
Praxisphase bei ORDIX: REST-API mit Python
Während meiner letzten Praxisphase bei ORDIX habe ich im Laufe eines kleinen Projekts eine REST-API mit Python aufgebaut. Wie ich dabei vorgegangen bin und wie man in nur wenigen Minuten eine eigene API aufbaut, werde ich in diesem Blogartikel erklären.
Vorbereitung
Als Grundlage der Webanwendung dienen die Python-Module Flask-RESTX und Swagger UI. Für diese wird eine Python-Version 2.7 oder höher benötigt. RESTX bietet die Grundfunktionalitäten einer API, also das Empfangen und Verarbeiten von HTTP-Requests, während Swagger UI eine Nutzeroberfläche zum Testen der Anwendung mitbringt. Diese dient auch als Dokumentation für die API. Swagger wird bei der Installation von Flask RESTX mitgeliefert, muss also nicht extra installiert werden. Installiert werden die Module mit folgendem Befehl: pip install flask-restx
Die Situation
Als Beispiel werde ich eine API für einen digitalen Ideenbriefkasten erstellen. Die Anwendung wird von der Beispiel AG betrieben. Nutzer können hier Verbesserungsvorschläge an das Unternehmen senden. Diese werden dann von anderen Nutzern bewertet. Ideen sind dabei in verschiedene Kategorien unterteilt. Als Erweiterung des Projekts sollen die Ideen nun im Intranet der Firma zur Schau gestellt werden. Dafür soll eine REST-API erstellt werden. In der ersten Version soll nur die Ausgabe aller Ideen und bestimmter Kategorien möglich sein.
Aufbau des Projekts
Da wir ein eher kleines Projekt aufbauen, ist eine einfache Ordnerstruktur ausreichend:
ideenbriefkasten ├── api # │ ├── endpoints # API-Endpoints und deren REST-Methoden │ │ ├── ideen.py # │ │ └── kategorien.py # │ └── restx.py # Initialisierung der API └── ideenbriefkasten.py # Anwendung Ideenbriefkasen
Die Logik der API befindet sich im Unterordner api, welcher wiederum den Unterordner endpoints beinhaltet. In diesem sind Namespaces definiert. Was genau Namespaces sind, werde ich später erklären. Die Datei restx.py ist die eigentlich API-Anwendung.
Erstellen der REST API
Die Definition der API erfolgt in der Datei restx.py. Diese sieht folgendermaßen aus:
from flask import Flask, Blueprint
from flask_restx import Api
from endpoints import ns_ideen # Importieren der API-Endpoints
from endpoints import ns_kategorien #
api = Api( # Metadaten der API
title="Ideenbriefkasten API",
version="1.0",
description="API für den Ideenbriefkasten der Beispiel AG")
api.add_namespace(ns_ideen, path="/ideen") # Initialisieren der Endpoints
api.add_namespace(ns_kategorien, path="/kategorien") #
bp = Blueprint('api', __name__, url_prefix='/api') # Initialisieren der API unter der URL /api
api.init_app(bp) #
if __name__ == '__main__': # So lässt sich die API
app = Flask(__name__) # ohne Starten der Hauptanwendung testen
app.register_blueprint(bp) #
app.run(debug=True) #
Interessant ist hier zunächst die Zeile 7. Hier wird ein Api-Objekt des Fask-RESTX-Moduls erstellt. Dieses repräsentiert unsere gesamte API. Diesem werden in Zeilen 12 und 13 die Namespaces für die verschiedenen Endpoints zugewiesen. Diese sind unterteilt in Ideen und Kategorien. Jedes Namespace hat seinen eigenen URL-Präfix und ist in einer eigenen Datei definiert. So wird die API in logische Einheiten eingeteilt und somit übersichtlicher gestaltet. In unserem Beispiel gibt es zwei Namespaces: ns_ideen und ns_kategorien. Diese sind jeweils unter den Pfaden /ideen und /kategorien erreichbar.
Außerdem ist in Zeile 15 ein Blueprint definiert. Diese sind teil des Flask Frameworks. Blueprints können in einer Anwendung registriert werden und fungieren als ein Microservice innerhalb dieser Anwendung. Da unsere API Teil des Ideenbriefkasten sein soll, ist es sinnvoll, sie als Blueprint zu realisieren. So kann sie einfach in die Ideenbriefkasten integriert werden. Blueprints bekommen dabei einen eigenen Pfad. Unsere API wird unter dem Pfad /api gehostet. Will man nun beispielsweise auf das Namespace ns_ideen zugreifen, so braucht man dafür den Pfad /api/ideen.
Definition der Namespaces und Endpoints
Die Ideen – ns_ideen
Die Ausgabe der Ideen findet in dem Namespace ns_ideen statt. Namespaces sind in der Regel in einzelne Klassen unterteilt, die wiederum eigene URL-Präfixe besitzen. In unserem Beispiel ist dies die Klasse IdeenListe in Zeile 6. Da in diesem Namespace keine anderen Klassen vorhanden sind, habe ich sie einfach unter / geroutet. Dies ist jedoch eigentlich nicht die Norm. In der Klasse ist die Methode get(self) definiert. Diese wird von RESTX bei einem GET-Aufruf an den angegebenen Pfad aufgerufen. Diese ist in diesem Fall /api/ideen. Die Methode gibt einfach eine Liste mit allen Ideen wieder.
from flask_restx import Namespace, Resource
ns_ideen = Namespace("Ideen", description="Anfragen für die ideen")
@ns_ideen.route("")
class IdeenListe(Resource):
def get(self):
"""
Zeige eine Liste aller Ideen
"""
return self.get_alle_ideen()
Zu diesem Zeitpunkt ist es schon möglich, die Anwendung zu starten. Standardmäßig ist eine Flask-Anwendung unter Port 5000 zu erreichen. Bei einem Aufruf auf 127.0.0.1:5000/api begrüßt uns nun diese Seite:
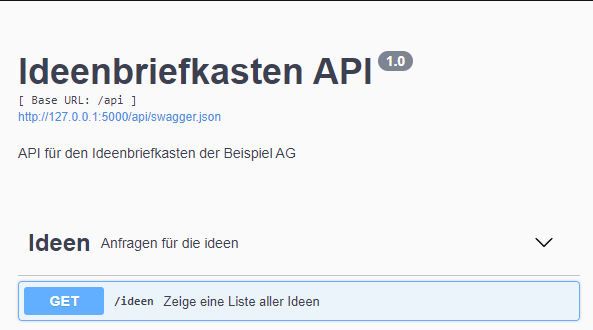
Die Nutzeroberfläche ist die Standardoberfläche von Swagger UI. Über diese kann man nun durch die Funktionen der API klicken und diese testen. Hier finden wir das oben beschriebene Namespace ns_ideen unter dem angegebenen Namen „Ideen" wieder. Unter diesem ist die GET-Methode, die wir beschrieben haben. Dabei fällt auf, dass der Kommentar aus den Zeilen 7 bis 9 zur Beschreibung der Methode wurde. Dies ist eine der Funktionalitäten von Swagger. Swagger erstellt aus der Dokumentation im Code automatisch die Dokumentation der API. Dabei wird sogar Markdown-Text erkannt. So ist es also auch möglich, Überschriften, Stichpunkte etc. zu darzustellen.
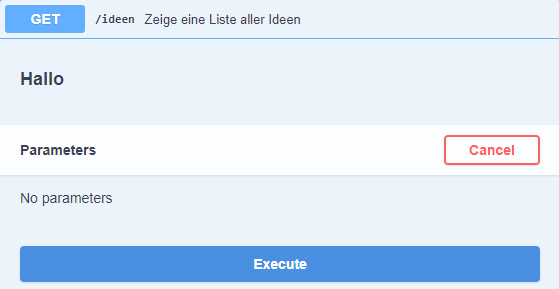
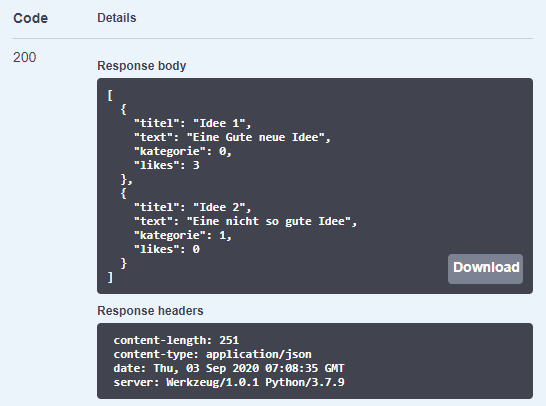
Wir haben im Response body alle aktuell vorhandenen Ideen als JSON-Objekte wiederbekommen. Zusätzlich haben wir den HTTP Response Code 200 erhalten, die Anfrage war also erfolgreich. Es fällt jedoch auf, dass die Kategorien als Index und somit nicht direkt verständlich wiedergegeben wurden. Daher muss nun noch ein Namespace für den Abruf der Kategorien erstellt werden.
Kategorien – ns_kategorien
Zu diesem Zeitpunkt wissen wir, welchen Index die gesuchte Kategorie besitzt. Daher wäre es von Vorteil, wenn wir direkt die gesuchte Kategorie und nicht alle vorhandenen abrufen können. Dafür kann man bei einem Request bestimmte Parameter mitgeben, in unserem Fall der bereits bekannte Index. Dies ist sowohl über die URL als auch über den Request Body möglich. In unserem Beispiel werde ich mich jedoch nur auf URL-Parameter beschränken.
Die Definition des Namespaces ns_kategorie sieht folgendermaßen aus:
from flask_restx import Namespace, Resource
ns_kategorien = Namespace("Kategorien", description="Anfragen für die Kategorien")
@ns_kategorien.route("/<int:kid>")
class KategorienItem(Resource):
def get(self, kid):
return self.get_kategorie(kid)
Die Parameterübergabe ist in Zeile 5 zu sehen. Anfragen auf /api/kategorien/ werden an die Klasse KategorienItem weitergeleitet. Dabei wird erwartet, dass es sich bei dem Parameter kid um einen Integer-wert handelt. Über diesen kann dann der die entsprechende Kategorie ausgelesen werden. Startet man den API-Server nun neu, sieht das User Interface so aus:
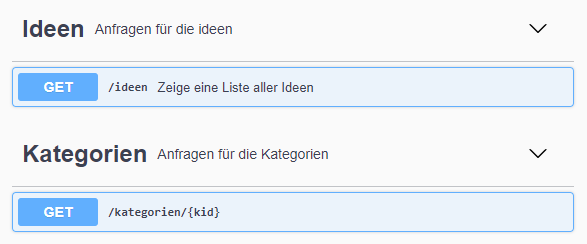
Das neue Namespace ist in dem Tab Kategorien zu finden. Darunter sieht man auch den neuen Endpoint /api/kategorien/. Dieser lässt sich mithilfe von Swagger ebenso testen wie der vorherige. Dabei lässt sich nun die gewünschte kid angeben:
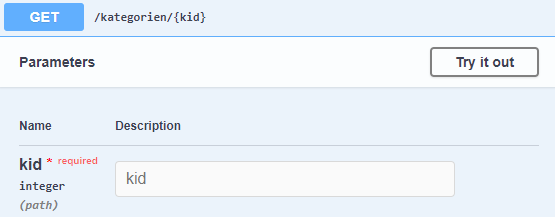
Beim Aufrufen der Ideen haben wir gesehen, dass es auf jeden Fall eine Kategorie mit dem Index 1 gibt. Sucht man nach dieser erhält man dieses Ergebnis:
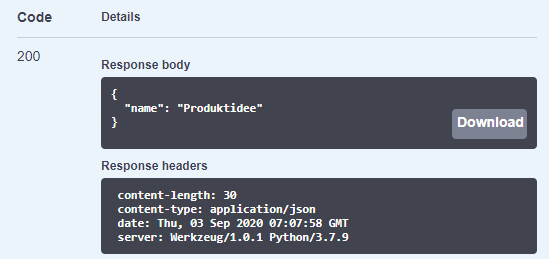
Auch hier ist der Response Code 200, die Anfrage war also erfolgreich. Bei der Idee mit der Kategorie 1 handelt es sich um eine Produktidee.
WIE GEHT ES WEITER?
In diesem Artikel wurde nur ein sehr kleiner Teil des Funktionsumfangs von RESTX gezeigt. So ließe sich das Projekt noch um weitere HTTP-Requests wie POST- oder UPDATE-Anfragen erweitern. Außerdem bietet RESTX so genannte Serializer und Parser. Mithilfe dieser lassen sich sowohl Ausgaben editieren als auch komplexere Eingaben verarbeiten. Enthält ein zu übertragendes Objekt beispielsweise sensible Daten, können diese verborgen werden.
Außerdem haben wir uns noch in keiner Weise mit Fehlerbehandlung befasst, da dieses alleine einen ganzen Blogartikel einnehmen würde.
Zudem mangelt es der Applikation noch an Sicherheit. Momentan ist die Anwendung für jeden Interessenten erreichbar. Für unseren Anwendungsfall kann dies schon problematisch sein, da nur die Server des eigenen Intranets darauf zugreifen können müssen.
Auch die Swagger Nutzeroberfläche kann nach Belieben angepasst werden. Soll beispielsweise ein Corporate Design eingehalten werden, ist dies kein Problem.
Kommentare