
Oracle AWR Warehouse - Alles unter einem Dach (Teil 2)
Mit dem AWR Warehouse bietet Oracle die Möglichkeit, Performance-Daten langfristig an einem zentralen Ort zu speichern. Dieser Artikel erläutert die Funktionsweise eines AWR Warehouse.
Ablauf des ETL-Prozesses
- Export
- Transport
- Import

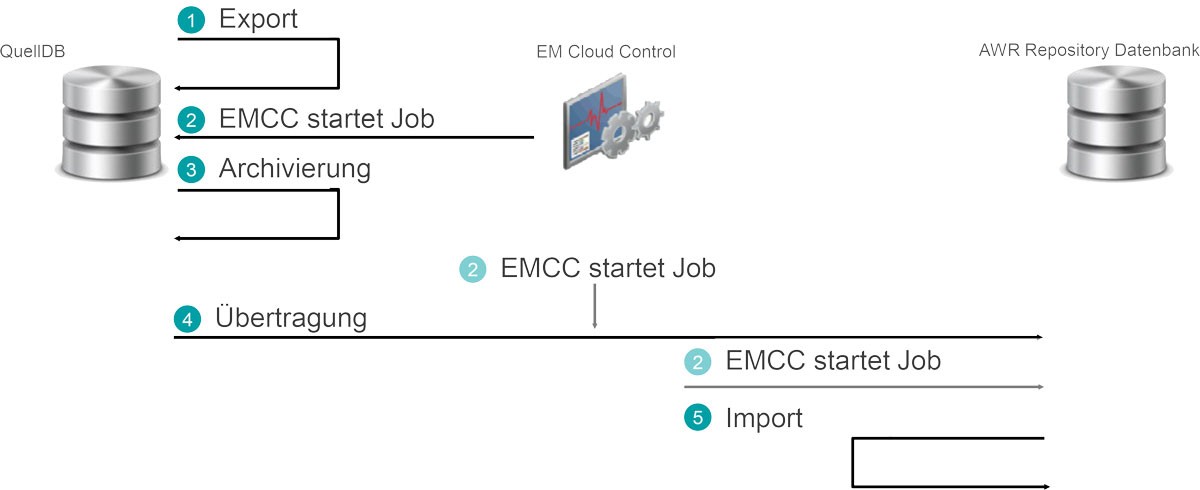
1. Phase: Export
Zunächst erstellt der Job MGMT_CAW_EXTRACT auf der Quelldatenbank einen Data Pump Export der Statistikdaten. Diese werden standardmäßig unter $AGENT_INSTANCE_HOME gespeichert. Um nicht zu große Exportdateien zu generieren, kann die maximale Anzahl an Snapshots für eine Exportdatei begrenzt werden (default 500). Bei Überschreitung des Wertes werden mehrere Exportdateien erstellt. Die Exportdateien werden im folgenden Format abgelegt: <em_id>_<sys_guid>_<dbid>_<von-Snap-ID>_<bis-Snap-ID>.dmp.
2. Phase: Start ETL-Prozess
Das EMCC startet periodisch (default alle 24h) den eigentlichen ETL-Prozess. Im EMCC kann der Fortschritt der einzelnen Tasks angezeigt und überwacht werden.
3. Phase: Archivierung
In dieser Phase komprimiert der Agent die Export-Datei auf dem Server der Quelldatenbank.
4. Phase: Übertragung
Die archivierte Datei wird vom lokalen Agenten mittels ssh- Verbindung an den Agenten des Repository-Servers übergeben und dort unter $AGENT_INSTANCE_HOME/war_t abgelegt.
5. Phase: Import
Mittels der Prozedur dbsnmp.mgmt_caw_load.run_master werden diese exportierten Daten der Quelldatenbank in die AWR-Repository-Datenbank importiert. Dies erfolgt in zwei Schritten. Im ersten Schritt importiert die
Repository-Datenbank die Data-Pump-Daten in ein temporär erzeugtes Schema. Anschließend werden die Daten ins SYS-Schema geladen. Wenn diese Phase beendet ist, sind die Daten aus der Quelldatenbank in der Repository-Datenbank zu Analysezwecken verfügbar.
Unterstützung der Multitenant-Architektur
In der aktuellen Version bietet Oracle AWR WH die Möglichkeit, AWR-Daten auf CDB-Ebene bereitzustellen. Das mit 12c R2 eingeführte Feature von AWR-Reports auf PDB-Ebene wird aktuell noch nicht unterstützt.
Sizing und Kompression
Der benötigte Speicherplatz im AWR hängt von mehreren Faktoren ab. Bei 10 aktiven Sessions fallen ca. 1–2 MB an Daten pro Snapshot an. Daher ist pro Quelldatenbank bei einem Snapshot-Intervall von 60 Minuten (default) mit ca. 24-48 MB pro Tag zu rechnen. Diese Daten werden im SYSAUX-Tablespace gespeichert.
Für eine detaillierte AWR-Analyse können die Skripte awrinfo.sql und utlsyxsz.sql verwendet werden.
Sie stellen Inhalte bereit über:- AWR-Tabellen-Details
- AWR-Retention-Informationen
- AWR-Snapshot-Informationen
- SYSAUX-Tablespace-Belegung
Fazit
Mit dem AWR WH existiert eine Möglichkeit, Anforderungen der Performance-Analyse zentral und weitestgehend unabhängig von den zu betrachtenden Datenbanken durchzuführen. Ebenso gehen bei einer Datenbankmigration oder einem Plattformwechsel keine AWR-Daten mehr verloren.
Die Analyse von Statistikdaten und deren Vergleich wird mit steigender Anzahl von Datenbanken immer bedeutender. Mit dem AWR WH bietet Oracle ein mächtiges Tool, um diesem Bedürfnis nachzukommen.Glossar
Oracle Management Server (OMS)
Im Zusammenhang mit dem Enterprise Manager Cloud Control (EMCC) beziehungsweise dem Oracle Enterprise Manager Cloud Control eine Middleware zwischen dem Oracle Agenten und der Oracle Management Console.
Enterprise Manager Cloud Control (EMCC)
Ein webbasiertes Management Tool mit einer grafischen Oberfläche.
Extract, Transform, Load (ETL)
Beschreibt einen Prozess, welcher die relevanten Daten aus Quellen extrahiert, die Daten in das Format der Zieldatenbank transformiert und diese am Ende in die Zieldatenbank speichert.
Non-CDB
Beschreibt die klassischen Oracle-Architektur im Gegensatz zur neuen Container Datenbank-Architektur (CDB), welche mit der Oracle Version 12c eingeführt wurde.
Kommentare