
Neuigkeiten im Überblick - Apache Hadoop 3 (Teil 2)
Fortsetzung des Blogartikels Neuigkeiten im Überblick - Apache Hadoop 3 (Teil 1)
Wir geben einen Überblick über die Neuerungen und beleuchten die wichtigen Features der neuen Hadoop-Version.
Konfiguration mehrerer HDFS NameNodes
Die Konfiguration mehrerer NameNodes erfolgt über die core-site.xml und hdfs-site.xml. Folgende Properties müssen gesetzt werden:
core-site.xml
| fs.defaultFS | Name-Service für den HDFS Cluster Beispiel: hdfs://democluster |
| ha.zookeeper.quorum | Für automatisches Failover: Zookeeper-Nodes mit Portangabe Beispiel: zk1.demo.net:2181,zk2.demo.net:2181, zk3.demo.net:2181 |
hdfs-site.xml
| dfs.ha.automatic-failover | Automatisches Failover mit ZKFC mit „true" aktivieren. Für manuelles Failover auf „false" setzen. |
| dfs.namenservices | Name-Service des HDFS Cluster (fs.defaultFS, ohne „hdfs://") Beispiel: democluster |
| dfs.ha.namenodes.<hdfs-alias> | Liste an Aliase für NameNodes Beispiel: nn1, nn2, nn3 |
| dfs.namenode.rpc-address. <hdfs-alias>.<namenode-alias> | RPC-Adresse und -Port des jeweiligen NameNodes pro NameNode-Alias Beispiel: namenode1.ordix.de:9820 |
| dfs.namenode.http-address.<hdfs-alias>.<namenode-alias> | HTTP-Adresse und -Port des jeweiligen NameNodes pro NameNode-Alias Beispiel: namenode1.ordix.de:9870 |
| dfs.namenode.shared.edits.dir | Edit-Verzeichnis und JournalNode-Quorum Beispiel: qjournal://journalnode1.ordix.de:port, journalnode2.ordix.de:port,.../democluster |
| dfs.journalnode.edits.dir | Verzeichnispfad für Edit-Logs der JournalNodes Beispiel: /hadoop/journalnode/edits |
Inbetriebnahme mehrerer HDFS NameNodes
Werden Cloudera CDH oder Hortonworks HDP verwendet, übernehmen die jeweiligen Cluster Manager den korrekten Start der jeweiligen Komponenten. In diesem Abschnitt wird der Start im Detail beschrieben, wie er mit der Open- Source-Version durchgeführt werden kann.
Vor dem Start der NameNodes werden die JournalNodes gestartet, um ein Quorum JournalNodes zu ermöglichen. Ein NameNode wird dann genutzt, um das HDFS zu formatieren. Wie gehabt wird dabei der Befehl
hdfs namenode -format verwendet. Anschließend kann dieser NameNode gestartet werden.
Die weiteren NameNodes beziehen den Dateiindex (fsimage) über den als Erstes gestarteten NameNode. Dazu werden die weiteren NameNodes vor dem Start mit folgendem Befehl bootstrapped: hdfs namenode -bootstrapStandby aufgegrufen. Danach werden die NameNodes normal gestartet.
Die Reihenfolge zusammengefasst:- Start aller JournalNodes
- Formatierung des HDFS durch den ersten NameNode
- Starten des ersten NameNodes
- Bootstrap der weiteren NameNodes
- Start der weiteren NameNodes
- Bei automatischem Failover: Start der ZKFCs
Festplatten mit Intra DataNode Diskbalancer gleichmäßig auslasten
Pro DataNode werden die HDFS-Nutzdaten auf mehreren Festplatten verteilt. Bisher gab es jedoch keine Möglichkeit, eine Imbalance, beispielsweise durch den Austausch einer Festplatte, zu begradigen. Ungleichmäßig ausgelastete Festplatten (auch Skew genannt) verringern die Lebensdauer einzelner Festplatten und bremsen die Schreib- und Leseperformance.
Hadoop 3 schafft hier Abhilfe durch den Intra DataNode Diskbalancer, der es ermöglicht, die Datenblöcke über die Festplatten wieder gleichmäßig zu verteilen. Die Neuverteilung kann zunächst durch einen Plan erstellt, aber zu einem späteren Zeitpunkt ausgeführt werden.
Vor der Verwendung muss in der hdfs-site.xml der Intra DataNode Balancer aktiviert werden, in dem die Property dfs.disk.balancer.enabled auf true gesetzt wird.
Der Intra DataNode Balancer im Praxisbeispiel
Wir zeigen ein Praxisbeispiel für das pro DataNode drei sehr kleine virtuelle Festplatten über zwei Mountpoints eingebunden werden. In der HDFS Konfiguration sind zunächst aber nur zwei der drei Festplatten eingebunden. Zusätzlich wird die HDFS-Blockgröße mit 32 MB besonders klein gewählt.
hdfs-site.xml
<configuration>
[...]
<property>
<name>dfs.datanode.data.dir</name>
<value>/hadoop/disk1,/hadoop/disk2</value>
</property>
<property>
<name>dfs.disk.balancer.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>33554432</value> <!-- 32 MB blocksize -->
</property>
[...]
</configuration>
Die ersten beiden Festplatten werden nun mit HDFS-Nutzdaten ausgelastet. Die dritte Festplatte hat derzeit noch keine Verwendung.
[hadoop@datanode1 hadoop]$ df -h Filesystem Size Used Avail Use% Mounted on [...] /dev/loop0 239M 196M 27M 89% /hadoop/disk1 /dev/loop1 239M 196M 27M 89% /hadoop/disk2 /dev/loop2 239M 2.1M 220M 1% /hadoop/disk3
Nun wird die dritte Festplatte eingebunden. Die Datenblöcke sind nun über alle drei Festplatten ungleichmäßig verteilt.
[...] <property> <name>dfs.datanode.data.dir</name> <value>/hadoop/disk1,/hadoop/disk2,/hadoop/disk3 </value> </property> [...]
Die Sektion Volume Information der DataNode-Webseite gibt uns Informationen über die eingebundenen Festplatten und die Datenblock-Verteilung (siehe Abbildung 3). Zu erkennen ist, dass die dritte Festplatte über keine
Datenblöcke verfügt.
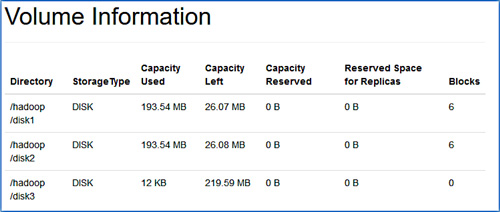
Vom NameNode aus wird nun ein Plan zum Verteilen der Daten erstellt. Dies kann aber auch auf dem DataNode direkt geschehen. Der Plan wird als JSON-Datei im HDFS abgelegt. Das Erstellen des Plans verbraucht noch keine Cluster-Ressourcen und kann von der tatsächlichen Ausführung unabhängig ausgeführt werden.
Weil die Umverteilung größerer Datenmengen mehr Zeit in Anspruch nimmt, kann mit der Option -query der Zustand der Umverteilung abgefragt werden.
[hadoop@namenode ~]$ hdfs diskbalancer -plan datanode1 [...] Writing plan to: /system/diskbalancer/2018-Sep-30-10-09-38/datanode1.plan.json [hadoop@namenode ~]$ hdfs diskbalancer -execute /system/diskbalancer/2018-Sep-30-10-09-38/datanode1.plan.json 2018-09-30 10:09:59,179 INFO command.Command: Executing "execute plan" command [hadoop@namenode ~]$ hdfs diskbalancer -query datanode1 2018-09-30 10:10:14,129 INFO command.Command: Executing "query plan" command. Plan File: /system/diskbalancer/2018-Sep-30-10-09-38/datanode1.plan.json Plan ID: aaa963209fec294013ff28e2922e24cdd5f22b49 Result: PLAN_DONE
Nach erfolgreicher Ausführung des Balancierens ist nun auf der Webseite des DataNode zu erkennen, dass die Daten gleichmäßig über alle Festplatten verteilt sind (siehe Abbildung 4).
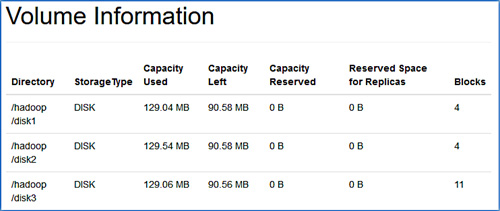
Der Diskbalancer bietet darüber hinaus noch weitere Optionen:
- Versatz-Toleranz: Wie viel % darf die Festplattenauslastung vom Durchschnitt abweichen, bevor ein Plan zur Ausbalancierung erstellt werden muss?
- Fehlertoleranz: Wie viele Fehler werden bei der Ausführung des Plans toleriert, bevor er abgebrochen werden muss?
- Bandbreiten-Begrenzung: Wie hoch darf die Datentransferrate maximal sein (MB pro Sekunde)?
- Mit dem Intra DataNode Diskbalancer und dem bereits vorhandenen HDFS Balancer, wird nun mehr Flexibilität bei der horizontalen, aber auch vertikalen Speicherskalierung angeboten. Das Ausbalancieren lässt sich dabei im Voraus planen und zu günstigen Zeitpunkten ausführen.
Links/Quellen
[Q1] Einführung in Erasure Coding (Cloudera Blog)
http://blog.cloudera.com/blog/2015/09/introduction-to-hdfs-erasurecoding-in-apache-hadoop/
[Q2] Portbelegung Cloudera CDH 6
https://www.cloudera.com/documentation/enterprise/6/6.0/topics/cdh_ports.html
[Q3] HDFS Intra DataNode Disk Balancer (Cloudera Blog)
http://blog.cloudera.com/blog/2016/10/how-to-use-the-new-hdfs-intradatanode-disk-balancer-in-apache-hadoop/
[Q4] Hortonworks HDP Platform 3 Datasheet
https://de.hortonworks.com/datasheet/hortonworks-data-platform-3-0-datasheet/
[Q5] Apache Hadoop Releases
https://hadoop.apache.org/releases.html
[Q6] Apache Hadoop 3 Dokumentation
https://hadoop.apache.org/docs/r3.0.0/index.html
[Q7] Cloudera Unsupported Features
https://www.cloudera.com/documentation/enterprise/6/release-notes/topics/rg_cdh_600_unsupported_features.html#hdfs_600_unsupported
[Q8] Portänderungen (Apache Software Foundation JIRA)
https://issues.apache.org/jira/browse/HDFS-9427
https://issues.apache.org/jira/browse/HADOOP-12811
[Q9] Mapreduce Native Optimization (Apache Software Foundation JIRA)
https://issues.apache.org/jira/browse/MAPREDUCE-2841
[Q10] Migration auf Java 8 (Apache Software Foundation JIRA)
https://issues.apache.org/jira/browse/HADOOP-9902
[Q11] Shellscript Rewrite (Apache Software Foundation JIRA)
https://issues.apache.org/jira/browse/HADOOP-11656
Fortsetzung
Lesen Sie den letzten Teil zu "Neuigkeiten im Überblick - Apache Hadoop 3" hier in unserem Blog. Nicht verpassen!
Kommentare