Software 2.0: Wie sieht ein Entwicklungzyklus von AI-Systemen aus?
In der herkömmlichen Softwareentwicklung haben Versionsverwaltungssysteme wie Git und darauf aufsetzende Deployment-Tools längst Einzug gehalten und sind aus dem Entwicklungsalltag nicht mehr wegzudenken. In der vergleichsweisen jungen Disziplin des modernen Machine Learning wurden diese erprobten Konzepte im Laufe der Zeit auf die zusätzlichen Anforderungen überführt und in dedizierten Frameworks gebündelt. Dieses Paradigma der datengetrieben Softwareentwicklung wird auch häufig „Software 2.0" genannt, da keine expliziten Anweisungen formuliert werden müssen. Stattdessen lernt die Maschine implizit die Regeln zur Zielerfüllung mithilfe eines Algorithmus, welcher mit Daten gefüttert wird. In diesem Artikel soll der Entwicklungszyklus von solchen AI-Systemen, insbesondere die Modell-Experimentation und das automatisierte Deployment, näher beleuchtet werden, um ein Verständnis für die Unabdingbarkeit von weiteren Hilfsmitteln zur Bewältigung der zusätzlichen Komplexität zu schaffen.
ML Lifecycle
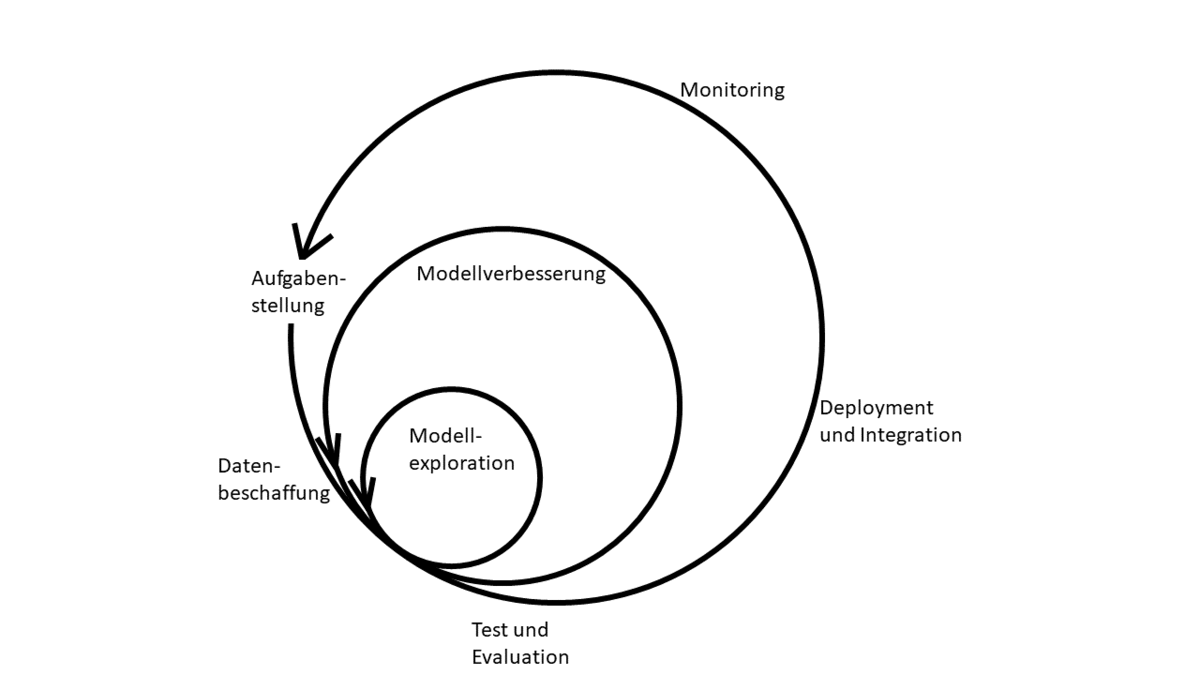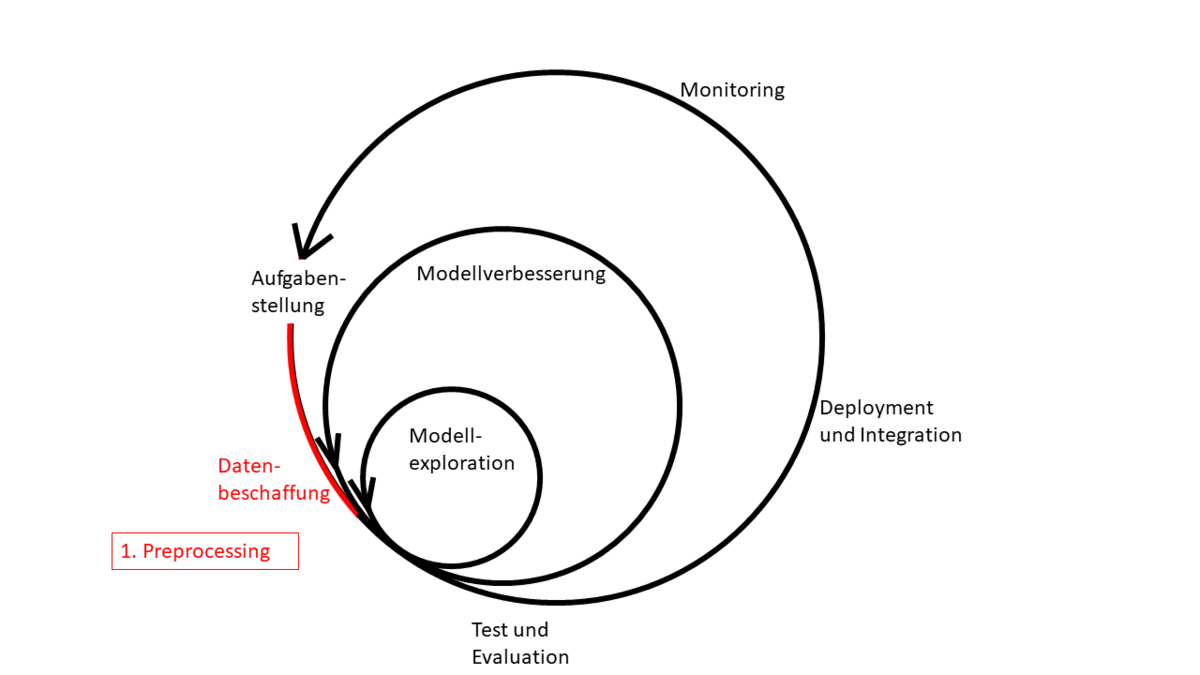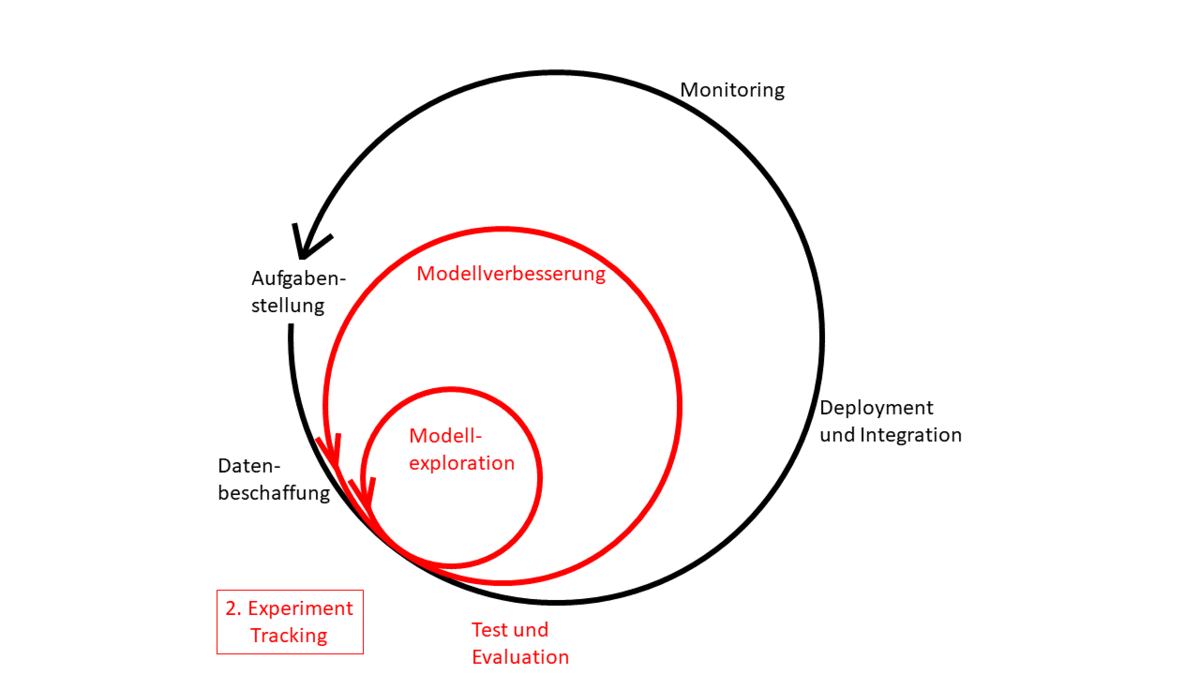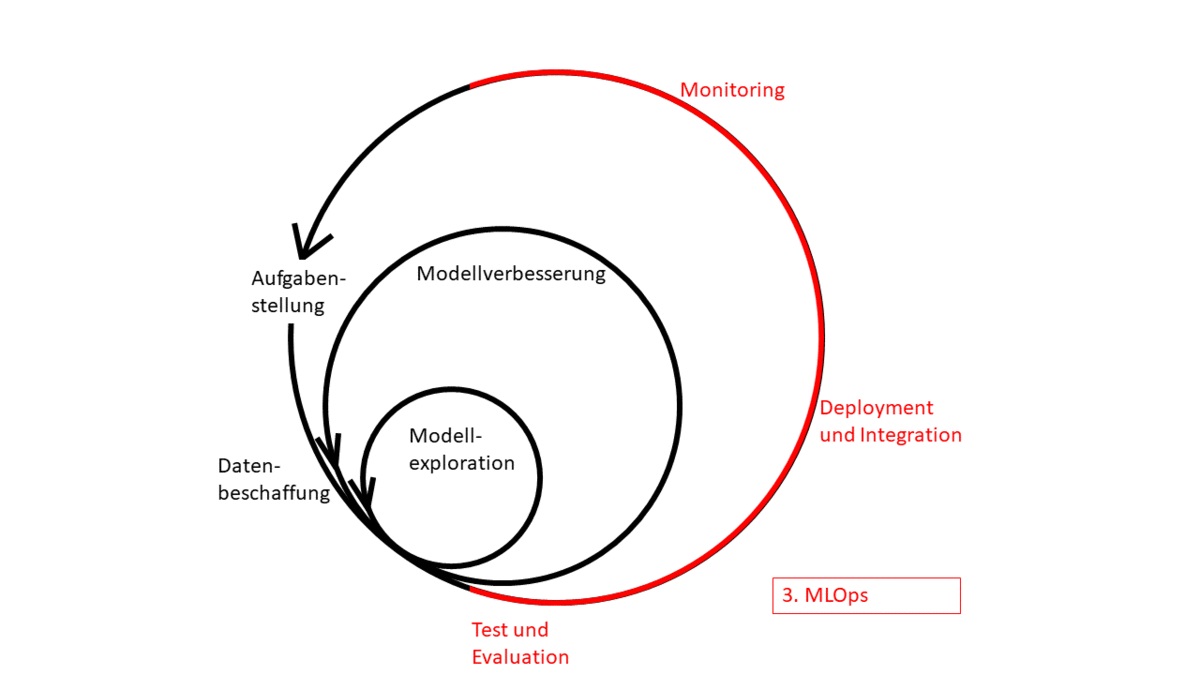
Abbildung 1: Machine Learning Zyklus
Machine-Learning-Projekte folgen in der Regel immer einem ähnlichen Zyklus. Nach der Definition der Aufgabenstellung werden zunächst Daten gesammelt und aufbereitet. Diese dienen als Grundlage, auf derer nun verschiedene Modelltypen getestet werden können. Wurde eine geeignete Architektur gefunden, gilt es diese bis zu einem zufriedenstellenden Grad zu verbessern. Besteht das resultierende Modell die definierten Tests, kann ein Deployment vorgenommen werden. Mit der Integration in die Produktivumgebung ergeben sich häufig unvorhergesehene Szenarien, weshalb das Modell und dessen Ausgaben kontinuierlich überwacht werden sollten. Daraus resultieren weitere Erkenntnisse, die zu einer Reevaluation der Aufgabenstellung führen können und so den Zyklus erneut anstoßen. Dabei kann jeder Subzyklus beliebig oft durchlaufen werden. Innerhalb dieses Zyklus gilt es, nicht nur den geschriebenen Code, sondern auch die einfließenden Daten und daraus entstehende Artefakte, wie beispielsweise trainierte Machine Learning Modelle, zu verwalten. Dies erfordert zusätzliche Methoden, um eine strukturierte und in ihren Einzelteilen reproduzierbare Entwicklung zu ermöglichen, welche im Folgenden vorgestellt werden.
Experiment Tracking
Wie bereits angemerkt wird die Entwicklung von AI-Systemen maßgeblich durch die in Abbildung 2 gekennzeichneten Achsen beeinflusst. Dabei können vermeintlich kleine Änderungen im Code, wie die Justierung von Hyperparametern, große Auswirkungen auf die Modelle haben. Die Intention hinter der Justierung ergibt sich jedoch nicht unmittelbar aus den Änderungen im Code und benötigt eine explizite Formulierung. Aus den Hyperparametern oder Modellfeatures resultierende Bugs sind zudem schwer zu entdecken und zurückzuverfolgen, da erzeugte Modelle keine Fehler werfen, sondern beispielsweise lediglich eine geringere Genauigkeit aufweisen. Da die Erzeugung von Modellen zudem sehr ressourcenaufwändig sein kann, ist eine vollständige Aufzeichnung der einzelnen Durchläufe unabdingbar, um die Gesamtanzahl an nötigen Iterationen möglichst gering zu halten.
Experiment Tracking kann dabei helfen, diese Probleme abzuschwächen und den Iterationsverlauf transparenter zu machen.
„MLOps" – DevOps für Machine Learning
Um den ML-Zyklus vollständig abzudecken, bedarf es neben dem Experiment Tracking zusätzlicher Tools, um die Abläufe herkömmlicher CI/CD für Machine Learning umzusetzen. Durch die experimentelle Natur entsteht eine größere Anzahl an Iterationen, welche verwaltet werden muss. Zudem sind, aufgrund des nicht deterministischen Outputs von Modellen, klassische Test-Suites nicht mehr ausreichend, um die Qualität der Modelle vor dem Deployment sicherzustellen und es werden zusätzliche Schritte erforderlich. Die Entwicklung von AI-Systemen erfordert neben Softwareentwicklern und Domänenexperten häufig auch Data Scientists, Statistiker oder Mathematiker. Da diese jedoch in anderen Umgebungen arbeiten, resultiert daraus ein größerer Harmonisierungsbedarf der unterschiedlichen Arbeitsumgebungen.
Erkenntnis
Die Entwicklung von AI-Lösungen basiert auf ähnlichen Herausforderungen wie die herkömmliche Softwareentwicklung, bedarf jedoch weiterer Methoden und Herangehensweisen, um der zusätzlichen Komplexität Herr zu werden.
Im zweiten Teil wird ein konkreter Vergleich von Lösungen vorgenommen und deren Vor- und Nachteile beleuchtet. Zudem werden diese nach ihrer Tauglichkeit in spezifische Anwendungsfälle eingeordnet.
Sie haben Interesse an einer Weiterbildung oder Fragen zum Thema Machine Learning? Sprechen Sie uns an oder besuchen Sie einen unserer Kurse aus unserem Seminarshop:
Zu unseren Big-Data-Seminaren
Kommentare