
Sprachunterricht – Von der Lernschwäche zum Autodidakten
Der wahrscheinlich größte begrenzende Faktor in der Entwicklung von Dialogsystemen ist die Diskrepanz zwischen der Dialogmodellierung durch den Entwickler und der tatsächlich durch den Nutzer geführten Dialoge. Idealerweise müsste die Modellierung direkt anhand der Nutzerinteraktionen erfolgen. Um diesem Henne-Ei-Problem zu entgehen, sollte frühestmöglich ein Prototyp des Systems deployt und Nutzerinteraktionen aufgezeichnet werden. Wie diese Daten teilautomatisiert zur Verbesserung des Systems genutzt werden können, erfahren Sie in diesem Beitrag.
Active Learning
Active Learning ist eine Methode des Machine Learnings, welche iterativ externe Quellen anfragt, um neue, bisher ungesehene, Datenpunkte zu annotieren. Diese annotierten Datenpunkte werden verwendet, um das System neu zu trainieren und die Performance schnellstmöglich zu steigern. Das lernende System verfügt dabei über Strategien, aus dem Pool an neuen Datenpunkten so auszuwählen, dass der Informationsgewinn optimiert wird. Die externen Quellen werden Oracle genannt und können durch Menschen, aber auch durch Algorithmen repräsentiert werden. Wenn Algorithmen als Oracle eingesetzt werden, spricht man auch von Weak Supervision.
Anwendung auf Dialogsysteme
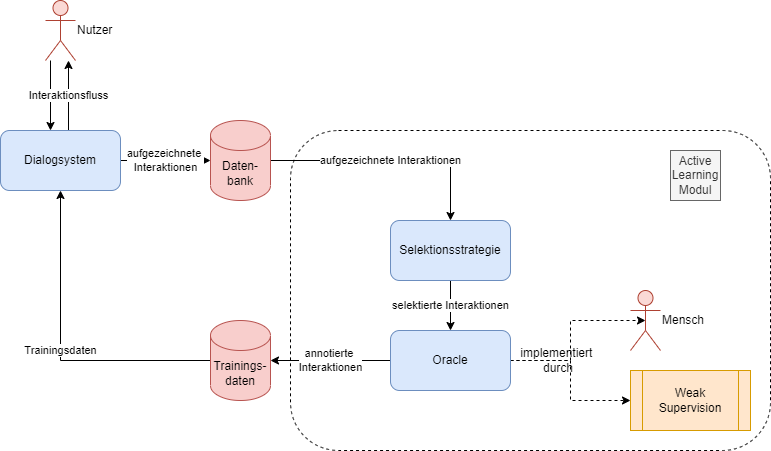
Zur Anwendung von Active Learning auf Dialogsystemen wird der oben abgebildete Workflow benötigt. Zunächst müssen die Interaktionen zwischen Nutzer und Dialogsystem aufgezeichnet werden. Im nächsten Schritt können diese Interaktionen nun an das Active-Learning-Modul weitergegeben werden. Diese selektiert Daten mit potenziell hohem Informationsgewinn und leitet diese an ein Oracle zur Annotation weiter. Die daraus neu entstandenen Trainingsdaten fließen dann zurück in das Dialogsystem, um dieses zu verbessern. Je nach Datenstruktur oder Zielvorgabe können jetzt unterschiedliche Strategien verwendet werden. Sollen beispielsweise lediglich Nutzereingaben zu Intents zugeordnet werden, eignet sich eventuell ein Weak-Supervision-Algorithmus, um Kosten zu sparen. Sollen hingegen längere Interaktionsstränge annotiert werden, ist eine menschliche Annotation vermutlich unumgänglich.
Implementation mit Rasa, whatlies und human-learn
Um den obigen Workflow mit Rasa zu implementieren, müssen zunächst die Nutzerinteraktionen aufgezeichnet werden. Hierzu bietet Rasa ein Modul namens „tracker_store“ an. Dies persistiert die Daten in einem Datenbanksystem, wie beispielsweise Redis, MongoDB oder in einer relationalen Datenbank. Um diese Funktionalität nutzen zu können, müssen lediglich die Verbindungsdaten des Datenbanksystems in der Konfigurationsdatei endpoints.yml in dem Rasa-Projekt angegeben werden. Im Folgenden ist eine Beispielkonfiguration für eine PostgreSQL-Datenbank aufgeführt:
tracker_store: type: SQL # Typ der Datenbank dialect: “postgresql“ # Dialekt der DB url: “localhost“ # Host der SQL DB db: “rasa“ # Pfad zur Datenbank username: rasa # Nutzername zur Authentifizierung password: rasa_secret # Passwort zur Authentifizierung
Aus diesem Datenbestand können nun Abfragen erstellt werden, welche durch einen Active-Learning-Algorithmus bewertet und an ein Oracle weitergeleitet werden können.
Eine mögliche Implementation eines Workflows für die Annotation durch menschliche Mitarbeiter wird im Folgenden anhand der Python-Bibliotheken „whatlies“ und „human-learn“ gezeigt.
Zunächst werden die benötigten Bibliotheken importiert und sogenannte Embeddings geladen, mit denen Texte in eine numerische, maschinenlesbare Form gebracht werden können:
import pathlib
import numpy as np
from whatlies.language import CountVectorLanguage, UniversalSentenceLanguage, BytePairLanguage, SentenceTFMLanguage
from whatlies.transformers import Pca, Umap
lang_cv = CountVectorLanguage(10)
lang_use = UniversalSentenceLanguage()
lang_bp = BytePairLanguage("de", dim=300, vs=200_000)
Anschließend können die durch das Active Learning ausgewählten Interaktionsdaten geladen und durch die Embeddings vektorisiert werden. Um die Cluster der vektorisierten Texte visuell bewerten zu können, können die hochdimensionalen Embeddingvektoren mittels sogenannter Dimensionalitätsreduktionsalgorithmen in eine zweidimensionale Repräsentation projiziert werden:
with open("selected_interactions.txt", "r", encoding="utf8") as f:
texts = f.readlines()
def make_plot(lang):
return (lang[texts]
.transform(Umap(2))
.plot_interactive(annot=False)
.properties(width=200, height=200, title=type(lang).__name__))
make_plot(lang_cv) | make_plot(lang_bp) | make_plot(lang_use)
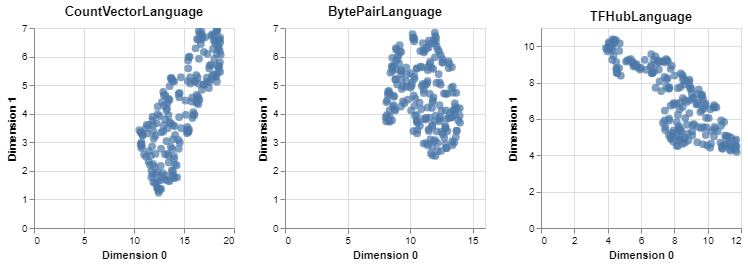
Das Embedding, welches für die vorhandenen Daten die vielversprechendsten Cluster generiert, kann so bestimmt werden, um im Anschluss die Daten einfach labeln zu können. Hierfür wird die Bibliothek „human-learn“ genutzt, welche das schnelle visuelle Labeln ermöglicht:
from hulearn.experimental.interactive import InteractiveCharts df = lang_use[texts].transform(Umap(2)).to_dataframe().reset_index() df.columns = ['text', 'd1', 'd2'] df['label'] = '' df.shape[0] charts = InteractiveCharts( df.loc[lambda d: d['label'] == ''], labels=['group']) charts.add_chart(x='d1', y='d2')
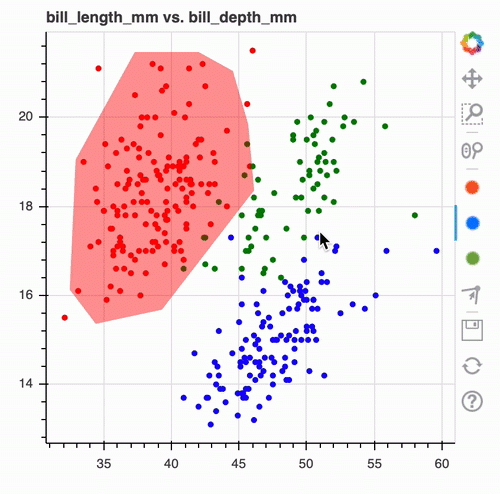
Die Daten innerhalb des gekennzeichneten Clusters können nun nochmal angezeigt und dahingehend überprüft werden, ob die Texte bspw. alle einem Intent zugeordnet werden können.
from hulearn.preprocessing import InteractivePreprocessor tfm = InteractivePreprocessor(json_desc=charts.data()) df.pipe(tfm.pandas_pipe).loc[lambda d: d['group'] != 0].sample(10)
Ist dies der Fall, kann den Daten ein Label zugeordnet und diese exportiert werden, um neue Trainingsdaten zu bilden.
label_name = 'intent_XY'
idx = df.pipe(tfm.pandas_pipe).loc[lambda d: d['group'] != 0].index
df.iloc[idx, 3] = label_name
df.to_csv("first_order_labelled.csv")
Auf diese Weise können die Interaktionsdaten schnell in Batches visualisiert, gelabelt und händisch korrigiert werden.
Fazit
In dieser Artikelreihe wurden Designmuster und Algorithmen vorgestellt, um höherwertige Dialogsysteme, nach dem eingangs definierten Klassifikationsschema, zu entwickeln. Zudem wurden beispielhafte Implementationen anhand des Rasa-Frameworks aufgezeigt. Falls Sie mehr zu den vorgestellten Techniken erfahren möchten, besuchen Sie eines unserer topaktuellen Webinare/Seminare, wie das Active Learning Webinar oder das Machine Learning Basics Seminar. Sollten Sie Unterstützung bei einem zukünftigen oder laufenden Projekt benötigen, kontaktieren Sie uns ebenfalls gerne - wir antworten auch persönlich! ;-)
Seminarempfehlungen
AI/ACTIVE LEARNING - KOSTENLOSES WEBINAR W-AI-02
Zum SeminarMACHINE LEARNING BASICS W-AI-01
Zum Seminar
Kommentare