
Micro-Batching oder Event-Driven? So wählt ihr die richtige Streaming-Architektur
Stellt euch vor, ihr leitet ein Unternehmen, das täglich Millionen von Daten aus verschiedensten Quellen erhält – seien es Social Media, Sensoren in der Produktion, Finanztransaktionen oder Logdaten von IoT-Geräten. Diese Daten sind eine wertvolle Ressource, doch ihr wahres Potenzial entfaltet sich erst, wenn sie nicht nur gesammelt, sondern in Echtzeit verarbeitet werden. Genau hier setzt die Streaming-Verarbeitung an. Während die klassische Batch-Verarbeitung Daten in festen Intervallen sammelt und verarbeitet, ermöglicht Streaming die unmittelbare Verarbeitung einzelner Datenpunkte. Technologien wie Apache Spark Streaming und Apache Kafka Streams bieten hier mächtige Werkzeuge, um den Datenfluss zu beherrschen und essenzielle Einblicke in kürzester Zeit zu gewinnen. Doch wie wählt man die richtige Streaming-Architektur?
Architektur & Design
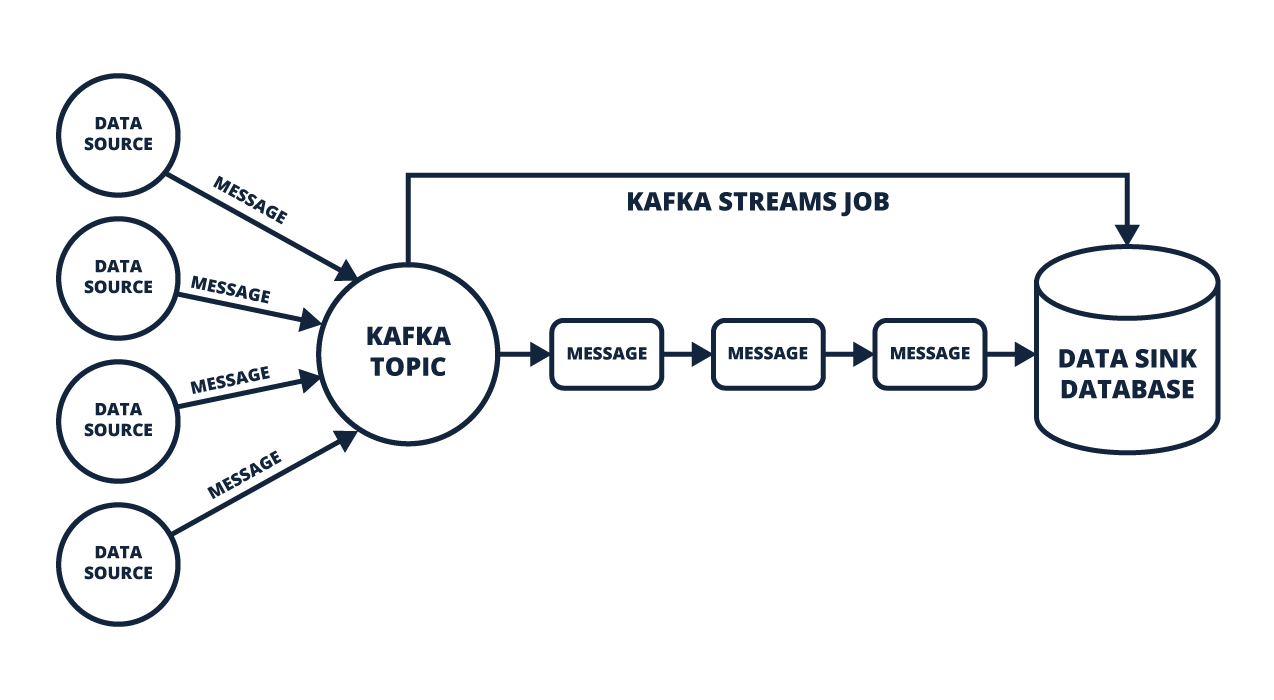
Kafka Streams verfolgt den Ansatz des „Event-Driven Processing“. Hier wird jedes Ereignis („Event“) sofort verarbeitet, ohne auf die Sammlung mehrerer Events zu warten. Diese Architektur eignet sich ideal für Szenarien, in denen sofortige Reaktionen gefragt sind – etwa bei der Erkennung von Betrugsversuchen in Finanztransaktionen oder bei der Überwachung von Maschinen in Echtzeit. Kafka Streams gewährleistet dabei „Exactly Once Semantics“, wodurch jedes Event nur einmal verarbeitet wird. Ergänzt durch eingebaute Mechanismen zur Fehlerbehandlung, State Stores zur Zwischenablage von Daten und Datenreplikation, bietet Kafka Streams eine hohe Zuverlässigkeit. Hinzu kommt die Möglichkeit, Aggregationen, Filterungen und Joins in Echtzeit durchzuführen, was Kafka Streams zu einer äußerst flexiblen Lösung macht.
Stream-Verarbeitung
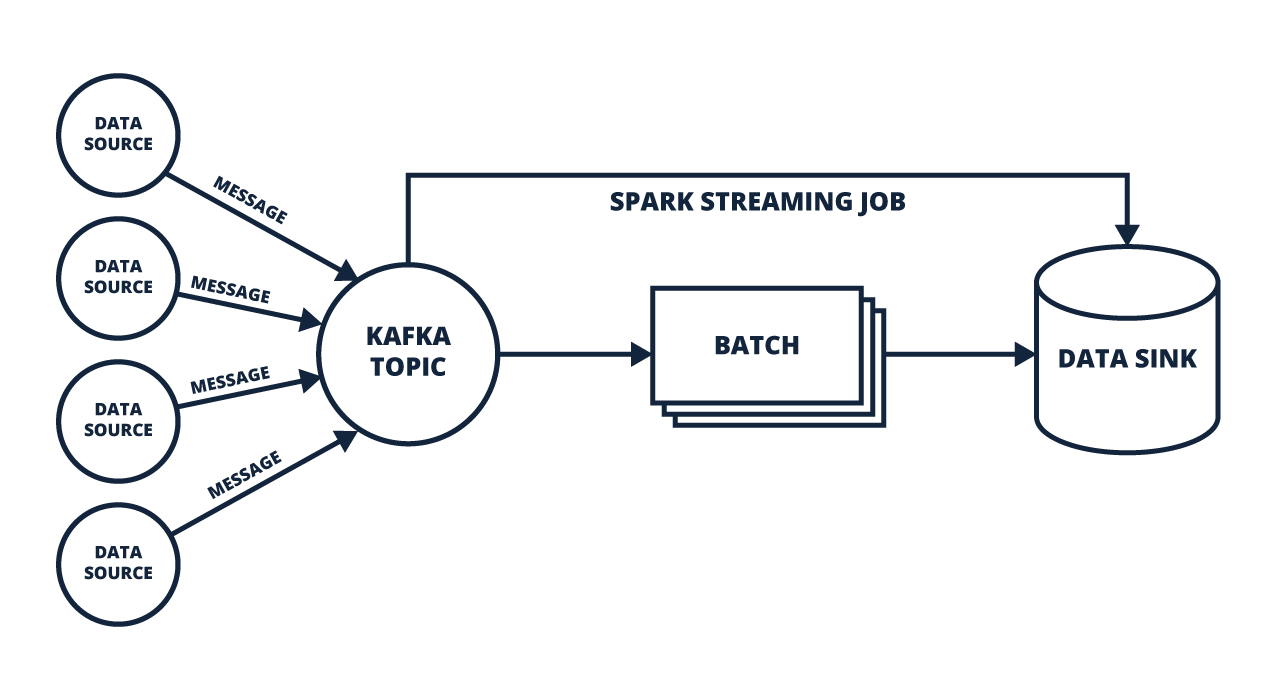
Spark Streaming basiert auf dem Konzept des sogenannten „Micro-Batching“. Dabei werden eingehende Daten in kleinen Paketen („Batches“) gebündelt und anschließend sequenziell verarbeitet. Der Vorteil dieses Ansatzes liegt in der parallelen Verarbeitung großer Datenmengen auf mehreren Computern. Hier kommen die „Resilient Distributed Datasets“ (RDDs) ins Spiel – fehlertolerante Datensätze, die bei einem Ausfall automatisch wiederhergestellt werden. Structured Streaming erweitert diesen Ansatz, indem es Daten als kontinuierlichen Fluss behandelt und gleichzeitig die einfache API von Spark beibehält. Zudem ermöglicht es das Verarbeiten von Daten in definierten Zeitfenstern („Sliding Windows“), wodurch sich Muster und Trends identifizieren lassen.
Ein Vergleich zwischen klassischer Batch-Verarbeitung und Micro-Batching verdeutlicht die Unterschiede: Während bei der Batch-Verarbeitung Daten in großen Blöcken gesammelt und in festgelegten Zeitintervallen wie zum Beispiel einer Stunde oder einmal am Tag analysiert werden, ermöglicht Micro-Batching eine nahezu Echtzeit-Verarbeitung durch die Aufteilung in kleine, schnell verarbeitbare Pakete. Spark Streaming kombiniert so die Effizienz der Batch-Verarbeitung mit der Reaktionsgeschwindigkeit des Streamings. Zusätzlich kann es durch „Watermarking“ auch verspätete Daten effizient verarbeiten und korrekt in den Datenfluss integrieren.
Micro-Batch-Verarbeitung
Performance & Latenz
Latenz – die Zeitspanne zwischen dem Eintreffen eines Datenpunkts und seiner Verarbeitung – ist ein wesentlicher Faktor für die Performance von Streaming-Systemen. Bei Spark Streaming variiert die Latenz je nach Größe der Batches: Größere Batches erhöhen den Durchsatz, führen jedoch auch zu Verzögerungen. Kleinere Batches reduzieren die Latenz, beanspruchen jedoch mehr Rechenressourcen. Kafka Streams arbeitet hingegen ohne Batches und verarbeitet jedes Event unmittelbar, was zu einer signifikant niedrigeren Latenz für das einzelne Element führt. Daher eignet sich Kafka Streams besonders für Anwendungen, mit besonders hohen Ansprüchen in diesem Punkt. Hinzukommt, dass Kafka Streams durch seine native Integration in Apache Kafka die gesamte Pipeline von der Datenerfassung bis zur Verarbeitung und Speicherung abdeckt.
Integration & Kompatibilität
Spark Streaming lässt sich nahtlos mit anderen Komponenten des Spark-Ökosystems kombinieren – etwa Spark SQL für die Analyse strukturierter Daten, MLlib für maschinelles Lernen und GraphX für die Graphdatenanalyse. Diese Integration ermöglicht die Entwicklung komplexer Datenpipelines, die Echtzeit- und Batch-Verarbeitung vereinen. Zusätzlich kann Spark Streaming Datenquellen wie HDFS, S3, Kafka und viele weitere direkt anbinden.
Kafka Streams arbeitet direkt auf sogenannten Kafka Topics – Nachrichtenkanälen, in denen Daten in Echtzeit publiziert und abonniert werden können. Diese Architektur passt perfekt zu Microservices-Strukturen, in denen jeder Dienst seine eigenen Events produziert und konsumiert. Hinzu kommt die Möglichkeit, verschiedene State Stores zu verwenden, um Aggregationen und Zustände zwischen verschiedenen Streams zu verwalten. Zudem kann Kafka Streams auch problemlos mit ksqlDB kombiniert werden, was die Erstellung von SQL-ähnlichen Abfragen für Streaming-Daten ermöglicht.
Fazit
Sowohl Spark Streaming als auch Kafka Streams bieten leistungsstarke Ansätze zur Datenstromverarbeitung, unterscheiden sich jedoch grundlegend in ihrer Herangehensweise. Spark Streaming punktet durch seine Batch-Verarbeitung, die umfassende Integration ins Spark-Ökosystem und die Fähigkeit, auch große Datenmengen parallel zu verarbeiten. Kafka Streams hingegen überzeugt durch seine Event-Driven Architektur, niedrige Latenz und die Möglichkeit, auf Ereignisebene Entscheidungen zu treffen. Die Wahl der richtigen Technologie hängt somit stark von den spezifischen Anforderungen ab. Geht es zum Beispiel um die Analyse großer Datenmengen mit maschinellem Lernen, ist Spark Streaming die bessere Wahl. Steht hingegen die sofortige Reaktion auf Echtzeit-Ereignisse im Fokus, ist Kafka Streams eine sehr gute Wahl. Für hybride Anwendungsfälle könnte auch die Kombination beider Systeme sinnvoll sein, um die jeweiligen Stärken optimal zu nutzen.
Seminarempfehlungen
APACHE KAFKA GRUNDLAGEN KAFKA-01
Mehr erfahrenAPACHE KAFKA EINE EINFÜHRUNG – KOSTENLOSES WEBINAR W-KAFKA-02
Mehr erfahrenJunior Consultant
Kommentare