
Schlange liebt Elefant - Conda Environments mit PySpark und Hadoop verwenden
Für Data Science und Maschinelles Lernen sind Python und die vielen verfügbaren Bibliotheken essenzielle Werkzeuge. Für die Speicherung von großen Datenmengen hat sich Hadoop bewährt und mit PySpark gibt es eine einfache Möglichkeit, die Daten im Hadoop Cluster mit Python zu verarbeiten.
Für die Arbeit mit Python wird in der Praxis oft die Anaconda Distribution eingesetzt. Der Paketmanager Conda ist Teil der Distribution und wird genutzt, um sogenannte Environments zu verwalten. Diese Environments bzw. Umgebungen enthalten neben einem Python Interpreter auch alle notwendigen Bibliotheken in definierten Versionen. Dadurch können für unterschiedliche Anwendungen unterschiedliche Versionen des Python Interpreters und der verwendeten Bibliotheken verwendet werden.
Dieser Artikel beschreibt die Installation und Konfiguration von Anaconda und Spark, sodass Conda-Umgebungen mit PySpark genutzt werden können.
Cluster Setup
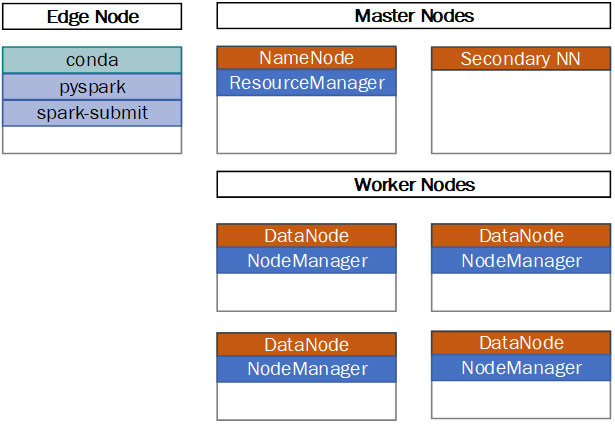
Für die folgende Beschreibung wird davon ausgegangen, dass ein vollständiger Hadoop Cluster mit mehreren Master und Worker Nodes verwendet wird. Zusätzlich wird ein dedizierter Edge Node eigesetzt (Siehe Abbildung 1). Die einzelnen Anwender melden sich (z.B. mit ssh) direkt am Edge Node an und arbeiten dort mit personalisierten Linux-Konten. Auf dem Edge Node können die Anwender mit Python arbeiten/entwickeln, Conda Environments erstellen und anpassen, die pyspark Shell starten oder mit spark-submit Jobs im Cluster ausführen.
Beim Start eines PySpark-Jobs in einem Hadoop/YARN Cluster werden auf den Worker Nodes des Clusters neben den sogenannte Executor-Prozessen auch Python-Prozesse gestartet. Alle Python-Prozesse eines PySpark-Jobs müssen dabei den gleichen Python Interpreter und die gleichen Bibliotheken verwenden. Werden Conda-Umgebungen für die Ausführung von PySpark-Jobs verwendet, dann müssen diese Umgebungen auf dem Edge Node und den Worker Nodes des Hadoop Clusters verfügbar sein.
Für die initiale Installation wird Miniconda und nicht die vollständige Anaconda-Distribution verwendet. Miniconda ist eine minimale Version von Anaconda. Alle fehlenden Dateien (insbesondere Bibliotheken) werden beim Anlegen einer Umgebung automatisch nachgeladen und installiert.
Minicona Installation
Vor der Installation von Miniconda muss das Betriebssystem vorbereitet werden. So müssen zum Beispiel einige Verzeichnisse angelegt werden. Die meisten werden nur auf dem Edge Node benötigt. Die Conda Environments müssen allerdings auch im Hadoop Cluster verfügbar sein. Am einfachsten geht das über ein geteiltes Dateisystem, wie zum Beispiel NFS. Sollte es noch kein verteiltes Dateisystem geben, dann kann auf dem Edge Node ein NFS-Server installiert und betrieben werden. Details dazu würden den Rahmen dieses Beitrags allerdings sprengen. Die notwendigen Verzeichnisse werden in der folgenden Tabelle beschrieben. In der Spalte "Freigabe" wird angegeben, ob der Pfad nur auf dem Edge Node oder zusätzlich auf den Worker Nodes verfügbar sein muss.
| Pfad | Beschreibung | Freigabe |
| /opt/miniconda | Installationsverzeichnis für die Anaconda-Distribution. | Edge |
| /etc/conda/ | Verzeichnis für die zentrale conda Konfigurationsdatei condarc. | Edge |
| /var/opt/conda-envs | Conda Environments werden in diesem Verzeichnis abgelegt. Dieses Verzeichnis muss im Hadoop Cluster sichtbar sein. | Edge + Worker |
| /var/opt/conda-pkgs | Conda Paket Cache. Beim Erstellen von Environments werden Pakete hier zwischengespeichert. | Edge |
Mit den folgenden Befehlen werden die notwendigen Verzeichnisse angelegt, sowie Miniconda heruntergeladen und installiert. Im Beispiel wird die neuste Version für Linux x86 installiert. Anaconda stellt weitere Installationspakete, z.B. für ältere Versionen oder andere Plattformen, zum Download bereit (siehe [1]).
sudo mkdir -p /opt
sudo mkdir -p /etc/conda
sudo mkdir -p /var/opt/conda-envs
sudo mkdir -p /var/opt/conda-pkgs
cd ~/Downloads
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
CONDA_HOME=/opt/miniconda
sudo bash ./Miniconda3-latest-Linux-x86_64.sh -b -p ${CONDA_HOME}
Die ausführbaren Dateien von Miniconda und der mitgelieferte Python Interpreter dürfen auf keinen Fall in den Suchpfad ($PATH) eingetragen werden. Das würde zu Konflikten mit dem Python Interpreter vom Betriebssystem führen. Conda stellt Funktonen bereit, mit denen eine Conda-Umgebung und damit auch eine bestimmte Python-Version aktiviert werden kann. Diese Funktionen werden in der Datei ${CONDA_HOME}/etc/profile.d/conda.sh definiert. Damit die Funktionen allen Benutzern zur Verfügung stehen, wird ein Link auf diese Datei in /etc/profile.d angelegt.
sudo ln -s ${CONDA_HOME}/etc/profile.d/conda.sh /etc/profile.d/conda.sh
Die erfolgreiche Installation und die Conda Version werden mit diesem Befehl in einer neuen Bash-Shell überprüft:
bash conda --version
Conda Konfiguration
Conda sucht in einer festgelegten Reihenfolge in mehreren Verzeichnissen nach Konfigurationsdateien. Die genaue Suchreihenfolge und die möglichen Namen werden in der Dokumentation beschrieben (Siehe [2]). In diesem Fall wird die systemweite Konfiguration in der Datei /etc/conda/condarc abgelegt. Die Konfiguration wird mit dem folgenden Kommando erzeugt:
sudo sh -c " cat > /etc/conda/condarc<< EOF # Verzeichnis, in dem conda Umgebungen erstellt und gespeichert werden. envs_dirs: - /var/opt/conda-envs/ # Verzeichnis für den Paket-Cache. # Beim Erstellen von Umgebungen werden Pakete hier zwischengespeichert pkgs_dirs: - /var/opt/conda-pkgs EOF "
Anschließend wird die Konfiguration überprüft.
conda info
Das Kommando gibt die verwendeten Konfigurationsdateien und -parameter aus. Im folgenden Beispiel sind die relevanten Parameter fett markiert.
active environment :
shell level :
user config file :
populated config files :
conda version :
conda-build version :
python version :
virtual packages :
base environment :
channel URLs :
package cache :
envs directories :
platform :
user-agent :
UID:GID :
netrc file :
offline mode :
None
0
/home/ordix/.condarc
/etc/conda/condarc
4.8.3
not installed
3.8.3.final.0
__glibc=2.17
/opt/miniconda (read only)
https://repo.anaconda.com/pkgs/main/linux-64
https://repo.anaconda.com/pkgs/main/noarch
https://repo.anaconda.com/pkgs/r/linux-64
https://repo.anaconda.com/pkgs/r/noarch
/var/opt/conda-pkgs
/var/opt/conda-envs
/home/ordix/.conda/envs
/opt/miniconda/envs
linux-64
conda/4.8.3 requests/2.23.0 CPython/3.8.3 Linux/3.10.0-1127.13.1.el7.x86_64 centos/7.8.2003 glibc/2.17
1001:1001
None
False
Gruppen und Rechte
Da die Installation von mehreren Benutzern verwendet werden soll, müssen die Rechte im Dateisystem angepasst werden. Ein minimales Konzept basiert auf POSIX Rechten und unterscheidet zwischen den folgenden Rollen und Gruppen:
| Rolle | Berechtigungen | Linux Gruppe |
| Systemadministrator | Installation und Konfiguration von Miniconda. Administration des Linux Betriebssystems. sudo-Berechtigung |
wheel |
| Conda Manager | Verwenden, Anlegen und Ändern von Conda-Umgebungen. | conda |
| Conda Benutzer | Verwendung vordefinierter Umgebungen. Dieses Recht bekommen alle Benutzer, die sich am System anmelden können. | "others" |
Die Rechte für die Verzeichnisse werden mit den Kommandos chown und chmod gesetzt.
# Gruppe conda anlegen
sudo groupadd conda
# Gruppe conda dem aktuellen Bbenutzer zuweisen
sudo usermod -a -G conda ${USER}
# Neu anmelden, damit die neue Gruppe wirksam wird (z.B. mit ssh)
ssh localhost
# Rechte setzen
sudo chown :conda /var/opt/conda-envs
sudo chmod 775 /var/opt/conda-envs
sudo chmod g+s /var/opt/conda-envs
sudo chown :conda /var/opt/conda-pkgs
sudo chmod 775 /var/opt/conda-pkgs
sudo chmod g+s /var/opt/conda-pkgs
Das Kommando chmod g+s sorgt dafür, dass neue Unterverzeichnisse und Dateien die Gruppe erben. Dadurch wird sichergestellt, dass alle Mitglieder der Gruppe conda Schreibrechte für neue Umgebungen bekommen und somit auch Änderungen an den Conda-Umgebungen vornehmen können.
Achtung! Wenn dem aktuellen Benutzer eine neue Gruppe zugewiesen wird, dann ist diese Änderung erst nach einer erneuten Anmeldung am System wirksam.
PySpark-Default-Umgebung anlegen
Im nächsten Schritt wird mit conda eine neue Umgebung angelegt, aktiviert, überprüft und wieder deaktiviert. Die Option --copy sorgt dafür, dass Dateien in das Verzeichnis für die Umgebung kopiert werden und keine Links genutzt werden. Das ist wichtig, da die Conda-Installation selbst nicht auf den Worker Nodes verfügbar ist. Weiterhin können Umgebungen, in die alle Dateien kopiert werden, einfach eingepackt und auf anderen Systemen verwendet werden.
# Neue Conda Umgebung erstellen conda create --name pyspark-default --copy python=3.7.9 -y # Neue Conda Umgebung aktivieren (benutzen) conda activate pyspark-default # Umgebungen auflisten conda env list # Bibliotheken innerhalb der aktiven Umgebung auflisten conda list # Umgebung deaktivieren conda deactivate
Conda hat viele weitere Befehle, um existierende Umgebungen zu verändern oder zu löschen. Diese werden ausführlich in der Dokumentation beschrieben (siehe [3]). Um die neue Umgebung wieder zu löschen, kann der folgende Befehl verwendet werden:
# ACHTUNG! Diesen Befehl nicht ausführen. Die Umgebung wird noch benötigt. conda remove --name pyspark-default --all
Die Python Spark Bibliotheken (pyspark) werden explizit nicht installiert. Diese Bibliotheken sind bereits Teil der Spark-Installation im Hadoop Cluster. Werden innerhalb der Conda-Umgebung andere Versionen verwendet, dann kann das zu Konflikten und Inkompatibilitäten führen. Weiterhin muss beim Anlegen einer Umgebung darauf geachtet werden, dass die Python-Version mit der Spark-Version im Hadoop Cluster kompatibel ist.
PySpark mit Conda testen
Jetzt ist es an der Zeit, die neue Umgebung im Cluster zu testen. Dazu wird ein kleines Python-Skript mit einem Spark-Job erstellt. In dem Spark-Job wird das klassische Word-Count-Beispiel implementiert (Siehe auch [4]).
Mit den folgenden Befehlen wird das Python-Skript erzeugt.
# Verzeichnis für PySpark Tests anlegen
TEST_DIR=/var/opt/pyspark-test
sudo mkdir ${TEST_DIR}
sudo chown ${USER}:${USER} ${TEST_DIR}
sudo chmod 755 ${TEST_DIR}
sudo chmod g+s ${TEST_DIR}
cd ${TEST_DIR}
# PySpark-Script erstellen
cat > word_count.py<< EOF
from pyspark.sql import SparkSession
import platform
# Count Words
# Input: RDD with lines of text
# Output: Words, sorted by name and
# number of occurences in the input text
# Python version is appended to each word, to verify
# the version used on each executor
if 'spark' not in globals() :
spark = SparkSession.builder.appName("Word Count with NumPy").getOrCreate()
print("SparkSession created as 'spark'")
sc = spark.sparkContext
lines = sc.parallelize(["Hello World", "Hello Spark"])
words = lines.flatMap(lambda line: line.split(" "))
tuples = words.map(lambda word: (word + '-python-version:' + platform.python_version(), 1))
counts = tuples.reduceByKey(lambda wc1, wc2: wc1 + wc2)
sorted = counts.sortByKey()
sorted.collect()
output = sorted.collect()
print('Driver Python Version: ' + platform.python_version())
print('Output:')
print(output)
EOF
Im ersten Test wird das Skript mit der PySpark Shell ausgeführt.
Für die Ausführung muss die Conda-Umgebung nicht aktiviert werden! Über die Option --conf wird der Pfad zum Python Interpreter direkt angegeben. Wichtig ist, dass der Pfad nicht nur auf dem Edge Node sondern auch auf allen Worker Nodes im Hadoop-/YARN-Cluster existiert und die Knoten auf die Umgebung zugreifen können. Die beiden Optionen --num-executor und --executor-cores sorgen dafür, dass direkt beim Start zwei YARN-Container mit jeweils einem CPU-Core für die Spark-Executor-Prozesse gestartet werden. Diese beiden Parameter sind nicht zwingend notwendig, helfen aber beim Test und sorgen dafür, dass nicht zu viele Ressourcen allokiert werden.
pyspark \ --master yarn \ --num-executors 2 \ --executor-cores 1 \ --conf spark.pyspark.python=/var/opt/conda-envs/pyspark-default/bin/python
In der Ausgabe sollte sich Spark jetzt mit der Python-Version aus der Conda-Umgebung melden. Das sieht dann in etwa so aus:
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 2.4.0-cdh6.3.2
/_/
Using Python version 3.7.9 (default, Aug 31 2020 12:42:55)
SparkSession available as 'spark'.
Das Spark-Skript wird innerhalb der Shell mit dem folgenden Befehl ausgeführt:
exec(open('word_count.py').read())
Das Ergebnis wird dann in stdout (der Konsole) ausgegeben:
Driver Python Version: 3.7.9
Output:
[('Hello-python-version:3.7.9', 2), ('Spark-python-version:3.7.9', 1), ('World-python-version:3.7.9', 1)]
Weitere Details zum Ausführen von Spark-Jobs mit YARN und zur Konfiguration finden Sie auf der Apache-Spark-Homepage ([5] und [6]). Was bei der Ausführung im Betriebssystem der einzelnen Hadoop Knoten geschieht, wird im ORDIX-Blog Artikel "(PySpark) on YARN - Behind the Scenes" ([7]) erklärt. Der Artikel beschreibt auch, wie im Betriebssystem (mit yarn und ps) überprüft werden kann, welcher Python Interpreter für die einzelnen YARN-Container gestartet wurde.
Spark-Submit mit Conda testen
Der nächste Test erfolgt mit spark-submit. Dies ist die übliche Methode, einen (Py)Spark-Job in einem YARN Cluster zu starten.
spark-submit \ --master yarn \ --num-executors 2 \ --executor-cores 1 \ --conf spark.pyspark.python=/var/opt/conda-envs/pyspark-default/bin/python \ word_count.py
Das Ergebnis des Jobs wird in diesem Fall zwischen anderen Log-Meldungen in der Konsole ausgegeben.
Staging und Deployment der Conda-Umgebung
Bei vielen Hadoop-Installationen gibt es eine strikte Trennung zwischen Entwicklungs- und Produktions-Clustern. Um ein Python-Programm mit einer Conda-Umgebung in einem anderen Cluster (z.B. in Produktion) auszuführen, muss neben dem Python Code für den Spark-Job auch die Umgebung paketiert und auf dem Zielsystem bereitgestellt werden.
Der Spark-Job ist in diesem einfachen Fall eine einzelne Python-Datei, die auf das Zielsystem kopiert wird. Die Conda-Umgebung wird mit dem Zip-Tool eingepackt und auf den Edge-Knoten das Zielsystems übertragen. Für einen ersten Test kann das Paket auch einfach in ein anderes Verzeichnis auf dem lokalen System (localhost) kopiert werden.
cd /var/opt/conda-envs
zip -r pyspark-default.zip pyspark-default
scp pyspark-default.zip localhost:${TEST_DIR}/pyspark-default.zip
Auf dem Zielsystem gibt es mehrere Möglichkeiten, die Conda-Umgebung zu nutzen. Im Folgenden werden zwei davon beschrieben.
Installation auf den Cluster-Knoten
Für diese Option wird das Paket entpackt und auf den einzelnen Edge und Worker Nodes im Cluster installiert. Hier könnte auch ein Shared Storage, wie zum Beispiel NFS, eingesetzt werden. Diese zusätzliche Abhängigkeit würde aber die Verfügbarkeit des Systems im Zweifelsfall verringern.
Bei der Installation ist es wichtig, dass auf allen Worker-Knoten das gleiche Zielverzeichnis verwendet wird. Weiterhin benötigt der Benutzer yarn Lese- und Ausführungsrechte für das Verzeichnis und die Dateien der Conda-Umgebung. Auf dem Edge-Knoten kann für den Driver ein anderes Verzeichnis genutzt und beim Start des Jobs entsprechend konfiguriert werden (spark.pyspark.driver.python). Um die Komplexität gering zu halten, sollte das Verzeichnis nach Möglichkeit identisch mit dem Verzeichnis auf den Workern sein.
Nach dem Auspacken des Pakets auf den einzelnen Knoten, wird der Spark-Job mit spark-submit gestartet.
# Auf allen Worker- und Edge-Knoten auspacken
cd ${TEST_DIR}
unzip pyspark-default.zip
# Auf dem Edge-Knoten den Job starten
spark-submit \
--master yarn \
--num-executors 2 \
--executor-cores 1 \
--conf spark.pyspark.python=$(pwd)/pyspark-default/bin/python \
word_count.py
Achtung! Für den Parameter spark.pyspark.python muss der vollständige Pfad angegeben werden. Die YARN-Container suchen auf den Cluster-Knoten in genau dem Pfad nach dem Python Interpreter.
Dieses Verfahren hat vor allem den Vorteil, dass die Dateien der Python-Umgebung einmal im Custer verteilt werden und anschließend von den Jobs direkt genutzt werden können. Das Starten von Jobs geht dadurch relativ schnell. Für Jobs, die regelmäßig ausgeführt werden, ist das ein klarer Vorteil. Weiterhin können mehrere Jobs dieselbe Umgebung nutzen. Bei Updates an der Conda-Umgebung muss sichergestellt werden, dass alle Worker- und Edge-Knoten aktualisiert werden.
Deployment über spark-submit
Alternativ kann die Python-Umgebung auch mit der Option --archive an spark-submit übergeben werden. In diesem Fall wird das Archiv über das HDFS im Cluster verteilt.
Wenn der Spark Driver, wie in den bisherigen Beispielen, auf dem Edge-Knoten ausgeführt wird, dann muss das Zip-Archiv zusätzlich auf diesem Knoten ausgepackt werden.
Beim Aufruf von spark-submit muss der Python-Pfad für den Driver auf das lokale Verzeichnis zeigen. Der Pfad für die Spark-Executor-Prozesse im Cluster verweist dagegen auf das Python im ZIP-Archiv. Die Notation pyspark-default.zip#PY erzeugt einen Alias (PY) für das Archiv (pyspark-default.zip). Dieser Alias wird dann für weitere Parameter verwendet.
# Auf dem Edge-Knoten den Job starten spark-submit \ --master yarn \ --num-executors 2 \ --executor-cores 1 \ --conf spark.pyspark.driver.python=pyspark-default/bin/python \ --archives pyspark-default.zip#PY \ --conf spark.pyspark.python=./PY/pyspark-default/bin/python \ word_count.py
Die Pfade für die Parameter --conf spark.pyspark.driver.python und --archives können auch relativ angegeben werden. Diese beiden Parameter werden von spark-submit auf dem lokalen System ausgewertet. Die Executor-Prozesse im Cluster greifen über den Alias PY auf die Dateien im Archiv zu.
Soll der Driver auch im Cluster ausgeführt werden, dann muss das Archiv nicht auf dem Edge-Knoten ausgepackt werden. In dem Fall wird der Driver als Teil das YARN Application Masters gestartet und es wird die Python-Umgebung aus dem ZIP-Archiv verwendet.
spark-submit \ --master yarn \ --deploy-mode cluster \ --num-executors 2 \ --executor-cores 1 \ --archives pyspark-default.zip#PY \ --conf spark.pyspark.python=./PY/pyspark-default/bin/python \ word_count.py
Da der Job sein Ergebnis nur in der Konsole ausgibt, ist das für diesen Test-Job nur bedingt sinnvoll. In der Realität werden Ergebnisse üblicherweise im HDFS oder in einer Datenbank wie HBase oder Kudu gespeichert. Dann ergibt die Ausführung des Drivers im Cluster deutlich mehr Sinn. Ein Vorteil ist zum Beispiel, dass die Ressourcen (Speicher und CPU) des YARN Clusters für den Driver genutzt werden und nicht die Ressourcen des Edge Nodes.
Durch die automatische Verteilung des ZIP-Archivs muss dieses nicht auf allen Cluster-Knoten ausgepackt werden. Insbesondere wenn sich die Conda-Umgebung häufig ändert, kann das ein großer Vorteil sein. Bei großen Umgebungen (ZIP-Dateien) kann es aber den Start des Jobs deutlich verzögern, da das Archiv ins HDFS geladen und anschließend an die Worker-Knoten verteilt werden muss.
Weitere Umgebung anlegen und nutzen
Als letzter Test wird eine weitere Conda-Umgebung mit einer anderen Python-Version und mit der Bibliothek NumPy erstellt. Der Word-Count-Job wird so angepasst, dass er die NumPy-Funktion sum() für die Berechnung der Summe verwendet.
Mit den folgenden Kommandos wird die Conda-Umgebung erstellt und das Python-Skript erzeugt.
conda create --name pyspark-np --no-default-packages --copy python=3.6.12 numpy=1.19.1 -y
cd $TEST_DIR
cat > word_count_np.py<< EOF
from pyspark.sql import SparkSession
import platform
import numpy as np
# Count Words
# Input: RDD with lines of text
# Output: Words, sorted by name and
# number of occurences in the input text
# Python version is appended to each word, to verify
# the version used on each executor
if 'spark' not in globals() :
spark = SparkSession.builder.appName("Word Count with NumPy").getOrCreate()
print("SparkSession created as 'spark'")
sc = spark.sparkContext
lines = sc.parallelize(["Hello World", "Hello NumPy"])
words = lines.flatMap(lambda line: line.split(" "))
tuples = words.map(lambda word: (word + '-python-version:' + platform.python_version(), 1))
counts = tuples.reduceByKey(lambda wc1, wc2: np.sum([wc1, wc2]))
sorted = counts.sortByKey()
sorted.collect()
output = sorted.collect()
print('Driver Python Version: ' + platform.python_version())
print('Output:')
print(output)
EOF
Für die Ausführung des Skripts wird spark-submit verwendet.
spark-submit \ --master yarn \ --num-executors 2 \ --executor-cores 1 \ --conf spark.pyspark.python=/var/opt/conda-envs/pyspark-np/bin/python \ word_count_np.py
Das Ergebnis sieht dann wie folgt aus:
Driver Python Version: 3.6.12
Output:
[('Hello-python-version:3.6.12', 2), ('NumPy-python-version:3.6.12', 1), ('World-python-version:3.6.12', 1)]
Fazit
In diesem Artikel wurde anhand konkreter Beispiele die Nutzung von Conda-Umgebungen zur Ausführung von PySpark-Jobs in einem Hadoop Cluster gezeigt.
Durch den Einsatz mehrerer Umgebungen können von unterschiedlichen Jobs unterschiedliche Python-Versionen mit unterschiedlichen Bibliotheken verwendet werden. Änderungen an einer Umgebung haben dadurch nur auf die Jobs Auswirkungen, die mit dieser Umgebung ausgeführt werden. Während der Entwicklung sind Änderungen an einer Umgebung sehr leicht möglich. Ein umständliches und zeitaufwändiges Paketieren und Verteilen wird durch den Einsatz eines geteilten Dateisystems vermieden.
Die fertigen Umgebungen können unabhängig von Conda eingesetzt werden. Dazu werden die Dateien einer Conda-Umgebung mit dem Zip-Tool eingepackt, auf das Zielsystem kopiert und dort installiert.
Interesse geweckt?
Wenn Sie noch Fragen rund um Hadoop, Spark oder Anaconda haben, dann sprechen Sie uns an oder besuchen Sie einen unserer Kurse aus unserem Seminarshop:
Zu unseren Big Data Seminaren
Kommentare