
Oracle Analytics Cloud – Datenquellen und Self-Service ETL
Datenquellen – Aufbereitet oder muss noch Hand angelegt werden?
Nachdem in den beiden letzten Beiträgen die Lizenzierung und Administration der Oracle Analytics Cloud (OAC) behandelt wurde, soll dieses Mal die Grundlage für das Reporting behandelt werden, Datenquellen und Datasets.
Die Oracle Analytics Cloud bietet viele verschiedene Konnektoren, um Datenquellen anzudocken und diese für Analysen zur Verfügung zu stellen. Diese verschiedenen Konnektoren werden im nächsten Abschnitt vorgestellt.
Was die OAC aber von der Oracle BI Suite unterscheidet, ist die Möglichkeit, einen Self-Service ETL-Prozess zu implementieren und so Daten für die Auswertungen noch einmal aufzuarbeiten. Das macht vor allem dann Sinn, wenn man mit Daten arbeitet, die nicht schon strukturell angepasst in einem Data Warehouse (DWH) liegen, sondern vielleicht nur einem selbst zur Verfügung stehen, wie z. B.: csv- oder Excel-Dateien.
Konnektoren – (Fast) alles ist möglich
Um auf die verschiedenen Datenquellen zugreifen zu können, muss für jede Datenquelle zuerst eine Verbindung hergestellt werden. Hierfür bietet Oracle Konnektoren für die unterschiedlichen Quellsysteme an, sodass der Zugriff auf jede gängige Datenquelle möglich sein sollte.
Folgende Quellen können eingebunden werden:

Wie man in der Darstellung sieht, lässt sich natürlich auf fast alle Oracle-Systeme, welche Daten bereitstellen können, zugreifen, egal ob on-Prem oder in der Cloud.
Die Konnektoren sind nicht auf das Oracle-Universum begrenzt. So lassen sich u. a. verschiedene HIVE-Systeme oder auch ältere DB-Systeme wie in Informix anbinden.
Die Anbindung der Datenquellen ist für alle Typen ähnlich. Zuerst wählt man den Menüpunkt „Verbindung erstellen“, dann den Typ der Datenquelle und muss zum Abschluss die Connection-Daten zum Quell-System eingeben.
Hier unterscheiden sich die zu hinterlegenden Werte je nach Datenquelle.

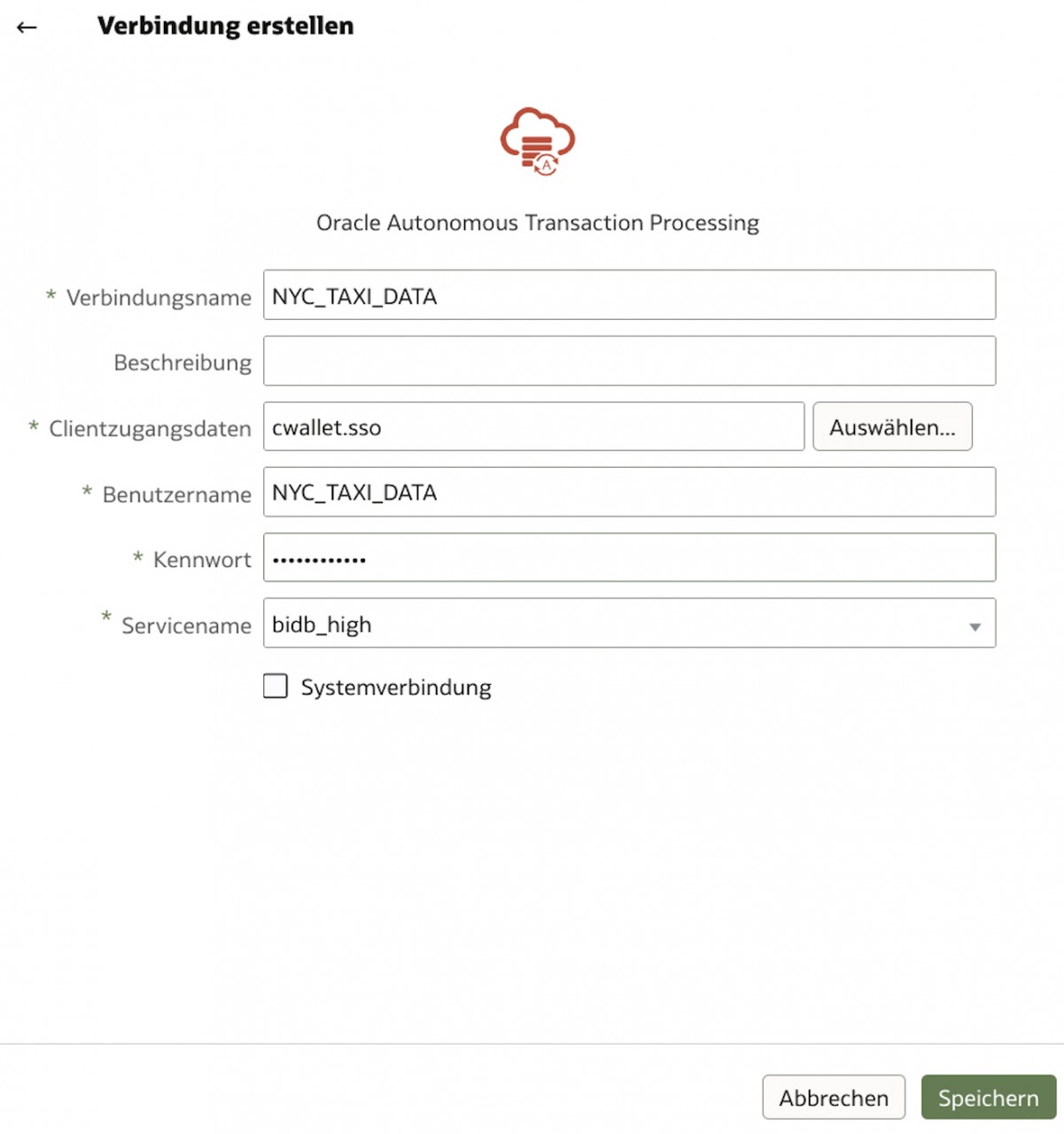
Das obere Schaubild zeigt die Einrichtung einer Verbindung zu einer Oracle Autonomous Database. Da die Verbindung SSL-verschlüsselt ist, wird hierfür ein Wallet benötigt, in dem die DB-Informationen und Zertifikate enthalten sind. Dieses Wallet kann man in der Oracle Cloud bei der zugehörigen Datenbank herunterladen.
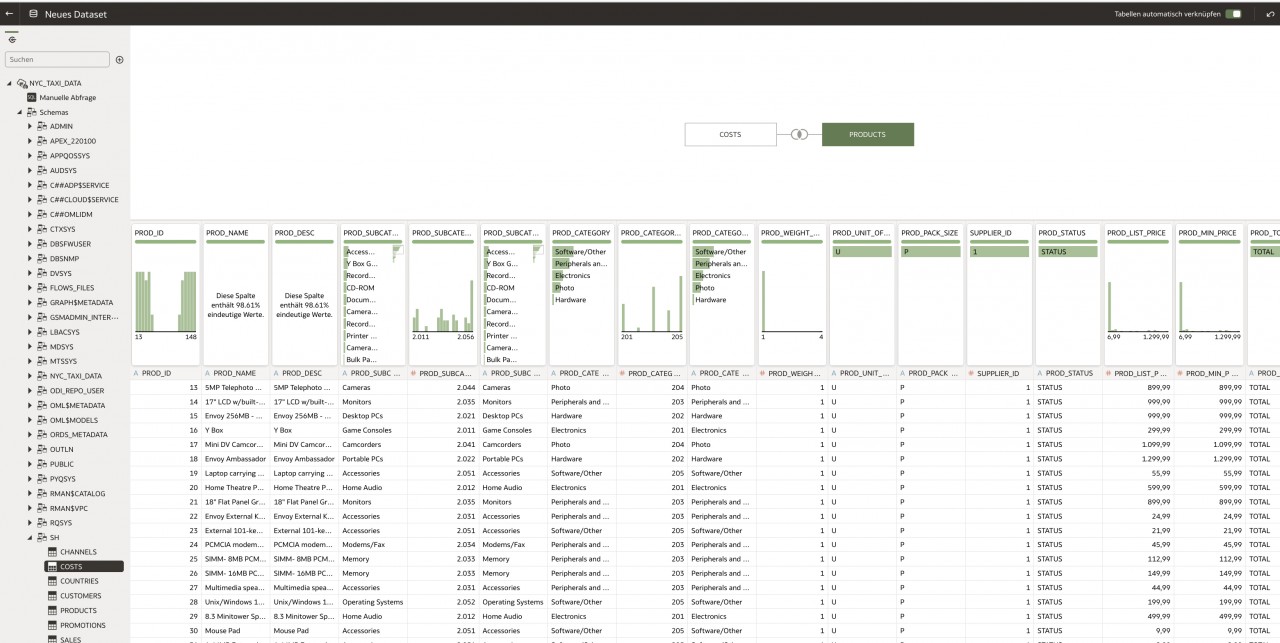
Ist die Verbindung einmal eingerichtet, kann direkt auf die Quelle und die damit verbundenen Daten zugegriffen werden. Diese lassen sich für den Aufbau von Datasets nutzen oder direkt in Auswertungen einbinden.
Ist alles Oracle Cloud, ist alles einfach
Natürlich hat Oracle wie alle anderen Cloud-Anbieter das Ansinnen, dass die Kunden mit allen Ihren Systemen in die Cloud wechseln. Denn ist man einmal den Schritt gegangen und hat seine Systeme in die Oracle Cloud migriert, ist der Weg zurück oder der Wechsel zu einem anderen Cloud-Anbieter nicht mehr so leicht.
Die Verknüpfung von Systemen in der Cloud, wie beispielsweise der OAC und OADB, ist vergleichsweise einfach. Die Anbindung von externen Quellen (z. B. On-Prem) ist trotzdem möglich, wenn auch aufwändiger.
Hier bietet Oracle zwei verschiedene Möglichkeiten: Zum einen kann eine VPN-Verbindung zwischen der Oracle Cloud und seiner On-Prem-Infrastruktur aufgebaut und die Datenbank als Quellsystem eingebunden werden. Wie das möglich ist, wird hier beschrieben.
Zum anderen ist es möglich, sogenannte Data Gateways zu nutzen. Sie übernehmen die Verbindung zwischen OAC und der „Cloud-externen“ Datenbank.
Eine Anleitung ist hier zu finden.
Zudem ist es möglich, seine Firewall so zu konfigurieren, dass die DB von überall erreichbar ist. Aus Sicherheitsaspekten wird jedoch dringend davon abgeraten.
Wo ist mein Star-Schema?
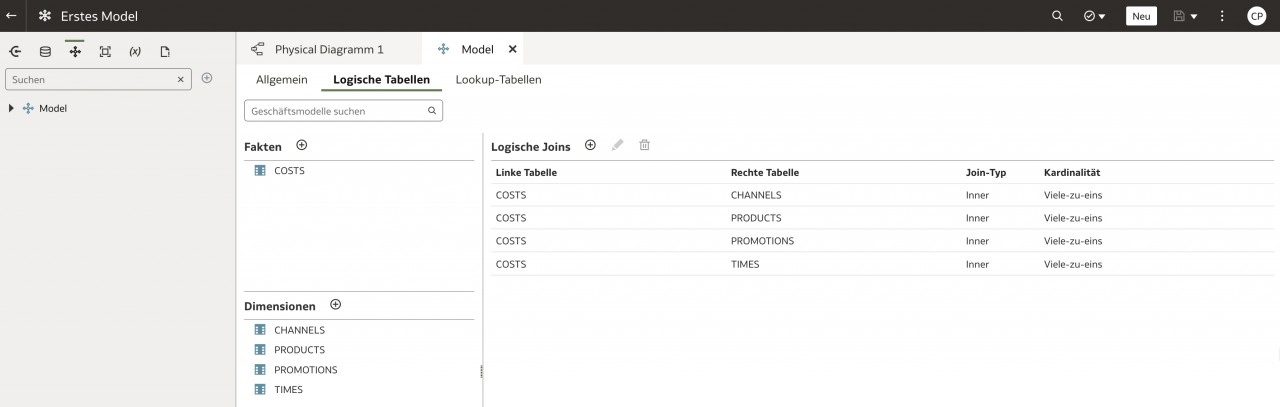
Greift man direkt auf ein Dataset oder eine Datenquelle für seine Auswertungen zurück, gibt es die Möglichkeit, in der OAC ein relationales Model über Joins der einzelnen Objekte aufzubauen und diese miteinander zu verknüpfen.
Will man aber ein aus dem DWH-Bereich bekanntes Star- oder Snowflake-Model mit den Fakten und Dimensionen aufbauen, ist weitere Vorarbeit nötig. Diese ermöglicht es auch typische BI-Funktionalitäten, wie Drill-Down, Roll-Up, etc. zu nutzen.
Um so ein Model zu erstellen, gibt es, wie immer im Leben, drei Möglichkeiten:
1. Oracle BI Administration Tool
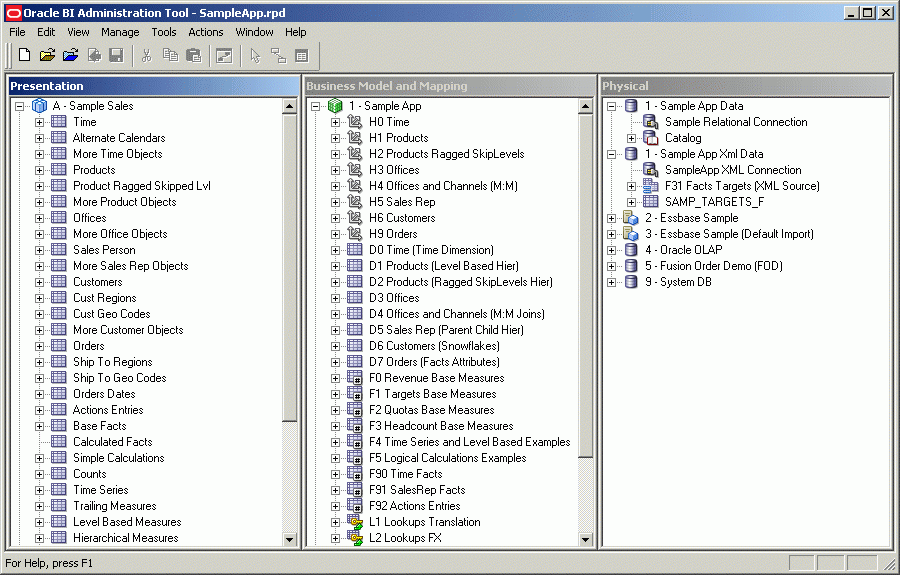
Mit dem aus der Oracle BI Suite übernommenen BI Admin Tool lässt sich ein Repository erstellen, welches aus drei Layern besteht: Physical, Logical und Presentation.
Über diese drei Layer werden die einzelnen Objekte modelliert, sodass sie im
Presentation Layer - nach sogenannten Subject-Areas gruppiert - für Auswertungen in der OAC bereitgestellt werden.
Das Vorgehen hierzu wurde in vielen Internet-Beiträgen beschrieben, so unter anderem auf der Oracle Analytics Blog-Seite.
Hinweis: Das BI Admin Tool gibt es nur als Client-Version für Windows!
2. Data Modeler
Der Data Modeler lässt sich über die OAC-Oberfläche aufrufen und bietet die Möglichkeit, online im Browser ein Fakten- und Dimensionsmodell aufzubauen.
Es lassen sich Tabellen miteinander in Beziehungen bringen, Dimensionen mit Hierarchien designen, Aggregationen für Fakten anlegen und neue Kennzahlen berechnen.
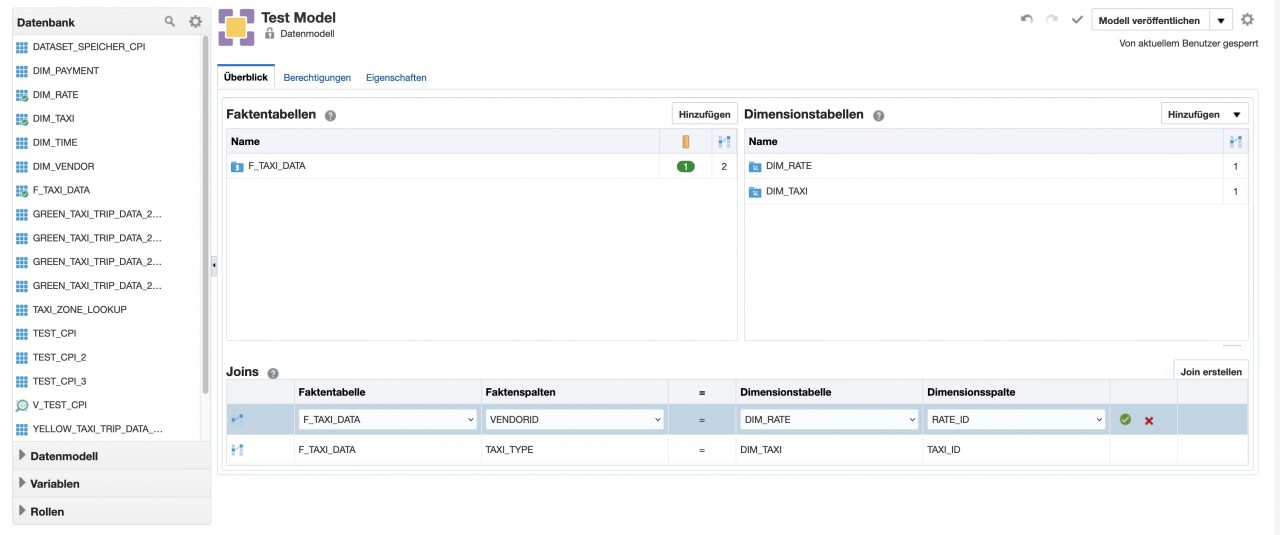
Der Data Modeler war der erste Versuch von Oracle, die Funktionen des BI Admin Tools ins Web zu bringen. Leider ist die Funktionalität sehr eingeschränkt. So lassen sich z. B. keine zwei physikalischen Quellen für ein Modell nutzen.
Hinweis: Um ein Model zu erstellen, können nicht die „normalen“ Connections genutzt werden. Stattdessen müssen die Connections unter Konsole/Verbindungen zusätzlich angelegt werden.
3. Semantic Modeler
Die dritte und neuste Möglichkeit ein Model aufzubauen ist der Semantic Modeler, welcher sich beim Schreiben dieses Beitrags noch in der Preview-Phase befindet und extra in den Systemeinstellungen aktiviert werden muss.
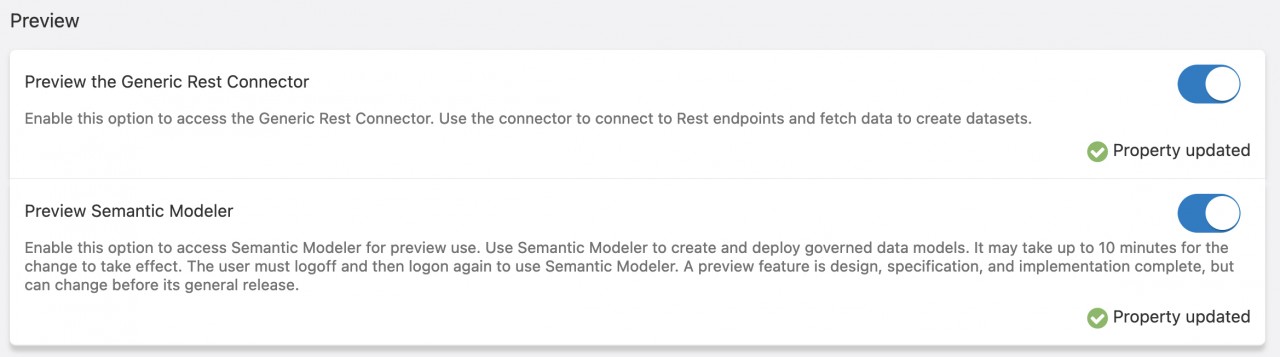
Der Semantic Modeler benutzt nicht mehr das RPD- oder UDML-Format, sondern setzt auf SMML (Semantic Modeler Markup Language). Es basiert auf JSON und bringt die Vorteile mit, dass der Code geskriptet und editiert werden kann, sowie die Möglichkeit, mit mehreren Entwicklern parallel an einem Model zu arbeiten.
Die parallele Bearbeitung von Modellen wird durch eine GIT-Anbindung realisiert. Dadurch werden alle bekannten GIT-Funktionalitäten bereitgestellt und das Arbeiten in Releases und Branches ist möglich.
Einen guten Überblick zum Semantic Modeler und SMML bietet der Artikel von Rittmanmead.
Der Semantic Modeler ist zwar noch in der Preview Phase, trotzdem empfiehlt es sich bei einem Projekt-Neustart hierauf zu setzen, da die Möglichkeiten eins und zwei veraltet oder eingeschränkt sind und in Zukunft nicht weiterentwickelt werden.
Sollte man schon ein komplexes RPD-Model designt haben, so lässt sich dieses in den Semantic Modeler importieren und weiterbearbeiten.
Wenn es mal schnell gehen soll – Self-Service ETL
Der bisherige Teil des Artikels hat beschrieben, welche Möglichkeiten es gibt, wenn es darum geht, eine zentrale Reporting-Plattform mit strukturierten Quellen, welche am besten durch einen sauberen ETL-Prozess gelaufen sind, aufzubauen.
Doch es gibt heutzutage immer öfter die Anforderung, schnell Daten einzulesen, aufzubereiten, auszuwerten und bereitzustellen.
Hierfür bietet die OAC, mit Datasets, Dataflows und Sequences, die Möglichkeit für (End-)Anwender einen ETL-Prozess zu designen und so Daten für Auswertungen bereitzustellen.
Datasets werden erstellt, indem man eine Datei oder eine Connection auswählt, die als Datenquelle dienen soll.
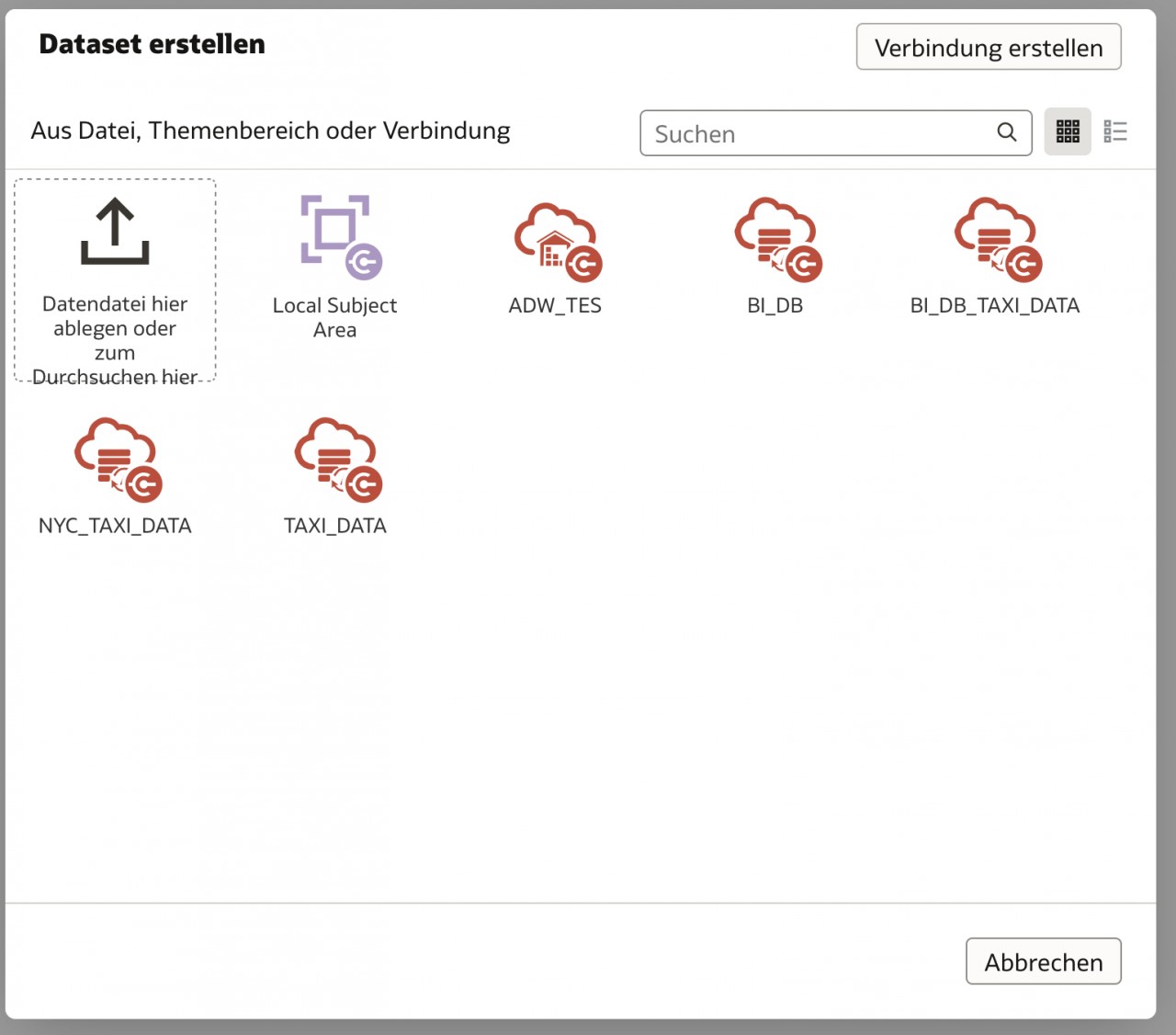
Im nächsten Schritt wird dann die Möglichkeit geboten, die Daten mit weiteren Quellen zu verknüpfen und ggf. mit zusätzlichen Informationen anzureichern.
Hierfür bietet das Tool sogenannte „Empfehlungen“ an, die es z. B. erlauben, automatisiert aus einer Stadt das Land zu bestimmen, aus einem Geburtsdatum das Alter zu berechnen, eine Adresse in Ihre Einzelteile aufzuspalten oder auch Kreditkarten-Informationen zu maskieren.
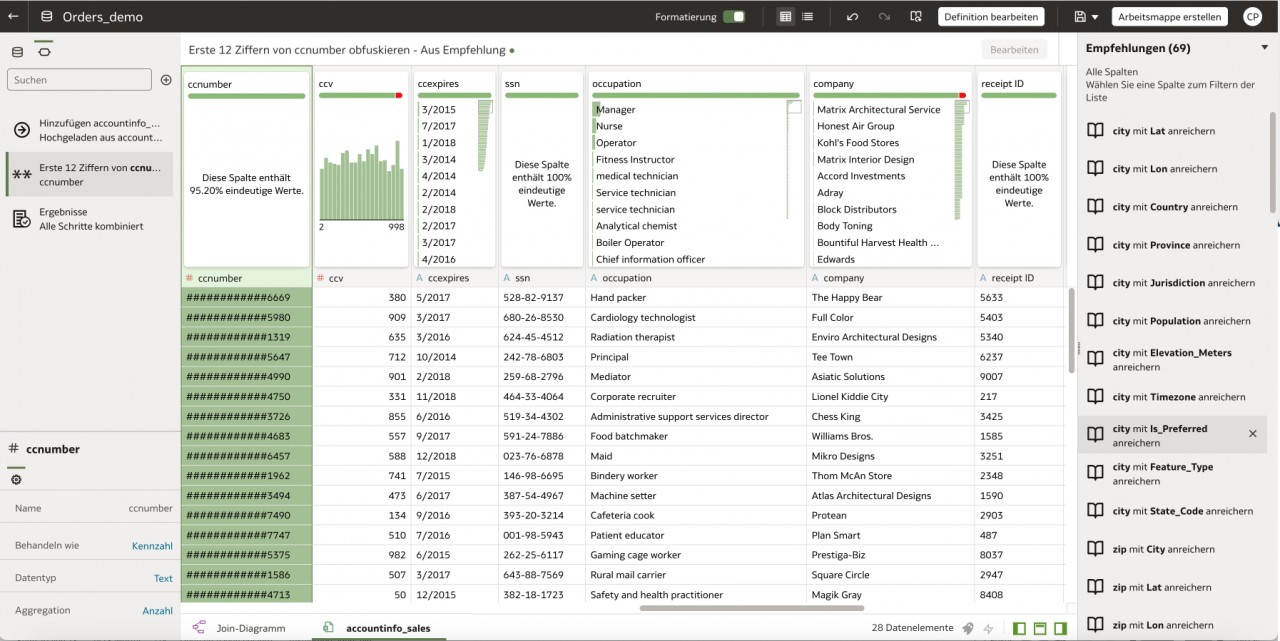
Ist das Dataset fertig erstellt und gespeichert, bietet es die Ausgangsbasis für die Dataflows.
In den Dataflows ist es möglich, Daten aus den Datasets erneut zu verarbeiten. Hier können mehrere Datasets miteinander verknüpft, Daten gefiltert und sogar komplexe Berechnungen durchgeführt werden.
Das geschieht, indem man die einzelnen Datasets, sowie die gewünschten Operatoren über das UI auf den Canvas zieht und dort die passenden Konfigurationen einstellt.
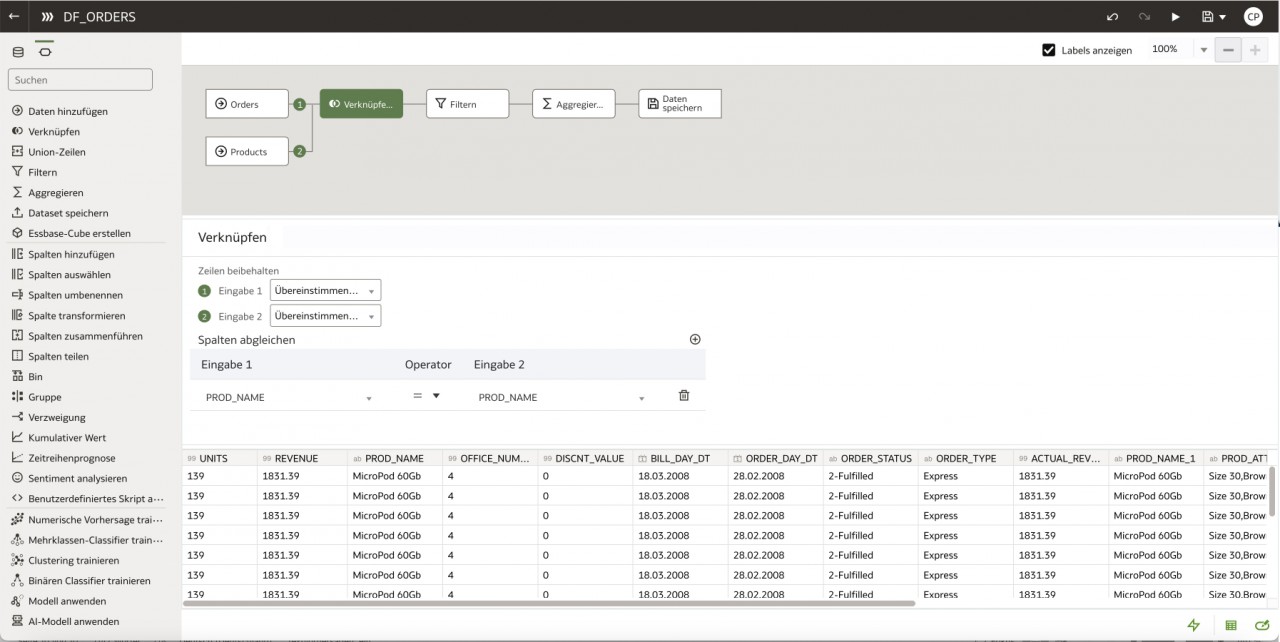
Die Ergebnisse aus einem Dataflow werden dann wiederum in einem Dataset gespeichert, welches in der Oracle Cloud oder auch in einer Datenbank liegen kann.
Soll der ETL-Prozess ein wenig größer werden und unterschiedliche Datasets befüllt werden, bieten sich Sequences an. Hiermit ist es möglich, mehrere Dataflows nacheinander laufen zu lassen.
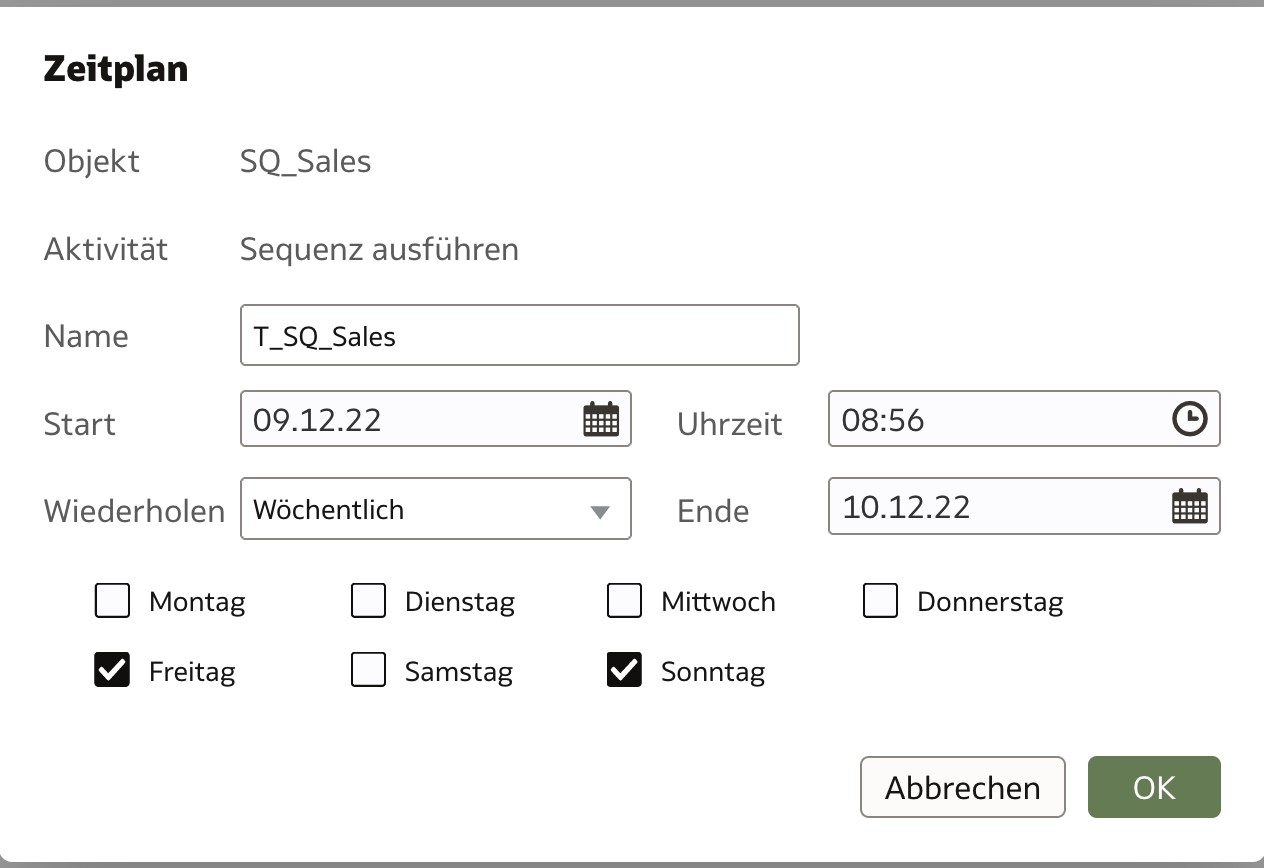
Die Sequences können alternativ über einen Zeitplan gesteuert werden. Über die Historie werden diese Lauf-Ergebnisse für den Benutzer sichtbar gemacht.
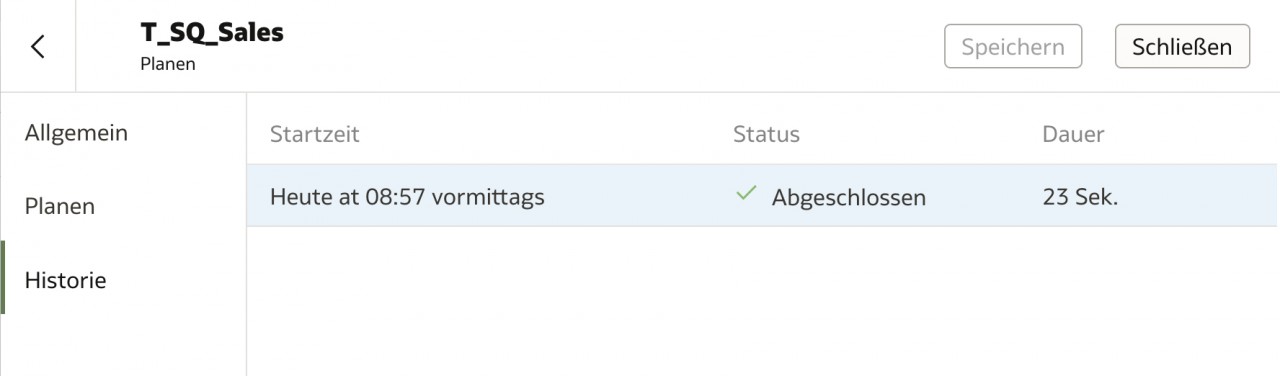
Und genau an diesen Stellen wird klar, dass es sich nur um ein Low Level ETL handelt: Denn die Ergebnisse einer Sequence beschränken sich auf erfolgreich oder nicht erfolgreich. Man erfährt nicht, wie viele Datensätze verarbeitet oder wie viele vielleicht sogar ausgesteuert wurden.
Wie der Name schon verrät, läuft eine Sequence immer nur sequenziell und verarbeitet einen Dataflow nach dem anderen. Eine parallele Verarbeitung ist nicht möglich. Schlägt ein Dataflow fehl, werden die anderen Dataflows nicht mehr ausgeführt und die Sequence bricht ab.
Hier ist man von klassischen ETL-Tools, wie Talend oder ODI (Oracle Data Integrator) mehr Funktionalität und Informationen gewohnt.
Ausblick
Nachdem in diesem Artikel gezeigt wurde, wie man verschiedene Datenquellen anbietet und Datasets erstellt, ist die Grundlage für Auswertungen geschaffen.
Diese heißen in der OAC „Workbooks“ oder in der deutschen Übersetzung „Arbeitsmappen“ und werden im nächsten Artikel behandelt.
Sollten Sie Ihren Umgang mit ETL-Tools optimieren wollen oder Interesse an einer Weiterbildung haben, besuchen Sie doch eines unserer Seminare.
Principal Consultant bei ORDIX
Kommentare