
ksqlDB: die Superkraft im Kafka-Universum - Teil 1
Bietet Kafka mehr als nur die Producer und Consumer API?
In dem Artikel „Harnessing the Power of Kafka“ wurde mit Kafka Streams eine Möglichkeit zur Datenstromprozessierung mit Kafka vorgestellt. Die Streams API bietet einfache Filter sowie komplexere Operatoren wie Joins oder Aggregations, die zustandsloses und zustandsbehaftetes Prozessieren von Datenströmen auf Kafka für Entwickler stark vereinfachen.
In dieser Artikelserie stellen wir mit ksqlDB ein weiteres Mittel zur Entwicklung von Streaming Anwendungen vor. Ferner zeigen wir, warum ein weiteres Mittel neben Kafka Streams benötigt wird, welche Probleme ksqlDB löst und für welche Anwendungsfälle ksqlDB geeignet ist.
Dieser Artikel ist Teil einer 3-teiligen Serie. Wie bei den vorangegangenen Artikeln zu Kafka Streams ist es unser Ziel, einen Überblick über die Tools, Technologien und Frameworks zu geben, die Kafka für die Entwicklung verschiedener Stream-Processing-Anwendungen bereitstellt: von der einfachen Stream- bis hin zur Echtzeit-Verarbeitung. Es ist empfehlenswert, aber nicht zwingend erforderlich, die vorherigen Artikel über Kafka Streams vor diesem zu lesen.
In ersten Teil wird ein Überblick über ksqlDB und seine Vorteile gegeben.
ksqlDB: Einführung
ksqlDB ist eine Open-Source-Event-Streaming-Datenbank, die speziell für Stream-Processing-Anwendungen auf der Grundlage von Apache Kafka entwickelt wurde. ksqlDB ist die Weiterentwicklung der Streaming-SQL-Engine KSQL für Kafka. Das ursprüngliche Projekt KSQL wurde nach der Veröffentlichung wichtiger neuer Funktionalitäten in ksqlDB umbenannt. Sowohl KSQL als auch ksqlDB sind als Open-Source-Projekte (Confluent Community License) und Technologien verfügbar. Obwohl beide Technologien frei verfügbar sind und der Code auf GitHub zugänglich ist, ist es wichtig zu beachten, dass die Confluent Community License nicht alle von der Open Source-Initiative für Open-Source-Projekte definierten Anforderungen erfüllt. Diese Lizenz schränkt die Möglichkeit für Wettbewerber ein, kommerzielle konkurrierende SaaS-Angebote zu Confluent-Produkten anzubieten. Der nächste Artikel (Teil 2) in dieser Serie wird einen Überblick über die verschiedenen Lizenzierungsoptionen geben.
KSQL, ksqlDB und Kafka Streams verfolgen dasselbe Ziel: Den Aufbau von Stream-Processing-Anwendungen zu vereinfachen. Dieser Artikel fokussiert sich auf ksqlDB und zeigt Unterschiede zwischen KSQL und ksqlDB auf.
ksqlDB vereinfacht die Art und Weise, wie Stream-Processing-Anwendungen entwickelt, bereitgestellt und gewartet werden, indem es das Folgende bietet und kombiniert:
- eine Abstraktion der Abfragesprache auf hoher Ebene
- eine relationalen Datenbankmodellierung
- einen integrierten Zugang zu Komponenten des Kafka-Ökosystems (Kafka Connect und Kafka Streams).
ksqlDB wurde von Confluent im Jahr 2019 veröffentlicht. "ksqlDB" bezieht sich hier auf ksqlDB 0.6.0 und höher und "KSQL" bezieht sich auf alle früheren Versionen von KSQL (5.3 und niedriger). ksqlDB ist nicht abwärtskompatibel mit früheren Versionen von KSQL, was bedeutet, dass ksqlDB nicht über eine bestehende KSQL-Bereitstellung ausgeführt werden kann.
Vorteile einer zusätzlichen Stream Processing Lösung
Integration von Kafka Stream, Producer und Consumer APIs
ksqlDB sowie KSQL basieren auf Kafka Streams, dem Stream Processing Framework von Kafka zum Schreiben von Streaming-Anwendungen und Microservices. Es bietet über eine SQL-Schnittstelle eine Abfrageschicht für den Aufbau von Event-Streaming-Anwendungen auf Kafka Topics. Dies ist ein großer Vorteil, denn es werden die Streams-API, die Consumer-API und die Producer-API in einer einzigen API gekapselt und es werden die Vorteile genutzt, die sich aus den verschiedenen Abstraktionen ergeben.
Die folgende Abbildung gibt einen Überblick über die verschiedenen Kafka-APIs, die unterhalb von ksqlDB verwendet werden und darüber, wie ksqlDB-Operationen in diese verschiedenen Kafka-APIs übersetzt werden.
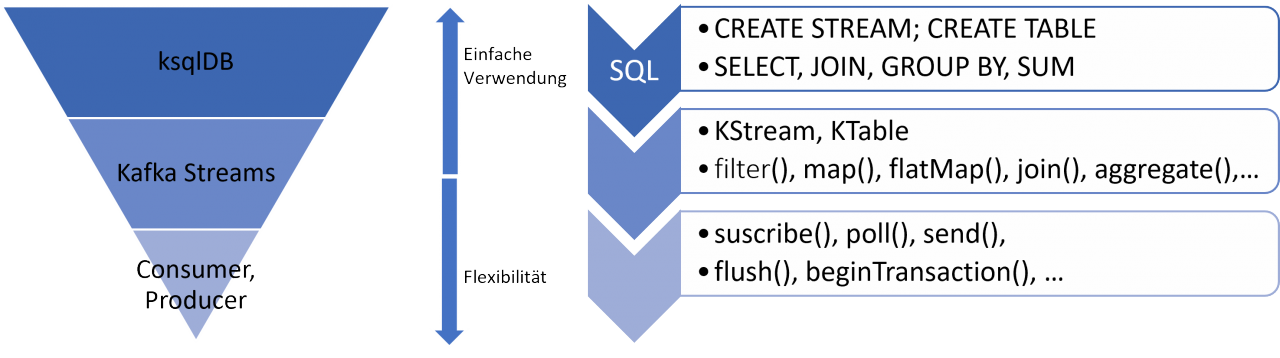
SQL-Anweisungen in ksqlDB werden in Streams-Prozessoren und Topologien übersetzt. Die Operatoren der Streams-Prozessoren werden auf den Kafka Topics zugrunde liegenden Datensammlungen ausgeführt. Die Operationen der Streams-Prozessoren nutzen ihrerseits die API-Methoden und -Operationen der Producer und Consumer API.
Neben der Kapselung und Abstraktion der APIs nutzt ksqlDB alle vorteilhaften Eigenschaften von Kafka Streams wie das Programmiermodell, die verschiedenen Abstraktionen, die reichhaltigen Operationen und die interne Organisation für performante und fehlertolerante Ausführungen auf Topics und Topics-Partitionen.
Die Verwendung des "Event-at-a-time"-Verarbeitungsmodells (abgeleitet von Kafka Streams), kombiniert mit der Leistungsfähigkeit und Einfachheit von SQL, verbirgt die Komplexität des Stream-Processing und erleichtert die Ausführung der Stream-Processing-Anwendung.
Es ist nicht mehr notwendig, Topologien und Prozessoren zu verstehen, um bestimmte Aufgaben und Abfragen durchzuführen.
In ksqlDB, wie auch in Kafka Streams, sind Streams und Tabellen die beiden primären Abstraktionen, die den Kern der Verarbeitungslogik bilden. Diese werden als Sammlungen bezeichnet. Zur Erinnerung: Ein Stream stellt eine geordnete, wiederholbare und fehlertolerante Folge von unveränderlichen Datensätzen dar. Der Artikel „Harnessing the Power of Kafka“ vermittelt ein gutes Verständnis der Datenabstraktionen Stream und Table.
Ereignisse in ksqlDB (wie in Kafka Streams) werden manipuliert, indem neue Sammlungen aus bestehenden abgeleitet werden und die Änderungen zwischen ihnen beschrieben werden. Wenn eine Sammlung mit einem neuen Ereignis aktualisiert wird, aktualisiert auch ksqlDB die von ihr abgeleiteten Sammlungen in Echtzeit.
Die folgende Abbildung (Abbildung 2) zeigt die Verarbeitung von Ereignissen in ksqlDB-Sammlungen (Tabellen). In folgendem Beispiel wird eine Anwendung modelliert, die Benutzerinformationen in einem Kafka-Topic namens „Kunden“ speichert. Die Einträge in diesem Topic stellen reale Ereignisse dar, die im Laufe der Zeit auftreten.
Mit dem Befehl CREATE TABLE werden die ksqlDB-Tabellen „kunden“ und „kunden_cologne“ erstellt, die alle Kunden bzw. nur Kunden mit Wohnsitz in der Stadt Köln enthalten. Zur Veranschaulichung wurden die für die Anzeige des Inhalts der Tabellen erforderlichen Abfragen nicht angezeigt (select * from kunden emit changes und select * from kunden_cologne emit changes). Ebenso wurden die Strukturen der ksqlDB-Tabellen vereinfacht, um nur die in den Tabellen enthaltenen Zeilenschlüssel darzustellen. Andere Spalten wie z. B. name, city werden nicht dargestellt.
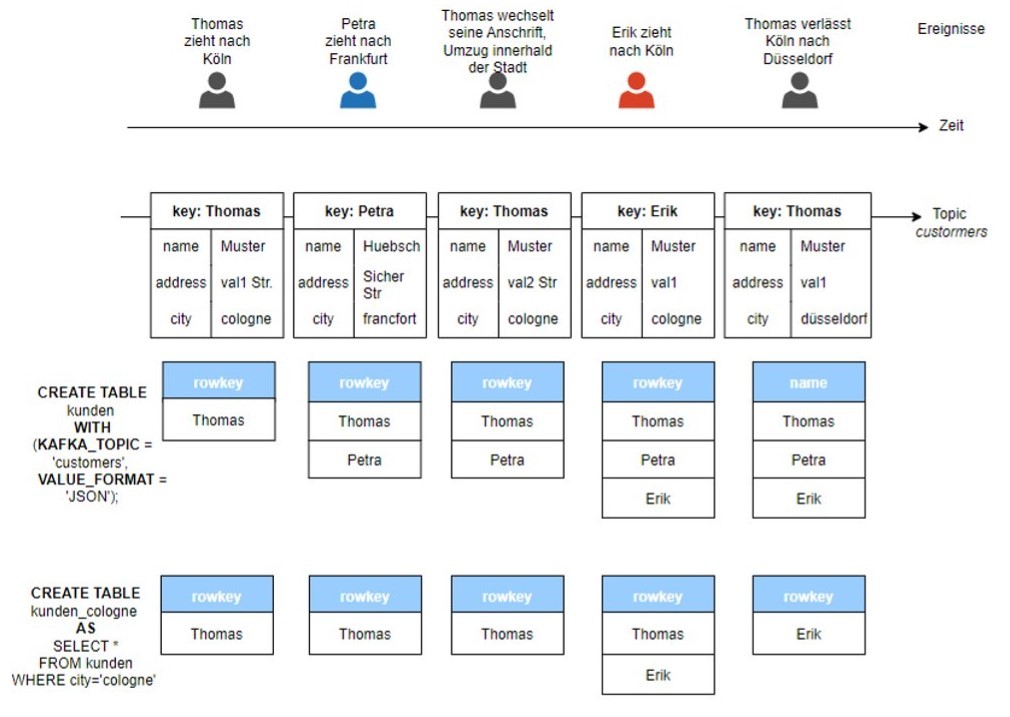
Wenn das Topic „customers“ aktualisiert wird, werden die vom Topic abgeleiteten Tabellen „kunden“ und „kunden_cologne“ entsprechend angepasst.
Das Beispiel (siehe Abbildung 2) veranschaulicht auch, wie definierte Programme kontinuierlich über unbegrenzte Ströme von Ereignissen arbeiten (ad infinitum). Sie stoppen erst, wenn sie explizit beendet werden.
Keine Programmierung notwendig, keine JVM notwendig
Bislang haben wir die Producer-, Consumer- und Streams-APIs als Möglichkeiten für die Arbeit mit Datenströmen kennengelernt. All diese Ansätze erfordern eine Form der Programmierung in einer Programmiersprache wie Java oder Python. ksqlDB und KSQL senken die Einstiegshürde in die Welt der Stream-Verarbeitung und bieten eine einfache und vollständig interaktive SQL-Schnittstelle für die Verarbeitung von Daten in Kafka. Es ist nicht mehr erforderlich, Code zu schreiben. Es genügt, eine ANSI-SQL-basierte Sprache zu verwenden, die sehr weit verbreitet ist und eine größere Akzeptanz und Verwendung in verschiedenen Rollen der IT hat.
Durch die Verwendung von SQL anstelle einer Programmiersprache entfällt die Notwendigkeit einer JVM für die Ausführung einer Stream-Processing-Anwendung. Mit ksqlDB kann man kontinuierlich aktualisierte und materialisierte Views von Daten in Kafka erstellen und diese Materialisierungen auf diverse Weise mit SQL-basierter Semantik abfragen.
SQL, das Allzweckwerkzeug: deklarativer Ansatz, die SQL Schnittstelle und vereinfachte Logik
Als deklarative Abfragesprache wird in SQL definiert, was abgefragt werden soll und nicht, wie dies geschehen soll. Mit diesem deklarativen Ansatz verbirgt ksqlDB Details über interne Implementierungen und die Art und Weise, wie die Ausgabe erstellt wird, sodass Benutzer und Entwickler nur das gewünschte Ergebnis berücksichtigen müssen. Dies ist auch ein weiterer Vorteil von ksqlDB (und KSQL). Durch die Anpassung von SQL an Streaming-Anwendungsfälle profitiert ksqlDB von allen bekannten Vorteilen von Systemen, die klassisches SQL verwenden:
- prägnante und ausdrucksstarke Syntax, die sich wie englische Sprache liest
- deklarativer Programmierstil
- eine niedrige Lernkurve
Die Verwendung von SQL als Abfragesprache ermöglicht eine Nutzung von Datenstromprozessierung durch ein breiteres Publikum. SQL ist in der Industrie weit verbreitet und wird nicht nur von Entwicklern verwendet. So können nicht nur Entwickler intuitiv Daten abfragen und verarbeiten.
Darüber hinaus ermöglicht ksqlDB eine Steigerung der Produktivität bei der Anwendungsentwicklung. Die "Entwicklung" einer Stream-Processing-Anwendung nimmt weniger Zeit in Anspruch und der interaktive Charakter von SQL ermöglicht schnellere Feedback-Schleifen, funktionsübergreifende Tests und Überprüfungen. Die Arbeit ist nicht mehr allein von den Entwicklern abhängig. Die gewünschte Logik und die Funktionalitäten können von einem größeren Team von Personen implementiert und getestet werden.
Unterstützung von ETL-Prozessen durch Integration verschiedener Kafka-Komponenten
ksqlDB integriert Kafka Streams und Kafka Connect in einer einzigen Lösung. Zur Erinnerung: Kakfa Streams ermöglicht Benutzern die Entwicklung von Stream-Processing-Logik und Kafka Connect bietet die Integration externer Systeme.
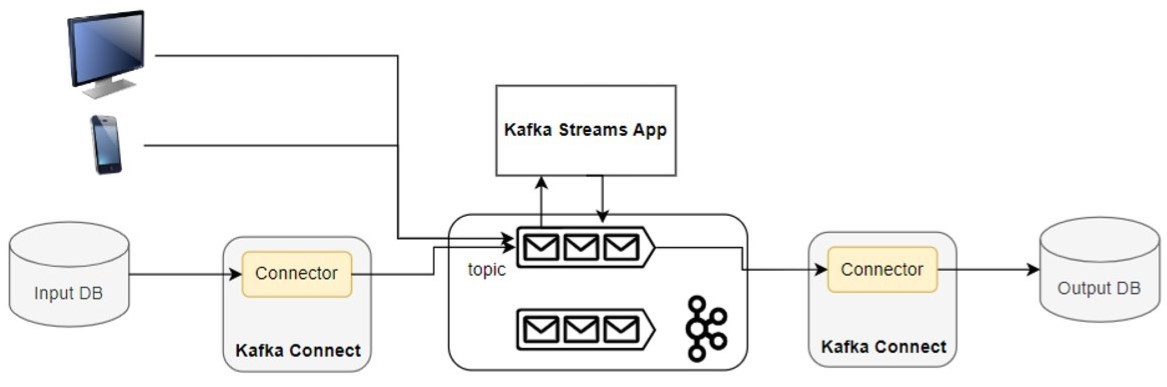
Abbildung 3 zeigt ein Beispiel für ein Szenario, in dem externe Daten in Kafka von einer Kafka-Streams-Anwendung verarbeitet werden und die Ausgabe der Anwendung in eine Senke (Datenbank) geschrieben wird. Daten aus verschiedenen Benutzeroberflächen und einer Datenbank werden zur weiteren Verarbeitung in Kafka Topics gespeichert. Dies ist ein typisches Szenario, in welchem Daten aus externen Quellen und Kafka Topics verarbeitet werden sollen.
Datenpipelines werden benötigt, um Daten von und zu den jeweiligen Systemen zu transportieren. Kafka Connect wird in der Regel als Unterstützung für ETL-Prozesse verwendet, um die Extraktion von Daten aus zahlreichen Quellen und das Laden der verarbeiteten Daten in zahlreiche Senken zu ermöglichen. Es bietet eine automatische Möglichkeit, Daten aus externen Quellen (Extraktionsprozess) in Topics zu laden und Topics-Daten in Zielsysteme zu schreiben.
Die Entwickler müssen dazu folgende Aufgaben erledigen:
- Source-Konnektoren bereitstellen, um die Daten aus der Quelldatenbank zu extrahieren und die Ergebnisse in die gewünschte Senke (Datenbank) zu schreiben
- eine Producer-Anwendung implementieren, um Daten von Benutzeroberflächen in ein Kafka-Topic zu schreiben
- eine Anwendung zur Verarbeitung von Datenströmen mit Kafka Streams implementieren, um alle Daten zu verarbeiten, wobei der Sink-Connector verwendet wird, um das Ergebnis in die Senke zu schreiben
- ein Kafka Connect Deployment bereitzustellen und aufrechtzuerhalten. Für die Ausführung von Kafka Connect ist eine externe separate Installation erforderlich und Entwickler und Teams müssen sicherstellen, dass geeignete Sink- und Source-Konnektoren bereitgestellt werden.
Die Integration und Nutzung von Kafka-fremden Datenquellen in KSQL erfordert eine höhere architektonische Komplexität und einen betrieblichen Mehraufwand. Dieser Mehraufwand entsteht durch die Bereitstellung von einem separaten Overlay-System (Kafka Connect-Installation) und durch die Bereitstellung und Verwaltung aller notwendigen Konnektoren.
Der Übergang von KSQL zum fortgeschrittenen ksqlDB geht mit dem Hinzufügen einer Kafka-Connect-Integration innerhalb der Architektur einher. Es wurden zusätzliche SQL-Konstrukte definiert, um nicht nur Quell- und Senke-Konnektoren zu spezifizieren, sondern auch um auf einfache Weise definierte Konnektoren in Abfragen zu verwenden. Es ist auch möglich, von einer ksqlDB-Anwendung (oder einer ksqlDB-Abfrage) Konnektoren in einem extern bereitgestellten Kafka-Connect-Cluster zu verwalten und auszuführen oder einen verteilten Kafka-Connect-Cluster neben einer ksqlDB-Installation für eine noch einfachere Einrichtung zu betreiben.
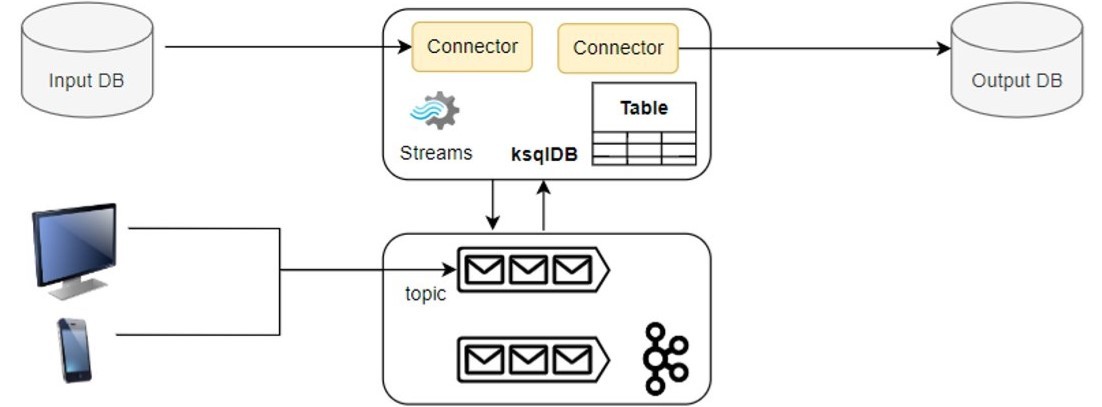
Die Abbildung 4 zeigt den Unterschied, den ksqlDB in die Stream-Verarbeitung einbringt. Im Gegensatz zu Abbildung 3 sind die Funktionen, die von der Kafka Streams App und den verschiedenen Konnektoren ausgeführt werden, in ksqlDB integriert. Die Daten aus den Benutzerschnittstellen und der Eingabequelle werden innerhalb einer einzigen Anwendung verarbeitet.
ksqlDB unterstützt den gesamten ETL-Lebenszyklus. Sie deckt den Transformationsteil durch die Kafka-Streams-Integration und den Extraktions- und Ladeteil durch die Kafka-Connect-Integration ab. Einfach ausgedrückt: ETL-basierte Anwendungen lassen sich vollständig mit ksqlDB umsetzen. Mithilfe von SQL-Abfragen in ksqlDB können Benutzer Quellen- und Senken-Konnektoren definieren, aus den Quellen extrahieren, Datenströme verarbeiten und die Ergebnisse an die Senken zurückschreiben.
Zusammenfassung & Ausblick
ksqlDB ist "die Streaming-Datenbank für Apache Kafka". Sie vereinfacht die Erstellung von Stream-Processing-Anwendungen durch:
- die Integration von Producer, Consumer, Streams, Connect APIs, Datenabstraktionen und interner Organisation
- die Verwendung von SQL
Dieser Artikel gibt einen Überblick über ksqlDB und stellt einige seiner Vorteile vor. Er beantwortet damit die Frage nach den Vorteilen einer zusätzlichen Stream-Processing-Lösung und dem Unterschied zwischen diesem neuen Ansatz und Kafka Streams. Dieser Artikel ist Teil einer 3-teiligen Serie.
Der nächste Artikel wird einen tieferen Einblick in ksqlDB und seine Architektur geben.
Seminarempfehlung
APACHE KAFKA GRUNDLAGEN KAFKA-01
Zum SeminarSenior Chief Consultant bei ORDIX
Kommentare