
Schlau wie ein Dachs: PostgreSQL Log-Analysen mit pgBadger
Im letzten Beitrag haben wir Ihnen die Extension „pg_profile“ vorgestellt, die einem bei der Lösung von Performance-Problemen sehr gute Dienste leisten kann. Heute möchten wir Ihnen „pgBadger“ (Badger; engl. der Dachs) vorstellen. Dieses Tool nutzt die umfangreichen Logging-Funktionalitäten von PostgreSQL und erstellt darüber hinaus übersichtliche Report- und / oder Lastprofile der Datenbank. Auch dieses Werkzeug ist hilfreich, um schnell einen Überblick über einen PostgreSQL-Cluster zu bekommen, Probleme schneller zu identifizieren und hoffentlich zu lösen.
Der Lebensraum
Um überhaupt mit pgBadger arbeiten zu können, braucht es ein entsprechendes Umfeld, bzw. ein paar Anpassungen / Einstellungen an der Konfiguration des PostgreSQL-Clusters.
Zunächst einmal sollte der „Logging-Collector“ des Clusters aktiv sein. Auf unserem Testsystem haben wir über die Konfigurationsdatei „postgresql.conf“ dafür gesorgt, dass die Log-Informationen als CSV Dateien in ein Verzeichnis „log“ unterhalb des Datenbankverzeichnisses „$PGDATA“ geschrieben werden.
bash> cat postgresql.conf ... #------------------------------------------------------------------------------ # REPORTING AND LOGGING #------------------------------------------------------------------------------ # - Where to Log - log_destination = 'csvlog' # This is used when logging to stderr: logging_collector = on # These are only used if logging_collector is on: log_directory = 'log' #log_filename = 'postgresql-%Y-%m-%d_%H%M%S.log' #log_file_mode = 0600 ...
Zusätzlich haben wir diverse Einstellung der Log-Parameter vorgenommen und damit spezifiziert, welche Informationen in die Logdateien geschrieben werden sollen. Insbesondere mit dem Parameter „log_min_duration_statement“ sollte vorsichtig umgegangen werden. Er bestimmt, ab welcher Laufzeit (in Millisekunden) ein Statement überhaupt in den Log-Strom aufgenommen wird. Für unser Testszenario haben wir ihn auf 0 Millisekunden gesetzt. Dies bewirkt, dass alle Queries protokolliert werden.
bash> psql example example=# alter system set log_min_duration_statement = 0; alter system set log_checkpoints = on; alter system set log_connections = on; alter system set log_disconnections = on; alter system set log_lock_waits = on; alter system set log_temp_files = 0; alter system set log_autovacuum_min_duration = 0; alter system set log_error_verbosity = default;
Eine Übersicht über die Anforderungen, die pgBadger an die Log-Einstellungen eines PostgreSQL-Clusters hat, finden Sie in der Dokumentation des Produktes:
https://pgbadger.darold.net/documentation.html#POSTGRESQL-CONFIGURATION
Die Installation des Tools an sich geht recht einfach vonstatten. Auf unserem Test-Server konnte die Software direkt über den Paketmanager installiert werden. Da es sich hierbei um ein „standalone“ Perl-Skript handelt, dürfte die Installation aber auch in anderen Umgebungen keine besondere Herausforderung sein.
bash> apt install pgbadger
Die Ernährung
Nachdem nun die Voraussetzungen geschaffen wurde, können die geschriebenen Logs von pgBadger „verdaut“ und verarbeitet werden.
Um überhaupt ein paar Daten auf unserem Test-Server verarbeiten zu können, haben wir mit „pgBench“ (vergleiche Blog-Beitrag pg_profile) wieder ein paar Testdaten und Benchmarks erstellt.
Dazu haben wir im Wesentlichen die folgenden beiden Kommandos genutzt:
# Aufbau der Testdatenbank: pgbench -i -s 100 exampl # Durchführung Benchmarks: pgbench --client=50 --jobs=25 --transactions=1000 example
Wir waren so nach ein paar Minuten in der Lage, eine gewisse Menge (109 Dateien mit 1.1 GB) von Log-Dateien zu erzeugen:
bash> ls -ltrh *.csv | head -5 -rw------- 1 postgres postgres 11M May 4 09:11 postgresql-2022-05-04_090939.csv -rw------- 1 postgres postgres 11M May 4 09:21 postgresql-2022-05-04_091102.csv -rw------- 1 postgres postgres 11M May 4 09:21 postgresql-2022-05-04_092141.csv -rw------- 1 postgres postgres 11M May 4 09:21 postgresql-2022-05-04_092147.csv -rw------- 1 postgres postgres 11M May 4 09:21 postgresql-2022-05-04_092151.csv ...
Diese gilt es nun zu parsen. pgBadger verfügt über eine Menge an Konfigurationseinstellungen und Parametern. So lassen sich Reports beispielsweise automatisch nach Intervallen (Tagen, Monate) trennen, nach Datenbanken oder Client-Hosts filtern und / oder nach Query-Arten einschränken. Eine vollständige Übersicht befindet sich natürlich auch in der oben genannten Dokumentation. Wir beschränken uns hier im Beispiel nur auf ein paar wenige Argumente ("-d" = es wird nach der DB „example“ gefiltert; "-o" = Name des Reports (HTML)):
pgbadger -d example -o badger_report.html *.csv
Die Ausgabe des Reports ist erfreulich übersichtlich, ansprechend und gliedert sich in unterschiedliche Bereiche. Nachfolgend zwei Impressionen aus dem erstellten Report:
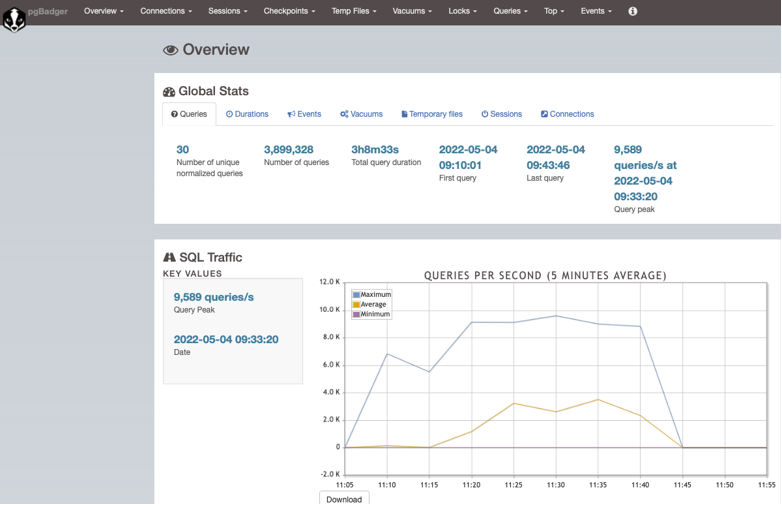
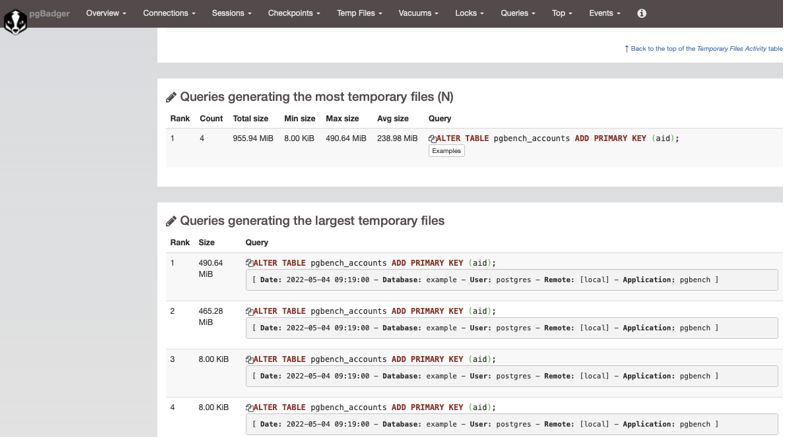
Die Verbreitung
Der Lebensraum von pgBadger sollte sich in jedem Fall vergrößern. Das Tool ermöglicht einen schnellen, optisch ansprechenden Überblick über das Last-Verhalten von Datenbanken. Es ist ein weiteres (z.B. in Ergänzung zu der Extension „pg_profile“) nützliches Werkzeug, um das Verständnis eines Clusters im Allgemeinen, aber auch in Problemsituationen, zu verbessern. Bei der Konfiguration des Clusters, hinsichtlich der Logging-Einstellungen und der anfallenden Datenmengen, ist jedoch sicherlich etwas Fingerspitzengefühl vonnöten, um nicht unnötig Last und Datenmengen zu erzeugen.
Seminarempfehlung
Sie haben Fragen rund um den Betrieb von PostgreSQL? Sprechen Sie mit uns!
POSTGRESQL ADMINISTRATION DB-PG-01
Zum SeminarPrincipal Consultant bei ORDIX
Kommentare