
Newton: OpenStack endeckt die Gravitation
Was ist OpenStack?
OpenStack ist die derzeit innovativste Cloud-Infrastrukurlösung auf dem Markt. Dies ist zu einem großen Teil auf die OpenStack Foundation zurückzuführen, die die Steuerung des Projekts übernimmt und in der sich mehr als 37.000 Mitglieder zusammengeschlossen haben. Außergewöhnlich ist dabei die Zusammensetzung aus Technologieanbietern, großen Unternehmen, innovativen Cloud-Startups und individuellen Entwicklern.
Bei OpenStack handelt es sich um ein Open-Source-Projekt, das unter der Apache-2.0-Lizenz veröffentlicht wird. Mithilfe von OpenStack lassen sich komplexe Cloud Computing Infrastrukturen aufbauen. Zudem unterstützt es IT-Architekten bei der Orchestrierung und dem Management der Cloud-Umgebung. Entstanden ist das Projekt aus einer Kooperation zwischen der US-amerikanischen Weltraumbehörde NASA und der Firma Rackspace, die jeweils eine Komponente (Computing und Object Storage) entwickelten und diese zu einem Projekt zusammenschlossen.
Architektur
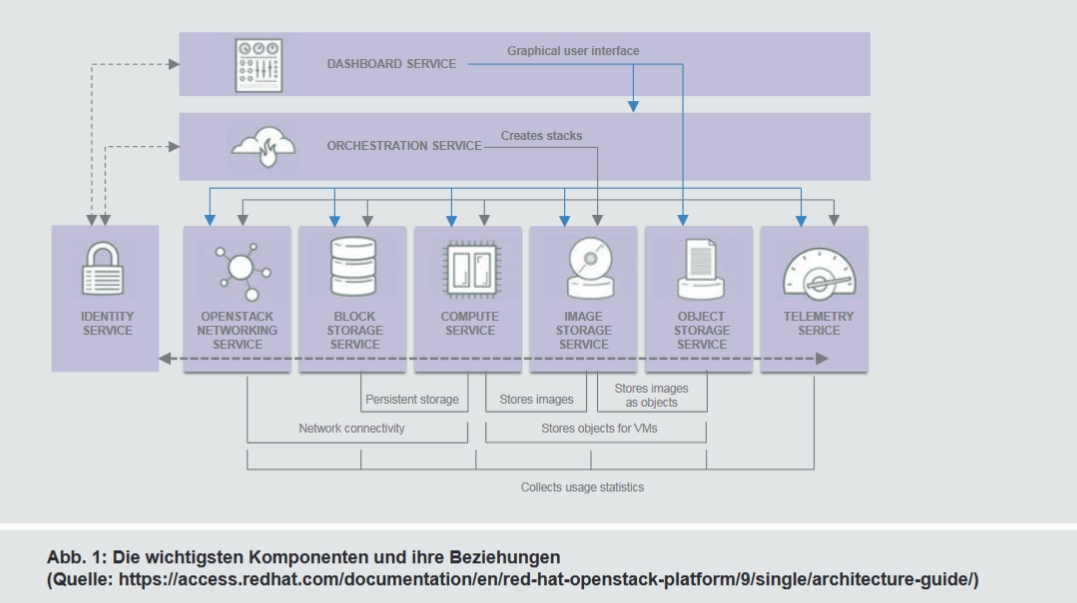
Die OpenStack-Architektur kann in die drei Bereiche Komponenten (Services), Treiber und APIs unterteilt werden. Die wichtigste Aufgabe übernehmen die einzelnen Komponenten, die nur in Kombination eine vollständige Cloud-Infrastruktur-Lösung ergeben und in separaten Teilprojekten entwickelt werden. Die Verwaltung der einzelnen Komponenten und deren Kommunikation untereinander, erfolgt über RESTful APIs. Die wichtigsten Komponenten und deren Zusammenhänge (siehe Abbildung 1) werden im folgenden Abschnitt erläutert.
Einige der OpenStack-Komponenten implementieren eine Treiberschicht. Diese hat die Aufgabe, die Integration und Kommunikation mit externen hardware- und softwarebasierten Infrastrukturkomponenten sicherzustellen. Die Treiber werden entweder direkt von den Herstellern passend zu ihren Lösungen oder von der OpenStack Community entwickelt und bereitgestellt. Die meisten Treiber betreffen die Bereiche Compute, Networking und Storage. Die Treiber für den Bereich Compute dienen in der Regel der Unterstützung von Virtualisierungstechnologien, wie z. B. Microsofts Hyper-V, KVM oder VMware vSphere. Der Bereich Networking deckt, wie der Name schon andeutet, den Support für Netzwerk-Hardware und -Software (u. a. Cisco, Open vSwitch oder VMware NSX) ab. Ebenfalls werden die wichtigsten Speicherlösungen von EMC, Hitachi, NetApp und vielen anderen unterstützt.
Die meisten Services können über drei Wege angesprochen werden. Die benutzerfreundlichste Variante ist das Graphical-User-Interface (GUI), das ein Teil des Dashboards ist. Zudem existiert ein Command-Line-Interface, welches von Administratoren direkt oder in Skripten verwendet werden kann. Im Hintergrund verwenden beide Varianten die API der entsprechenden Komponente. Diese kann auch direkt z. B. von 3rd-party-Applikationen aufgerufen werden und bildet das primäre Interface für die Kommunikation der Komponenten untereinander. Die API ist RESTful und dementsprechend HTTP-basiert und unterstützt JSON- sowie XML-Daten.
Komponenten
Die Aufteilung in einzelne Komponenten, auf Basis der zu erfüllenden Aufgaben, ermöglicht eine flexible Gestaltung der OpenStack-Infrastruktur. Nicht jeder Service wird in jeder OpenStack-Installation benötigt. Die Core-Komponenten, die in den meisten Installationen vorhanden sind, werden in den nächsten Punkten vorgestellt. Intern werden die Services mit einem Codenamen versehen, der sich z. B. in den Kommandozeilen-Tools und den Konfigurationsdateien wiederfindet. Die Komponenten können alle auf einem System installiert sein. Dies macht Testinstallationen einfach. In Produktionsumgebungen werden die einzelnen Komponenten in der Regel auf mehreren physikalischen Systemen verteilt.
Compute - „Nova"
Nova bildet den Kern einer OpenStack-Infrastruktur, wenn diese auf den Betrieb von virtuellen Maschinen ausgelegt ist. Sie ist die komplexeste Komponente und beinhaltet alle Dienste, die für die Verwaltung von Cloud-Instanzen zuständig sind. Die eigentliche Virtualisierung der Instanzen erfolgt durch die Hypervisoren auf physikalischen Sys-temen, den sogenannten Compute Nodes. Nova unter-stützt mithilfe von Treibern unterschiedliche Virtualisierungstechnologien, die aufgrund der Abstraktionsschicht gleichzeitig genutzt werden können.
Zusätzlich bietet Nova noch weitere instanzspezifische Funktionen. Es arbeitet eng mit anderen Komponenten zusammen und übernimmt deren Koordination. Die einzelnen Instanzen generieren sich aus statischen Images. Sie enthalten Betriebssysteme sowie alle weiteren Programme und werden vom Image Service (Glance) verwaltet. Für die Bereitstellung der Netzwerkressourcen, für eine Instanz greift Nova auf Neutron zu. Volumes werden der Instanz über dem Block Storage Service Cinder bereitgestellt.
Object Storage – „Swift"
Swift ist mit Nova eines der beiden initialen Projekte von OpenStack und ein verteiltes, skalierbares und objektbasiertes Speichersystem. In einem Object Storage werden die Daten nicht wie in einem File Storage hierarchisch, sondern innerhalb eines Containers auf nur einer Ebene abgelegt. Jedes Objekt (BLOB) wird mit einem eindeutigen Identifikator versehen, sodass es beim Zugriff nicht notwendig ist, den physikalischen Standort des Objektes zu kennen. Die Daten in Swift können nach dem Erstellen nur gelesen und gelöscht, jedoch nicht verändert werden.
Für die Nutzung in einer Cloud-Architektur ist ein Object Storage ideal, da der Unique Identifier für jedes Objekt dafür sorgt, dass der automatisierte Zugriff erleichtert wird. Im Falle von OpenStack kann Swift für die Speicherung von Images, Snapshots und Cloud-Instanzen genutzt werden. Darüber hinaus bietet die Architektur von Swift viele Eigenschaften, die insbesondere für die Anwendung als Cloud-Speicher wichtig sind. Swift ist jederzeit durch weitere Speichereinheiten erweiterbar und somit horizontal hoch skalierbar. Durch das Fehlen einer zentralen Organisationseinheit und der Möglichkeit, alle Komponenten häufiger redundant auszulegen, kann ein Single-Point-of-Failure vermieden werden.
Block Storage - „Cinder"
Cinder ist der Block Storage Service von OpenStack und im Vergleich zu Swift weniger komplex. Es bietet keine automatische Verteilung und Replikation der Daten. Cinder stellt den Instanzen blockbasierten Speicher als Volumes bereit. Volumes können den virtuellen Maschinen vor dem Starten und im laufenden Betrieb zugewiesen werden. Sie eignen sich vor allem für performancesensitive Anwendungen und solche, die einen direkten Zugriff auf Block-Devices benötigen. Als Storage-Backend können diverse Storage-Lösungen (z. B. LVM, NetApp, EMC und Hitachi) dienen.
Image - „Glance
Im zeitlichen Ablauf ist Glance der Beginn des Compute-Workflows. Der Image Service ist für die Registrierung, Auflistung und das Abrufen von Images für die Instanzen zuständig. Es übernimmt die Verwaltung der Images, aber nicht deren Speicherung. Glance stellt lediglich eine Abstraktionsschicht für die verschiedenen Storage-Technologien dar. Unterstützt werden die Storage-Backends Cinder, Swift, Amazon S3 und lokale Filesysteme.
Das zentrale OpenStack Repository ist der Image Service und beinhaltet die Images: Metadaten und Statusinformationen. Dabei werden die wichtigsten Image-Formate (z. B. AMI, ISO, QCOW2, VDI und VMDK) unterstützt. User und Services können private oder öffentliche Images speichern, die zum Starten von Instanzen verwendet werden.
Networking - „Neutron"
Für die Kommunikation der Instanzen untereinander sowie mit der Außenwelt ist Neutron verantwortlich. Es ermöglicht das Management von Netzwerken und bietet dabei Funktionen wie z. B. VLANs, DHCP, Firewall as a Service, Quality of Service und ACLs. Neutron ist modular aufgebaut und über einen Plugin-Mechanismus anpassbar. Dieser erleichtert nicht nur die Integration in bestehende Umgebungen, sondern auch die Erweiterung um Funktionen. Es stehen Plugins für die wichtigsten Netzwerk-Komponenten und -Software zur Verfügung.
Identity -„Keystone"
Eine der Kernkomponenten von OpenStack ist Keystone. Es bildet den zentralen Dienst für die Authentifizierung der Benutzer und das Rechtemanagement für die anderen Komponenten. Dabei implementiert Keystone keine eigenen Funktionen, um Benutzer zu speichern, sondern bildet eine Abstraktionsschicht für verschiedene Backends (z. B. SQL, PAM, LDAP oder AD). Damit kann es die bestehende Benutzerverwaltung für die OpenStack-Infrastruktur verwenden.
Bevor ein Benutzer eine Aktion mit einer der OpenStack-Komponenten ausführen kann, muss er sich gegenüber Keystone authentifizieren. Zusätzlich zu der Überprüfung von Benutzername und Passwort bzw. Zertifikaten können mithilfe von Rollen fein konfigurierbare Berechtigungen realisiert werden. Darüber hinaus kann die OpenStack-Installation auf Basis von Projekten getrennt werden. Dies ist nicht nur auf Ebene der Benutzer, sondern auch auf der Netzwerk- und Speicherebene möglich.
Die Entdeckung der Gravitation
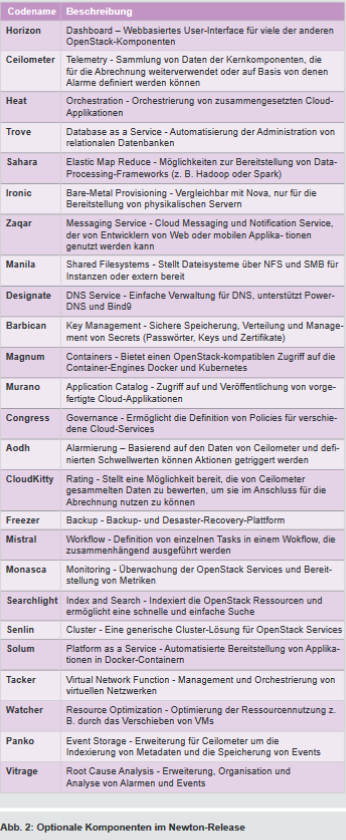
Die beschriebenen Kernkomponenten sind seit Längerem ein Teil der offiziellen OpenStack Releases. Ihnen werden eine Reihe von optionalen Services zur Seite gestellt, deren Umfang von Version zu Version anwächst. Die Entwicklung in unabhängigen Projekten ist ein Grund für die hohe Dynamik von OpenStack insgesamt. Die offiziellen Releases, die in einem halbjährlichen Rhythmus veröffentlicht werden, enthalten einen definierten Stand der Komponenten. Für jedes Release werden im Vorfeld Ziele für die Entwicklung definiert. Der Fokus lag bei Newton auf Verbesserungen der Skalierbarkeit und der Elastizität sowie einer verbesserten Integration von virtuellen und physikalischen Servern und Containern. Eine Liste der im aktuellen Release enthaltenen, optionalen Komponenten, die nach ihrer Relevanz sortiert sind, ist in Abbildung 2 aufgeführt.
Horizon, Ceilometer und Heat
Die Services Horizon, Ceilometer und Heat sind Teil der meisten OpenStack-Distributionen und aus diesem Grund auch in der Abbildung 1 dargestellt. Das Dashboard Horizon ist in der Regel der erste Berührungspunkt mit OpenStack und bietet zumindest für die detailliert vorgestellten Komponenten eine grafische Möglichkeit zur Administration. Darüber hinaus kann der Endanwender bzw. Kunde über Horizon im Rahmen seiner Berechtigungen seine zugewiesenen Ressourcen verwalten.
Der Telemetry-Service Ceilometer ist für die Ermittlung und Sammlung des gesamten Nutzungs- und Performance-Verhaltens aller OpenStack-Komponenten zuständig. Die Daten werden pro Benutzer bzw. Kunde ermittelt und ermöglichen z. B. eine spätere Bewertung und Abrechnung der genutzten Ressourcen. Das Rating und die Abrechnung sind dabei kein Bestandteil von Ceilometer. Die gesammelten Daten werden lediglich über eine API zur Verfügung gestellt. Diese können von Drittanwendungen angesprochen werden, die die Folgeverarbeitung übernehmen.
Heat ist das OpenStack-Projekt, hinter dem sich die Orchestrierungsfunktionalität verbirgt. Heat ermöglicht die Beschreibung von komplexen Cloud-Applikationen in Templates. Die Sammlung der Objekte und ihre Verknüpfung untereinander werden als Stack bezeichnet. Die Templates werden von der Heat-Engine eingelesen und ausgeführt. Die Engine triggert, wie in Abbildung 1 zu sehen ist, die weiteren Komponenten wie Nova und Cinder, die die eigentlichen Ressourcen bereitstellen.
Zusammenfassung
Die Kernkomponenten von OpenStack stehen seit mehreren Jahren zur Verfügung. Diese bilden die Grundlagen für den Aufbau und die Verwaltung einer IT-Infrastruktur mit OpenStack. Deren Funktionsumfang kann durch eine wachsende Anzahl von optionalen Komponenten erweitert werden. Durch die unabhängige Entwicklung in eigenständigen Projekten ist eine hohe Dynamik gewährleistet, die wesentlich zum Erfolg von OpenStack beiträgt. Dazu kommt die offene Architektur, die auf standardisierten Schnittstellen zwischen den Komponenten beruht und eine Erweiterung vereinfacht. Mit OpenStack steht dementsprechend eine Lösung bereit, die einen großen Schritt in Richtung Standardisierung von IT-Infrastrukturen ermöglicht und bei der Automatisierung helfen kann.
Quellen
„OpenStack Cloud Computing";
1. Auflage; Tunbridge Wells: Recursive Press; 2014
[2] Carlo Velten, Rene Büst und Max Hille:
„OpenStack im Unternehmenseinsatz";
Crisp Research AG; 2014
[3] Tilman Beitter, Thomas Kärgel, André Nähring, Andreas Steil und Sebastian Zielenski:
„IaaS mit OpenStack. Cloud Computing in der Praxis";
1. Auflage; Heidelberg: dpunk.verlag; 2014
[4] Tom Fifield, Diane Fleming, Anne Gentle, Lorin Hochstein, Jonathan Proulx, Everett Toews und Joe Topjian:
„OpenStack Operations Guide";
1. Auflage; Sebastopol: O'Reilly; 2014
Principal Consultant bei ORDIX
Kommentare