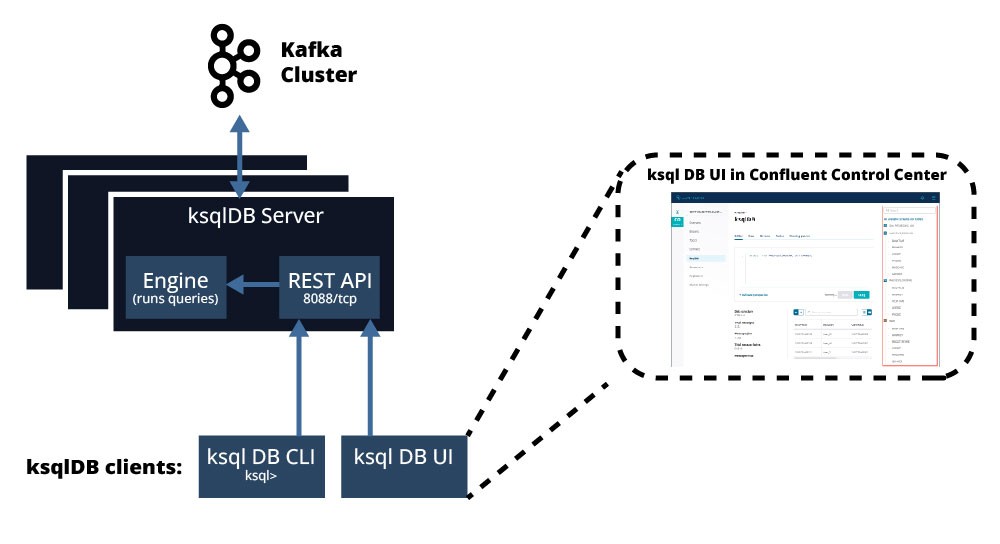
Die Abbildung 2 stellt alle diese Komponente dar:
ksqlDB Server bestehend aus …
- SQL Engine
- und ksqlDB REST Service
- ksqlDB cli
- ksqlDB UI
Innerhalb des ksqlDB-Servers
Der ksqlDB-Server ist für die Ausführung von Anwendungen zur Datenstromverarbeitung zuständig. Eine deployte ksqlDB-Anwendung wird auf unabhängigen, fehlertoleranten und skalierbaren ksqlDB-Server-Instanzen ausgeführt.
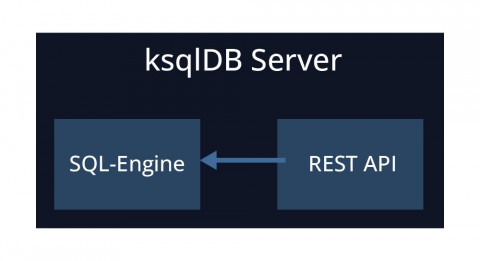
Ein ksqlDB-Server besteht aus einer SQL-Engine und einer Rest-API. ksqlDB-Server werden getrennt vom Kafka-Cluster bereitgestellt (normalerweise auf gesonderten Maschinen/Containern). Abbildung 3 gibt einen Überblick über einen ksqlDB-Server.
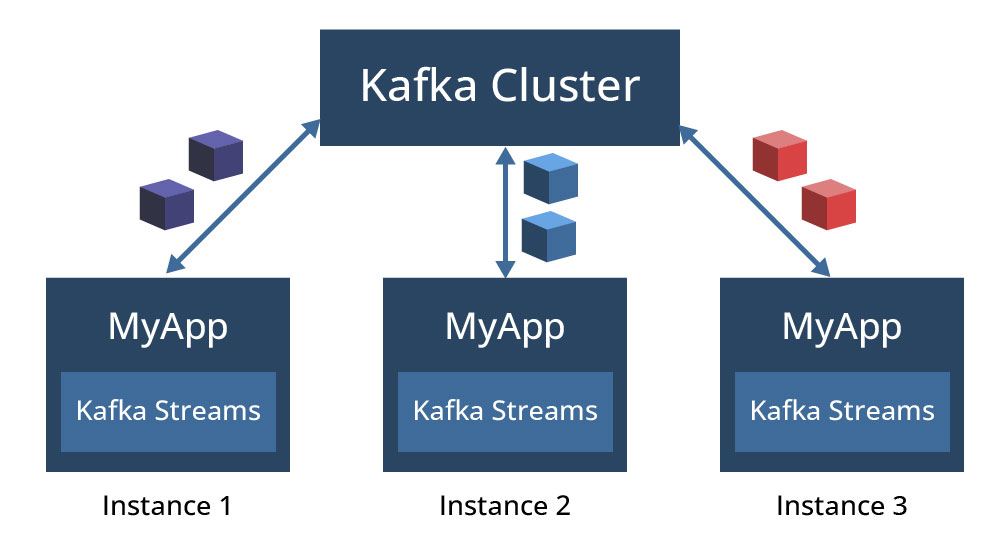
Eine an ksqlDB übermittelte Abfrage wird in eine Kafka-Streams-Anwendung kompiliert, die im Hintergrund ausgeführt wird und dem gleichen Ausführungsmodell wie Kafka-Streams-Anwendungen folgt. Eine Kafka-Streams-Anwendungsinstanz wird in einer Java Virtual Machine (JVM) auf einem Rechner ausgeführt und mehrere Instanzen einer Anwendung werden entweder auf demselben Rechner oder über mehrere Rechner verteilt in Betrieb gebracht. Jede Instanz läuft in einem eigenen JVM-Prozess und wird einer oder mehreren Partitionen zugeordnet, je nachdem, wie viele Partitionen das Topic hat. Die Abbildung 4 zeigt, wie verschiedene Instanzen einer Kafka-Streams-Anwendung mit dem Namen MyApp verschiedene Partitionen eines Topics verarbeiten, wobei jede Instanz in einem eigenen JVM-Prozess läuft.
ksqlDB verfolgt einen analogen Ansatz für die Parallelität und die Verteilung der Arbeitslast auf die ksqlDB-Serverinstanzen. Eine übermittelte Abfrage kann auf mehreren Instanzen (ksqlDB-Servern) ausgeführt werden und jede Instanz verarbeitet einen Teil der Eingabedaten aus dem/den Eingabe Topic/-s und erzeugt Teile der Ausgabedaten für das/die Ausgabe Topic/-s.
Workloads, die von einer bestimmten Abfrage erzeugt werden, können mithilfe der Konfiguration ksql.service.id auf mehrere ksqlDB-Server verteilt werden. Die service-id-Konfiguration beeinflusst die Einteilung einer ksqlDB-Serverinstanz zu einem bestimmten ksqlDB Cluster: Sind mehrere ksqlDB-Server mit derselben ksql.service.id am selben Kafka-Cluster verbunden, bilden sie einen ksqlDB-Cluster und teilen sich die Arbeitslast. Andernfalls, wenn sich mehrere ksqlDB-Server mit demselben Kafka-Cluster verbinden, aber nicht dieselbe ksql.service.id verwenden, erhält jeder ksqlDB-Server ein anderes Befehls-Topic und bildet separate ksqlDB-Cluster auf Grundlage der ksql.service.id-Konfiguration. Dies ist in Abbildung 5 zu sehen, wo sich drei ksqlDB-Server verschiedene ksql.service.ids teilen und zwei verschiedene ksqlDB-Cluster bilden.
Es ist wichtig zu beachten, dass ein ksqlDB-Cluster hier eine Gruppe von kooperierenden ksqlDB-Servern bezeichnet, die die gleiche Arbeitslast verarbeiten. In diesem Beispiel kann die Zuweisung von mehr ksqlDB-Servern zum Cluster „Finanzen“ sinnvoll sein, um die Verarbeitung von Arbeitslasten zu verbessern.
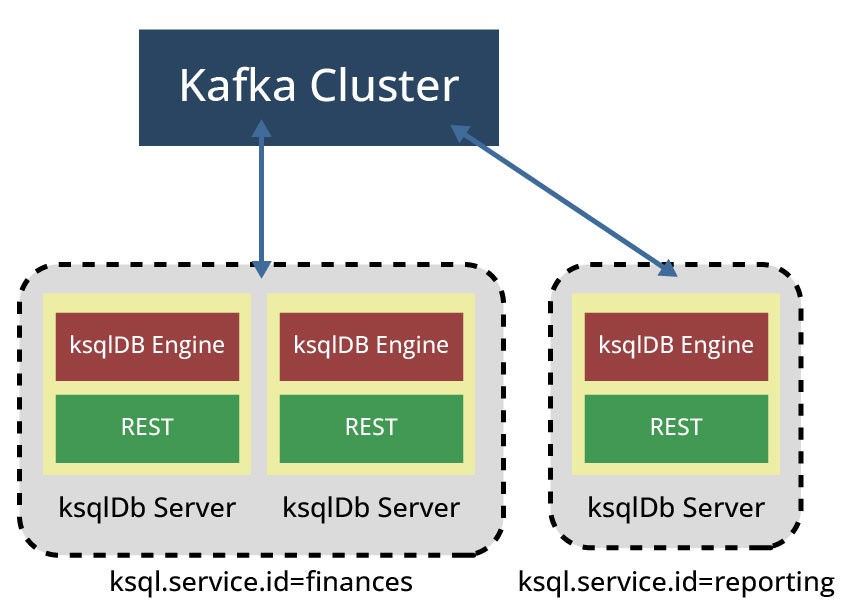
Da ksqlDB-Server mit derselben Service-ID Mitglieder derselben „consumer group“ sind, übernimmt Kafka automatisch die Neuzuweisung und Verteilung der Arbeitslast, wenn neue ksqlDB-Server hinzugefügt oder entfernt werden. Die Entfernung kann manuell oder automatisch erfolgen, z. B. aufgrund eines Systemfehlers. Das Hinzufügen zusätzlicher Instanzen mit der gleichen Service-ID führt deswegen zu einer Erhöhung der Verarbeitungskapazität von Anwendungen. Es ist wichtig zu beachten, dass eine Verkleinerung oder das Entfernen von ksqlDB-Servern jederzeit erfolgen kann. In allen Fällen kommunizieren die ksqlDB-Serverinstanzen mit Kafka-Clustern, sodass Änderungen ohne einen notwendigen Neustart der Anwendung durchgeführt werden können.
SQL-Engine
Die SQL-Engine ist Teil des ksqlDB-Servers, der für das Parsen von SQL-Anweisungen, die Konvertierung der Anweisungen in Kafka-Streams-Topologien und schließlich die Ausführung der Kafka-Streams-Anwendungen und -Abfragen verantwortlich ist. Die Abbildung 6 skizziert diesen Prozess.
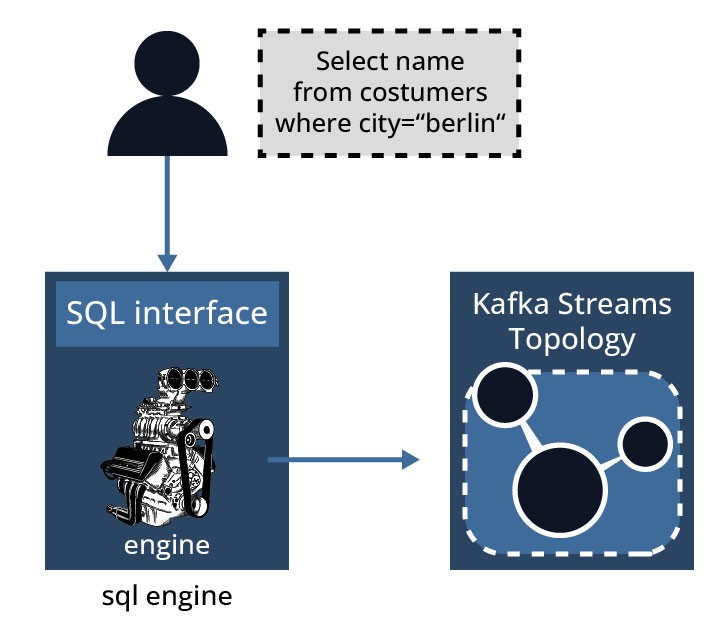
Zu Beginn des Prozesses wird die gewünschte Anwendungslogik in SQL-Anweisungen übersetzt, die von der Engine auf verfügbaren ksqlDB-Servern ausgeführt werden. Auf jeder ksqlDB-Server-Instanz läuft eine ksqlDB-Engine. Die ksqlDB-Engine ist in der Klasse KsqlEngine.java implementiert.
KsqlDB REST-Schnittstelle
ksqlDB enthält eine REST-Schnittstelle, über die Clients mit der SQL-Engine interagieren können. Sie ermöglicht die Kommunikation von der ksqlDB-Befehlszeilenschnittstelle (CLI), der ksqlDB-Benutzeroberfläche, dem Confluent Control Center oder von jedem anderen REST-Client.
Diese Clients können somit verschiedene Arten von Abfragen wie DML-Anweisungenübermitteln und verschiedene Aufgaben ausführen, wie z. B. die Überprüfung des Cluster-Status/Gesundheitszustands des Clusters und vieles mehr. Standardmäßig lauscht die Rest-Schnittstelle auf Port 8088 und kommuniziert über HTTP. Der Port des Endpunkts kann mit der Konfiguration des Listeners geändert werden. Die Kommunikation über HTTPS kann über die TLS-Konfigurationen aktiviert werden.
Die REST-API ist optional und kann je nach Betriebs-/Einsatzmodus vollständig deaktiviert werden. Für interaktives Arbeiten wird diese jedoch benötigt.
Die verschiedenen ksqlDB Clients
Confluent bietet verschiedene Clients für die Interaktion mit ksqlDB und ksqlDB-Servern.
ksqlDB CLI
Das ksqlDB CLI (ksqlDB command line interface) ist eine Befehlszeilenanwendung, die Interaktionen mit einem laufenden ksqlDB-Server ermöglicht. Über eine Konsole mit interaktiven Sitzungen können Benutzer Abfragen stellen, Topics prüfen, ksqlDB-Konfigurationen anpassen und so mit ksqlDB experimentieren und Streaming-Anwendungen entwickeln. Das ksqlDB CLI ist so konzipiert, dass es den Benutzern von MySQL, PostgreSQL und ähnlichen Anwendungen vertraut ist. Das ksqlDB CLI ist im Paket io.confluent.ksql.cli implementiert.
Diese wird als Docker-Image verteilt (confluentinc/ksqldb-cli) und ist Teil verschiedener Confluent Platform-Distributionen (vollständig verwaltet in der Confluent Cloud oder über eine selbst verwaltete Bereitstellung).
ksqlDB UI
Die Confluent Platform enthält auch eine Benutzeroberfläche für die Interaktion mit ksqlDB. Diese UI ist eine kommerzielle Funktion, die nur für die kommerziell lizenzierte Version von Confluent Platform und Confluent Cloud verfügbar ist. Sie ermöglicht nicht nur die Visualisierung von Abfragen und eingereichten Abfragen, sondern auch zusätzliche Operationen wie die Visualisierung des Datenflusses von Daten, die Erstellung von Streams und Tabellen über Webformulare.
Deployment Modi
ksqlDB bietet zwei verschiedene Bereitstellungsmodi, abhängig vom Grad der Interaktivität mit ksqlSB-Servern:
- Interaktiver Modus
- Headless Modus
Interaktiver Modus
Der interaktive Modus ist der Standard-Einsatzmodus für ksqlDB und erfordert keine besondere Konfiguration.
In diesem Modus wird die REST-Schnittstelle von den verschiedenen Clients (bevorzugte REST-Clients, ksqlDB CLI oder Confluent Control) verwendet, um eine Verbindung herzustellen. Clients können jederzeit neue Abfragen einreichen und über die REST-Schnittstelle mit ksqlDB-Servern interagieren (siehe Abbildung 7). Ein Benutzer kann zum Beispiel die vorhandenen Topics im Kafka-Cluster erkunden, Abfragen schreiben und deren Ergebnisse in Echtzeit einsehen. Eine beliebige Anzahl von Serverinstanzen kann dynamisch gestartet werden. Persistente Abfragen können hinzugefügt bzw. entfernt werden, ohne ksqlDB-Server neu zu starten.
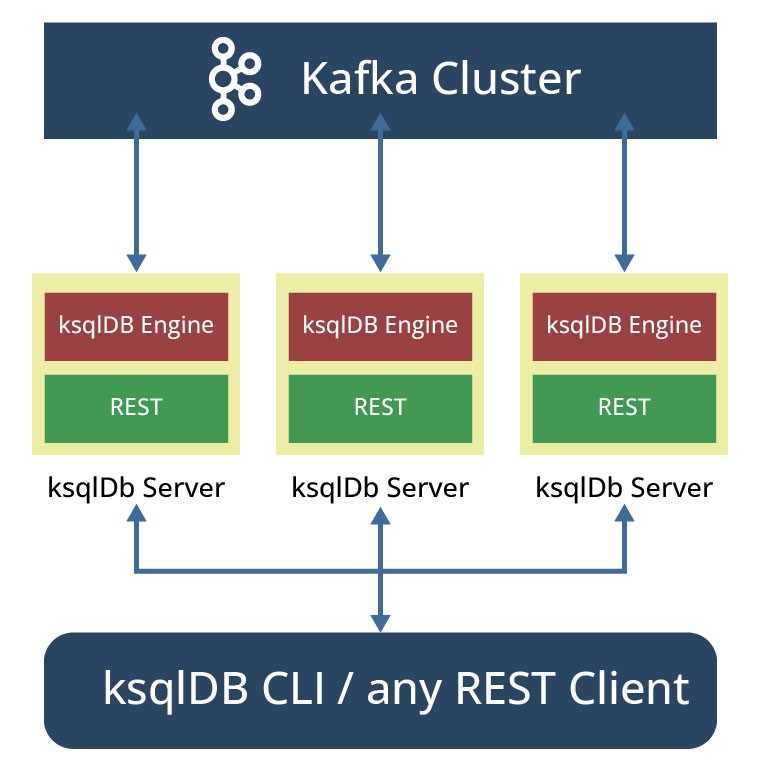
Die Verteilung und gemeinsame Nutzung von Anweisungen und Befehlen zwischen Clustern ist nur mithilfe eines internen Topics, des sogenannten command topic, möglich. Alle Abfragen, die an die SQL-Engine (über die REST-API) übermittelt werden, müssen in dieses Topic geschrieben werden.
Dieses Topic, das automatisch von ksqlDB erzeugt und verwaltet wird, speichert neben SQL-Anweisungen auch einige Metadaten, um sicherzustellen, dass die Anweisungen bei Neustarts und Upgrades von ksqlDB immer noch in einer kompatiblen Art und Weise übersetzt werden. KsqlDB-Server im gleichen Cluster (mit der gleichen ksql.service.id) können die ausgeführten Anweisungen und die damit verbundenen Arbeitslasten gemeinsam nutzen.
Der Name des command Topics wird aus der Einstellung ksql.service.id in der Server-Konfigurationsdatei abgeleitet.
Headless-Modus
Der Headless-Modus erlaubt es, im Gegensatz zum interaktiven Modus, den Clients nicht interaktiv Abfragen an den ksqlDB-Cluster zu stellen. Alle Abfragen werden in SQL-Dateien (eine oder mehrere) geschrieben und ksqlDB wird mit diesen Dateien als Argument gestartet: ksqlDB-Serverinstanzen verwenden diese Dateien und jede Serverinstanz liest die angegebenen SQL-Dateien, kompiliert die ksqlDB-Anweisungen in Kafka-Streams-Anwendungen und startet die Ausführung der generierten Anwendungen (siehe Abbildung 8).
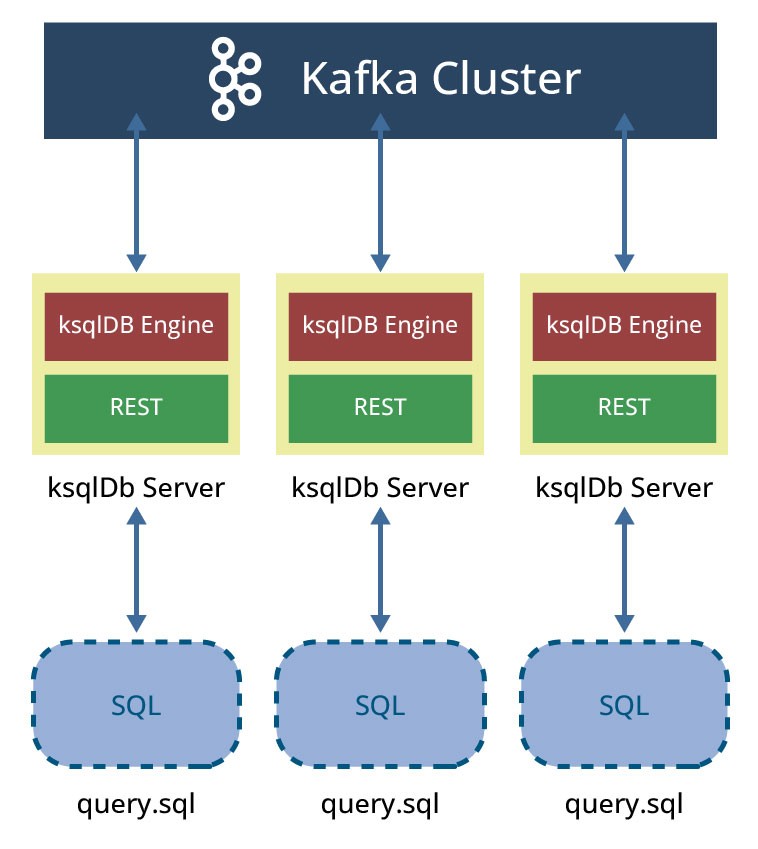
Im Gegensatz zum interaktiven Modus wird im Headless-Modus das Command Topic nicht für die Replikation der Anweisungen verwendet. Es werden jedoch einige interne Metadaten in ein Konfigurations-Topic geschrieben, das sogenannte Config Topic.
Obwohl eine beliebige Anzahl von Serverinstanzen im Headless-Modus gestartet werden kann, ist es wichtig zu beachten, dass diese Instanzen nicht dynamisch nach Wunsch gestartet werden können.
Dieser Modus kann für Szenarien interessant sein, in denen eine Umgebungstrennung erforderlich ist, z. B., wenn eine Produktionsumgebung gesperrt werden soll, um sicherzustellen, dass keine Änderungen und keine zusätzliche Arbeitslast auf die laufenden Abfragen einwirken.
Ein tiefer Einblick hinter SQL
KsqlDB kombiniert SQL-Datenbank-Konstrukte mit der Datenabstraktion von Kafka-Streams und ermöglicht das Lesen, Filtern, Transformieren oder Verarbeiten von Ereignisströmen und -tabellen, die aus Kafka Topics aufgebaut werden. Wie ein klassisches RDBMS enthält ksqlDB eine SQL-Grammatik, einen Parser und eine Ausführungseinheit. Der in KSQL (und später ksqlDB) implementierte SQL-Dialekt erweitert klassisches SQL um die Unterstützung von Streams und Streams-bezogenen Abstraktionen. Dieser Dialekt enthält sprachliche Konstrukte wie SELECT für die Projektion, FROM für die Definition von Quellen, WHERE für die Filterung und JOIN für die Verbindung. Wie traditionelles SQL bietet es Unterstützung für DDL- und DML-Operationen mit Streams und Tabellen als gleichwertige "Sammlungen" zu Tabellen in traditionellen relationalen Datenbanken.
Data Definition Language (DDL) Befehle
In Datenbanken sind DDL-Anweisungen nur für die Änderung von Metadaten zuständig und operieren nicht auf Daten. Nachfolgend finden Sie einige Beispiele von DDL-Anweisungen:
- CREATE STREAM zur Erstellung eines Streams
- CREATE TABLE zur Erstellung einer Tabelle
- DROP STREAM
- DROP TABLE
- SHOW STREAMS | TABLES
- DESCRIBE (EXTENDED) STREAMS
- DESCRIBE (EXTENDED) TABLES
- CREATE STREAM AS SELECT (CSAS)
- CREATE TABLE AS SELECT (CTAS)
Data Manipulation Language (DML) Befehle
Im Gegensatz zu DDL-Anweisungen ändern Data Manipulation Language-Anweisungen Daten und nicht die Metadaten. Die SQL-Engine innerhalb ksqlDB kompiliert DML-Anweisungen in Kafka-Streams-Anwendungen, die auf einem Kafka-Cluster ausgeführt werden. Die DML-Anweisungen umfassen:
- SELECT
- INSERT INTO
- INSERT INTO VALUES
DML-Anweisungen (Data Manipulation Language), wie UPDATE und DELETE sind nicht verfügbar.
Views
ksqlDB und KSQL bieten, wie traditionelle Datenbanken, materialisierte Sichten (Views), d. h. benannte Objekte, welche die Ergebnisse einer Abfrage enthalten. In bekannten traditionellen RDBMS können Views entweder „lazily“ (Aktualisierung wird in eine Warteschlange gestellt, um später angewendet zu werden) oder „eagerly“ (Aktualisierung wird angewendet, sobald neue Daten eintreffen) aktualisiert werden. Sichten in ksqlDB werden „eagerly“ gepflegt.
Schemas, Typen, and Operatoren
ksqlDB unterstützt Schemata. Datenquellen wie Streams und Tabellen haben ein zugehöriges Schema. Dieses Schema definiert die in den Daten verfügbaren Spalten (über Feldnamen und Datentypen), genau wie die Spalten in einer klassischen SQL-Datenbanktabelle.
KsqlDB unterstützt dazu auch benutzerdefinierte Typen. Benutzerdefinierte Typen können definiert werden, um eine Gruppe von Feldnamen und ihre zugehörigen Datentypen anzugeben. Diese definierten Typen (und Schemas) können später in Abfragen verwendet werden, um auf dieselbe Sammlung von Feldern zu verweisen. Mit dem folgenden Befehl können benutzerdefinierte Typen erstellt werden:
Create a custom type CREATE TYPE <type_name> AS <type>;
ksqlDB unterstützt verschiedene Typen und enthält eine Vielzahl von Funktionen und Operatoren für die Arbeit mit Daten, wie z. B. die nachfolgend aufgeführten Operatoren:
- Arithmetische Operatoren (+, -, /, *, %)
- Operatoren zur Verkettung von Zeichenfolgen (+, ||)
- Operatoren für den Zugriff auf Array-Indizes oder Map-Schlüssel ([])
- Strukturen Dereferenz-Operatoren (->).
- ARRAY<element-type>Eine Sammlung von Elementen des gleichen Typs (z.B. ARRAY<STRING>)
- BOOLEAN Boolscher Wert
- INT 32-bit Ganzzahl mit Vorzeichen (Signed Integer)
- BIGINT 64-bit Ganzzahl mit Vorzeichen (Signed Integer)
- DOUBLE Double precision (64-bit) IEEE 754 Fließkommazahl
- DECIMAL (precision, scale) Eine Fließkommazahl mit einer konfigurierbaren Anzahl von Gesamtstellen (Präzision) und Stellen rechts vom Dezimalpunkt (Skala)
- MAP Ein Objekt, das Schlüssel und Werte enthält, von denen jeder mit einem Datentyp übereinstimmt (z. B. MAP <STRING, INT>)
- STRUCT Eine strukturierte Collection von Feldern (z. B. STRUCT<FOO INT, BAR BOOLEAN>)
- VARCHAR or STRING feste und variable Zeichenketten
ksqlDB bietet zusätzlich eine Schnittstelle zur Definition eigener Funktionen (benutzerdefinierte Funktionen), die in Java implementiert sind, um auch benutzerdefinierte Typen zu verarbeiten.
Push and pull Queries
ksqlDB hat das Konzept der Push-Abfragen eingeführt und unterscheidet sich damit von seiner früheren Version KSQL. Push Queries (Push-Abfragen) stellen einen der Hauptunterschiede zwischen KSQL und ksqlDB dar.
Pull Queries (Pull-Abfragen), die bisher in KSQL verwendet wurden, entsprechen bekannten Abfragen in traditionellen Datenbanken, bei denen der aktuelle Zustand einer Datenbank nach einer Schlüsselsuche zurückgegeben wird. Eine SELECT-Anweisung in einer traditionellen Datenbank veranschaulicht dies.
Die von einem Client gestellte Abfrage wird verarbeitet, um ein Ergebnis zum Zeitpunkt "jetzt" zu erhalten und wird beendet, wenn dieser Zustand an den Client zurückgegeben wird. In Abbildung 9 gibt die Abfrage (SELECT * FROM orders;) alle Aufträge zum Zeitpunkt der Verarbeitung der Abfrage zurück. Der eingehende Auftrag 23, der in diesem Fall noch nicht vollständig erfasst war, wird nicht in die Ergebnismenge aufgenommen.
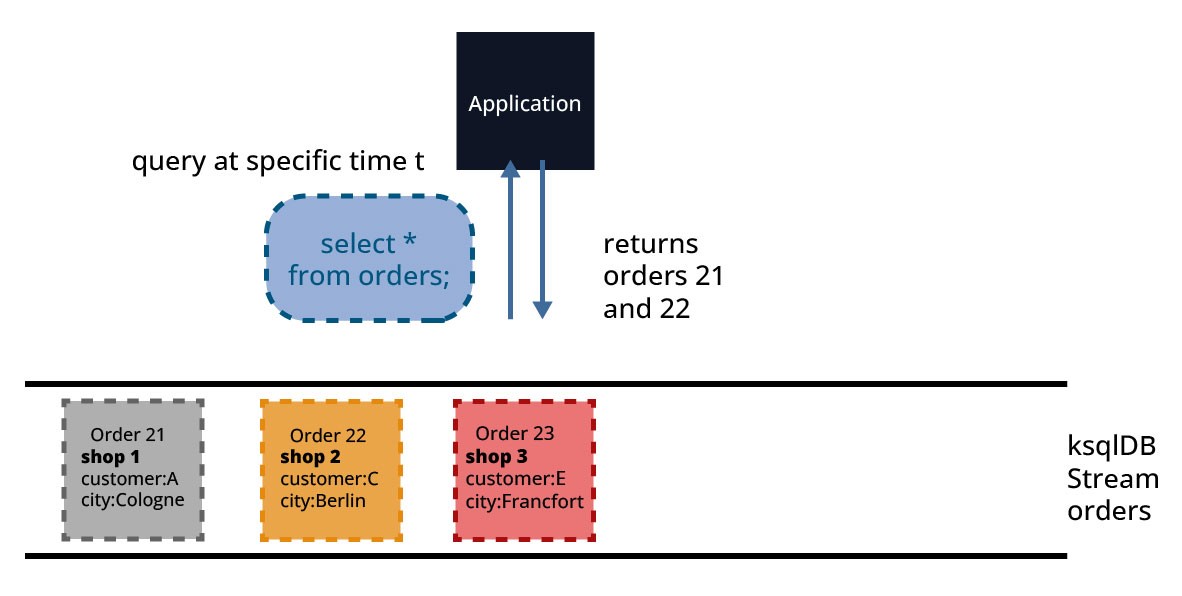
Pull-Abfragen sind also kurzlebige Abfragen, die zur Durchführung von schlüsselgebundenen Abfragen von Daten verwendet werden. Sie eignen sich gut für Anfrage/Antwort-Abläufe und können von Clients verwendet werden, die mit ksqlDB in einem synchronen/auf Abruf basierenden Workflow arbeiten müssen.
Die Pull-Abfragen können nur für materialisierte Sichten oder ksqlDB-Tabellen verwendet werden. Da materialisierte Sichten beim Eintreffen neuer Ereignisse inkrementell aktualisiert werden, laufen Pull-Abfragen mit vorhersehbar geringer Latenz.
Eine Push-Abfrage ist eine Art Abfrage, bei der ein Client das Ergebnis abonniert, um in Echtzeit informiert zu werden, sobald sich etwas geändert hat. Push-Abfragen laufen im Gegensatz zu Pull-Abfragen kontinuierlich und übermitteln Ergebnisse, sobald neue Daten verfügbar sind. „Push“, weil das Ergebnis der Abfragebedingungen an den Client weitergeleitet wird, sobald neue Daten, die diese Abfragebedingungen erfüllen, auftreten.
Dies wird von Abbildung 10 veranschaulicht: nach Erhalt der Abfrage (SELECT * FROM orders emit changes;) werden alle Aufträge, die in den ksqlDB-Stream aufgenommenen werden, als Ergebnis an die Anwendung zurückgegeben.
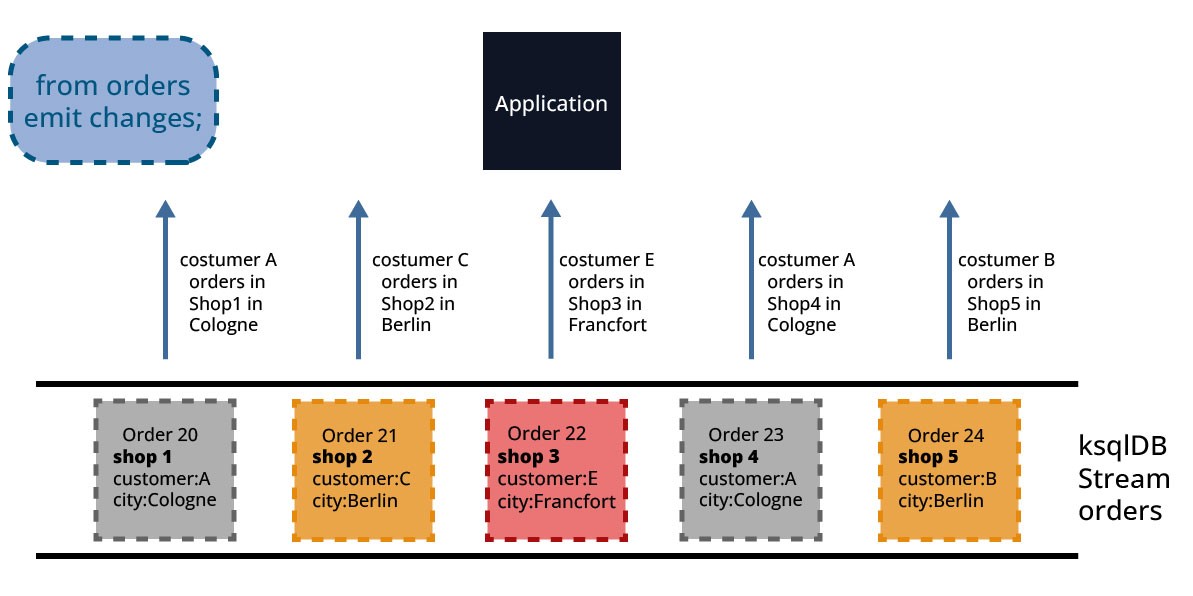
Push-Abfragen werden wie Pull-Abfragen in einer SQL-ähnlichen Sprache ausgedrückt und sind durch die EMIT CHANGES-Klausel am Ende der Abfragen gekennzeichnet. Dieser Syntaxzusatz ist nicht kompatibel mit früheren Versionen von KSQL. Das bedeutet, dass eine Streaming-Abfrage in KSQL nicht korrekt als Streaming-Abfrage in ksqlDB interpretiert wird.
Im Gegensatz zu Pull-Abfragen können Push-Abfragen verwendet werden, um entweder Streams oder Tabellen nach einem bestimmten Schlüssel abzufragen und sind nicht auf Key-Look-up-Zuweisungen beschränkt. Push-Abfragen ermöglichen die Abfrage eines Streams oder einer materialisierten Tabelle mit einem Abonnement für die Ergebnisse. Dieses Abonnement ist nicht auf eine bestimmte Art der Abfrageausgabe beschränkt. Es ist zum Beispiel möglich, die Ausgabe einer Abfrage zu abonnieren, die einen Stream zurückgibt.
Push-Abfragen eignen sich gut für asynchrone Anwendungsworkflows und ereignisgesteuerte Microservices, die Ereignisse schnell beobachten und darauf reagieren müssen.
Abbildung 11 bietet eine gute Zusammenfassung der Unterschiede zwischen Pull- und Push-Abfragen.

Distributionen von ksqlDB
ksqlDB ist geistiges Eigentum von Confluent Inc. und wird als Teil des Confluent Platform-Produkts gepflegt. ksqlDB ist in 3 verschiedenen Distributionen erhältlich:
- Standalone
- als Teil des Confluent Cloud Services
- als Teil der Confluent Plattform
ksqlDB in der Standalone-Distribution kann kostenlos heruntergeladen und unter der Confluent Community License frei verwendet werden. Die Confluent Community License erfüllt nicht alle von der Open-Source-Initiative für Open-Source-Projekte definierten Anforderungen. Im Rahmen dieser Community-Lizenz sind Änderungen und Weiterverbreitung nur für Nutzungen erlaubt, die kein konkurrierendes SaaS-Angebot zu Confluent-Produkten darstellen. Generell empfehlen wir, sich mit den Lizenzbedingungen vor der Verwendung auf der Seite von Confluent ausführlich zu informieren.
Abbildung 12 gibt einen Überblick über die verschiedenen Lizenzierungsmodelle, die von verschiedenen Komponenten im Kafka-Universum verwendet werden.
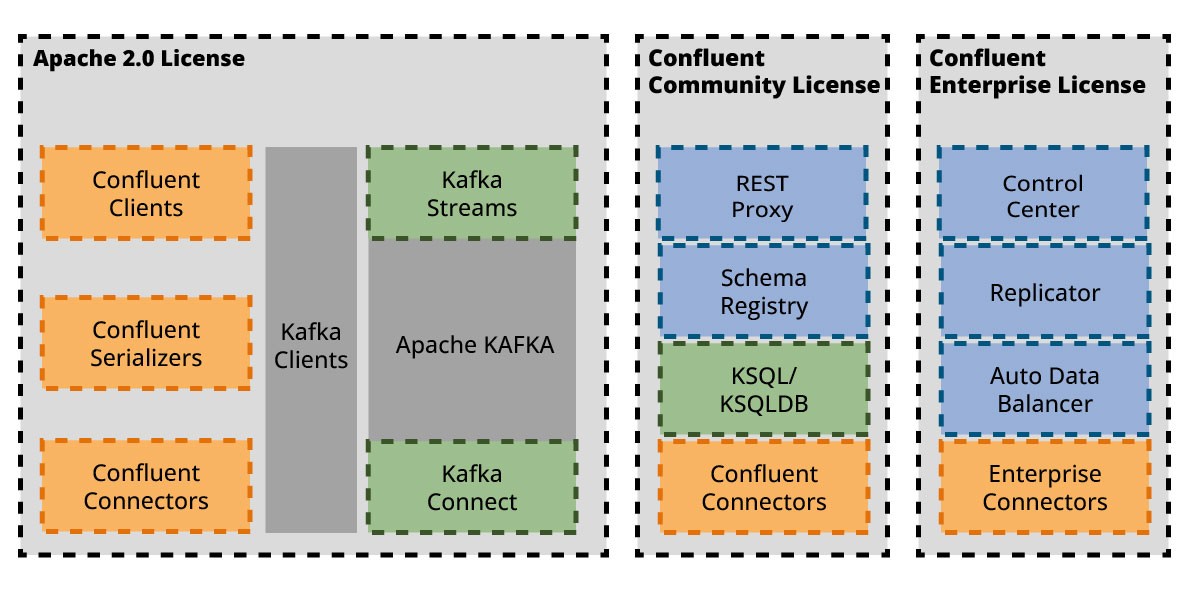
Im Standalone-Modus werden verschiedene docker-compose-Dateien bereitgestellt, um ksqlDB in Containern mit bestehenden Kafka-Installationen zu betreiben oder eine Kafka-Installation mit laufendem ksqlDB einzurichten. (Siehe https://ksqldb.io/quickstart.html)
Die eigenständige ksqlDB-Distribution hat eine begrenzte kommerzielle Unterstützung durch Confluent.
Die Confluent Cloud bietet eine vollständig verwaltete Cloud-native Plattform und einen Service für Apache Kafka. In der Confluent Cloud kann ein ksqlDB-Cluster auf der Grundlage einer Pay-as-you-go-Strategie eingerichtet werden. Anleitungen zum Starten von Kafka- und ksqlDB-Clustern in der Confluence-Cloud sind verfügbar unter https://ksqldb.io/quickstart-cloud.html#quickstart-content.
KsqlDB kann auch in einer self-managed Umgebung als Teil der Confluent Platform for Data in Motion verwendet werden. Confluent bietet getestete Versionen von ksqlDB an, die mit einem kompletten Satz von Komponenten (Kafka, diverse Konnektoren, Schema-Management-Tools und mehr) geliefert werden. Kommerzieller Support ist über ein Abonnement für Confluent Platform erhältlich. Jede neue Version der Confluent Platform enthält eine bestimmte, zuvor ausgelieferte Version der eigenständigen Distribution.
Zusammenfassung
KsqlDB kombiniert SQL-Datenbank-Konstrukte mit der Datenabstraktion von Kafka-Streams und ermöglicht somit das Lesen, Filtern, Umwandeln oder Verarbeiten von Ereignisströmen, die in Kafka-Topics abgelegt werden. Es verwendet verschiedene Komponenten, um die Erstellung von Stream-Processing-Anwendungen zu vereinfachen. Die SQL-Engine analysiert zum Beispiel Anweisungen und wandelt sie in Streams Topologien um, die dann ausgeführt werden.
Dieser Artikel stellt die ksqlDB-Architektur und ihre Komponenten vor, um ein gutes Verständnis für wichtige Konzepte bei der Entwicklung von ksqlDB-Anwendungen zu vermitteln. Der nächste Artikel wird in einem Szenario einen Vergleich zwischen einer Streams-Anwendung und einer ksqlDB-Anwendung bieten.
Seminarempfehlung
APACHE KAFKA GRUNDLAGEN KAFKA-01
Zum SeminarSenior Chief Consultant bei ORDIX
Kommentare