
Chatbots: Missverstehen, aber richtig.
Wie können Chatbots Menschen verstehen? Sogar mit Tippfehlern!
Chatbots können als Schnittstelle zwischen der menschenverständlichen Sprache und einer strukturierten maschinenlesbaren Repräsentation ebendieser verstanden werden.
In diesem Artikel wird anhand von Beispielen erläutert in welche Teilprozesse sich der Verständnisprozess eines Chatbots unterteilt. Dabei werden einige gängige Verfahren zur Realisierung dieses Prozesses vorgestellt. Zudem werden Methoden präsentiert, anhand derer eine robuste Verarbeitung trotz etwaigen Schreibfehlern möglich ist.
Natural Language Understanding (NLU)
Menschen sind sehr gut darin, aus verschiedenen Formulierungen die darin kodierte Absicht (Intent) und etwaige Entitäten zu ermitteln.
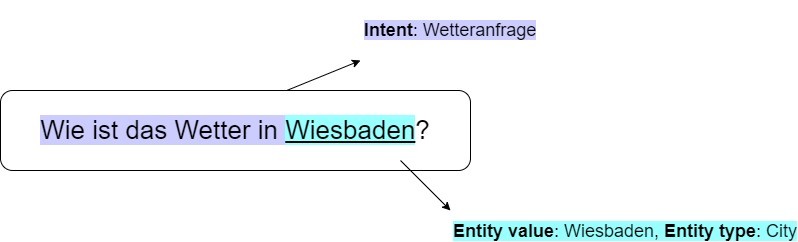
Um es einem Chatbot zu ermöglichen diese Informationen zu extrahieren, müssen die vielen möglichen Formulierungen zunächst in eine strukturierte, maschinenlesbare Form gebracht werden. Im Folgenden können dann Methoden des NLU angewendet werden, um die Intent und die Entitäten (Named Entities) zu bestimmen.
Intent-Erkennung
Die Intent-Erkennung ist ein zentraler Teilprozess eines Chatbots. Dabei müssen dem Chatbot mit Hilfe von Beispielen (Trainingsdaten) die gewünschten Intents beigebracht werden:
„Wie ist das Wetter in Wiesbaden": "Wetteranfrage",„Ich hätte gerne eine Pizza": „Pizzabestellung",
…
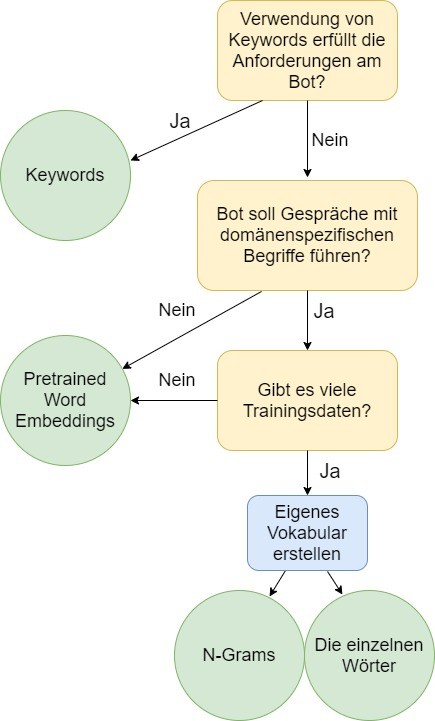
Keywords
Der Intent wird durch die vordefinierten Schlüsselworte im User-Input bestimmt.
Beispiel: Taucht das Wort „Wetter" im User-Input auf, wird der Intent als „Wetteranfrage" gesetzt, unabhängig von der restlichen Nachricht.
Eigenes Vokabular
Liegen genug repräsentative Trainingsdaten vor, können aus diesen eigene Featurevektoren gebildet werden. Ein einfacher Ansatz ist die sogenannte Bag-of-Words-Methode, bei derer schlicht die absoluten Häufigkeiten der "Tokens" der Trainingsdaten gebildet werden.
Zwei mögliche Verfahren, diese Tokens zu bilden, sind:
a) Wörter
Beispiel: „Wie", „ist", „das", „Wetter", „in", „Wiesbaden"
b) N-Gramme
Hier werden die Daten nicht direkt in Wörter unterteilt, sondern in Zeichenketten der Länge N. Dabei kann bestimmt werden, ob diese lediglich über zusammenhängende Wörter oder die gesamte Zeichenkette gebildet werden.
Beispiel für 2-Grams (Wörter):
"Wie ist", "ist das", "das Wetter", "Wetter in", "in Wiesbaden"
Beispiel für 3-Grams (Zeichen):
"Wie", "ist", "das", "Wet", "ett", "tte", "ter", "in", "Wie", "ies", "esb", …
Pretrained Word Embeddings
Dies sind bereits durch verschiedene maschinelle Lernverfahren vortrainierte Vektorrepräsentationen, welche auf einer sehr großen Datenmenge gebildet wurden. Dabei werden meist implizit aus den Strukturen der Daten Features gebildet, anstatt diese vorzugeben.
Um den Kontext innerhalb einer Konversation zu bewahren, können auch zuvor bestimmte Intents als Features kodiert werden.
Die so kodierten Trainingsdaten werden nun an einen Klassifikationsalgorithmus weitergegeben, um die gewünschten Intents zu lernen. Werden im Anschluss neue Daten an den Klassifikator gegeben, kann dieser nun den Intent klassifizieren.
Welcher Klassifikationsalgorithmus gewählt werden sollte, ist immer abhängig vom konkreten Szenario. Eine gute Faustregel ist jedoch iterativ mit dem simpelsten Modell anzufangen und die Ergebnisse mit den Anforderungen zu vergleichen. So kann das einfachste Modell gewählt werden, welches die Anforderungen erfüllt.
Named Entity Recognition (NER)
„A named entity is a "real-world object" that's assigned a name – for example, a person, a country, a product or a book title ". [1]
Ähnlich wie bei der Intent-Erkennung wird auch hier auf den gelernten Vektorrepräsentationen der Trainingsdaten ein Klassifikator angewendet, um die Tokens zu bestimmen, welche einer Entität entsprechen.
Einen Überblick über gängige NER-Methoden kann im Abschnitt „Named Entity Recognition" im Beitrag „Tabula Rasa – Mit Chatbots Kundenkommunikation neu denken" gefunden werden.
Im Folgenden wird ein Beispiel gezeigt, wie mögliche Featurevektoren aussehen könnten, um die Entität „Geld" zu erkennen.
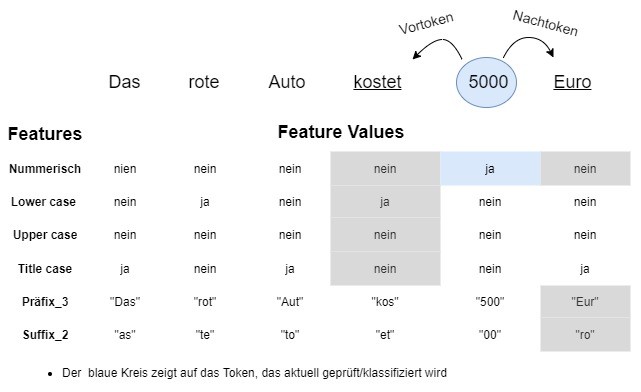
Verstehen trotz Tippfehlern: Wie gelingt Das einem Chatbots?
Die Intent-Erkennung verzeiht oft mehrere Tippfehler, da diese sich erst kritisch auf die Klassifizierung auswirken, wenn diese in vom Klassifikator als wichtig erachteten Wörtern auftreten. Um das Risiko weiter zu minimieren, bieten sich N-Gramme an, wobei auch hier mit verschiedenen N-Werten experimentiert werden sollte, um eine hohe Überlappung von N-Grammen in unterschiedlichen Worten zu vermeiden.
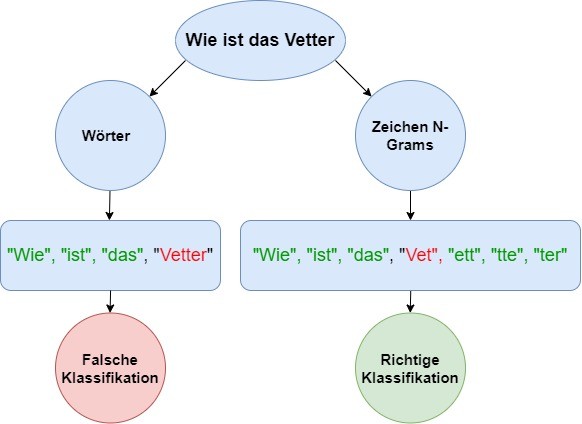
Dieser Ansatz kann auch für die Erkennung von Entitäten hilfreich sein. Existieren jedoch endliche Aufzählungen der gültigen Ausprägungen von Entitäten, kann zudem ein sogenanntes Fuzzy-Matching durchgeführt werden. Hierfür bietet sich die Bibliothek „fuzzywuzzy" an [2], welche Methoden bereitstellt, anhand derer die Ähnlichkeit zwischen Strings auf Grundlage der Levenshtein-Distanz berechnet werden.
Das Modul „fuzz" hat vier verschiedene Methoden, um einen Matching-Score zwischen zwei Strings zu liefern:
Die Methode rechnet die "Levenshtein distance similarity ratio" zwischen zwei Strings.
str1 = "company ag"
str2 = "company a"
ratio_score = fuzz.ratio(str1, str2)
print("ratio_score: ", ratio_score)
>>> ratio_score: 95
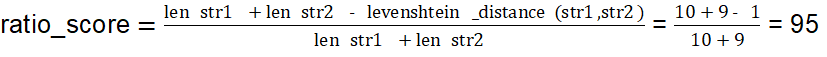
2- partial_ratio(str1, str2).
Hier wird der beste ratio-score zurückgeliefert, zwischen dem kürzeren String (Länge x) und aller Substrings des zweiten Strings, die die Länge x haben.
str1 = "Bank"
str2 = "Beispiel Bank"
ratio_score = fuzz.ratio(str1, str2)
partial_ratio_score = fuzz.partial_ratio(str1, str2)
print("ratio_score: ", ratio_score)
print("partial_ratio_score: ", partial_ratio_score)
>>> ratio_score: 47
>>> partial_ratio_score: 100
Die Methode token_sort_ratio() führt folgende Preprocessing-Schritte durch:
- Filtert die Strings (nur Buchstaben und Ziffern bleiben)
- Verwandelt sie in lower case,
- Trimmt Leerzeichen
- Tokenisiert die Strings, sortiert sie alphabetisch und fügt sie wieder zusammen
str1 = "Banana Apple Data"
str2 = "Data, banana apple"
token_sort_ratio_score = fuzz.token_sort_ratio(str1, str2)
print("token_sort_ratio_score: ", token_sort_ratio_score)
>>> token_sort_ratio_score: 100
4- token_set_ratio(str1, str2)
Die Methode ist geeignet, wenn ein großer Unterschied in der Länge der beiden Strings besteht.
Die Methode token_set_ratio() führt folgende Preprocessing-Schritte durch:
• Filtert die Strings (nur Buchstaben und Ziffern bleiben)
• Verwandelt sie in lower case
• Trimmt Leerzeichen
• Entfernt Duplikate
• Sortiert die Tokens alphabetisch und fügt sie wieder zusammen
Dann wird die Methode ratio() auf folgende Strings aufgerufen:
S1 = Sorted_tokens_in_intersektion_between_str1_and_str2
S2 = S1 + sorted_rest_of_str1_tokens
S3 = S1 + sorted_rest_of_str2_tokens
token_set_ratio_score = max(fuzz.ratio(S1,S2), fuzz.ratio(S1,S3), fuzz.ratio(S2, S3))
str1 = "max mustermann"
str2 = "Viele Menschen waren da auch Max Mustermann"
token_set_ratio_score = fuzz.token_set_ratio(str1, str2)
print("token_set_ratio_score: ", token_set_ratio_score)
>>> token_set_ratio_score: 100
Fazit
In diesem Artikel wurde der NLU-Prozess von Chatbots und seine unterliegenden Teilprozesse erklärt, anhand von Bespielen erläutert und die wichtigsten Ansätze zur Realisierung dieses Prozesses aufgezählt. Zudem wurden für die Problematik von Tippfehlern Lösungen vorgeschlagen und vorgestellt.
Sie haben Interesse an einer Weiterbildung oder Fragen zum Thema Machine Learning? Sprechen Sie uns an oder besuchen Sie einen unserer Kurse aus unserem Seminarshop:
Zu unseren Big-Data-Seminaren
Kommentare