
Stein auf Stein: Die Stackable Data Platform (2/2)
Dies ist der zweite Teil unserer Artikelserie, die sich mit dem Deployment der Stackable Data Platform (SDP) beschäftigt. Im ersten Teil haben wir die grundlegenden Aspekte von Stackable eingeführt und einen Überblick über die wesentlichen Komponenten gegeben. In diesem Teil gehen wir detaillierter auf die Schritte und Best-Practices für das Deployment von Stackable ein. Für weiterführende Informationen zur Nutzung von Stackable und detaillierte Erläuterungen, besuchen Sie bitte den ersten Teil.
Operator
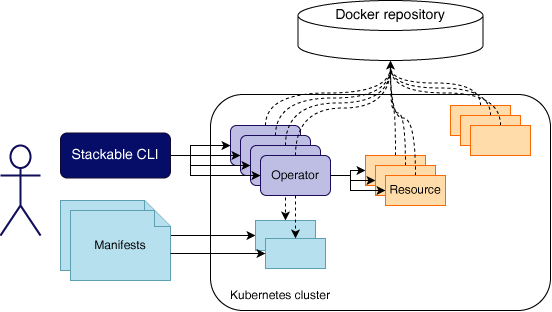
Erstaunlicherweise ist die eigentliche Installation der Stackable Data Platform der einfachste Teil in dieser Blog-Serie. In diesem Schritt setzen wir einen HDFS-Cluster auf. Das geschieht auf besonders benutzerfreundliche Weise durch die Verwendung von Stackable-Operatoren. Diese Operatoren sind speziell dafür konzipiert, die benötigten Ressourcen in Containern zu verwalten und bereitzustellen. Die Installation erfolgt dabei über Manifest-Dateien, die von stackablectl in Ihrer Kubernetes-Umgebung angewendet werden. Durch diesen Prozess können Sie effizient und automatisiert ein funktionsfähiges HDFS-Cluster aufbauen.
stackablectl operator install secrets listener commons zookeeper hdfs
Führen Sie diesen Befehl aus, um alle verfügbaren Operatoren zu sehen, die Sie in Ihrer Stackable Data Platform (SDP) installieren können:
stackablectl operator list
Das Starten des eigentlichen HDFS-Clusters und des dafür notwendigen ZooKeeper-Clusters, wird mittels yaml-Manifesten durchgeführt. Die unten aufgeführten Manifeste sind einfache Beispiele und können je nach Bedarf angepasst werden.
cat zk.yaml
--- apiVersion: zookeeper.stackable.tech/v1alpha1
kind: ZookeeperCluster
metadata:
name: simple-zk
spec:
image:
productVersion: 3.8.3
servers:
roleGroups:
default:
replicas: 1
kubectl apply –f zk.yaml
cat znode.yaml
---
apiVersion: zookeeper.stackable.tech/v1alpha1
kind: ZookeeperZnode
metadata:
name: simple-hdfs-znode
spec:
clusterRef:
name: simple-zk
kubectl apply -f znode.yaml
cat hdfs.yaml
---
apiVersion: hdfs.stackable.tech/v1alpha1
kind: HdfsCluster
metadata:
name: simple-hdfs
spec:
image:
productVersion: 3.3.6
clusterConfig:
zookeeperConfigMapName: simple-hdfs-znode
dfsReplication: 1
nameNodes:
config:
listenerClass: external-stable
roleGroups:
default:
replicas: 2
dataNodes:
config:
listenerClass: external-unstable
roleGroups:
default:
replicas: 1
journalNodes:
roleGroups:
default:
replicas: 1:
kubectl apply -f hdfs.yaml
Es ist nur möglich Dateien ins HDFS zu laden, indem man WebHDFS benutzt. Dafür ist ein weiterer Container nötig, den man mit diesem Manifest starten kann:
cat webhdfs.yaml
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: webhdfs
labels:
app: webhdfs
spec:
replicas: 1
serviceName: webhdfs-svc
selector:
matchLabels:
app: webhdfs
template:
metadata:
labels:
app: webhdfs
spec:
containers:
- name: webhdfs
image: docker.stackable.tech/stackable/testing-tools:0.2.0-stackable0.0.0-dev
stdin: true
tty: true
Um Dateien ins HDFS zu transferieren sind die folgenden Schritte nötig. Zuerst werden die Dateien in den WebHDFS Container kopiert und von dort mit Curl ins HDFS geladen:
#step1 kubectl cp -n default ./testdata.txt webhdfs-0:/tmpbin/bash #step2 kubectl exec -n default webhdfs-0 -- \ curl -s -XPUT -T /tmp/testdata.txt "http://simple-hdfs-namenode-default-0.simple-hdfs-namenode-default.default.svc.cluster.local:9870/webhdfs/v1/testdata.txt?user.name=stackable&op=CREATE&noredirect=true"
Das Kommando gibt den Speicherort als einen Ausgabewert zurück. Es empfiehlt sich, diesen als Variable zu speichern, da er beim Abrufen der Datei benötigt wird:
export location=http://simple-hdfs-datanode-default-0.simple-hdfs-datanode-default.default.svc.cluster.local:9864/webhdfs/v1/testdata.txt?op=CREATE&user.name=stackable&namenoderpcaddress=simple-hdfs&createflag=&createparent=true&overwrite=false kubectl exec -n default webhdfs-0 -- curl -s -XGET "http://simple-hdfs-namenode-default-0.simple-hdfs-namenode-default.default.svc.cluster.local:9870/webhdfs/v1/?op=LISTSTATUS"
Demos
Mit stackablectl demo list kann man sich vorgefertigte Demos von Stackable anzeigen lassen. Siehe hier.
Viele Container der Demos laden mit curl zusätzliche Daten aus dem Internet herunter. Damit dies mit dem Web-Proxy funktioniert, muss jeder Container manuell mit der Proxy-Variable angepasst werden.
Dazu muss man in jeden Pod wechseln und die Proxy-Variable in der Shell setzen:
kubectl exec pod -it -- /bin/bash export http_proxy=http://proxy:port
Eine andere Möglichkeit wäre es, Admission Webhooks zu benutzen, um Manifest-Dateien automatisiert zu bearbeiten. Dies wird hier jedoch nicht weiter beschrieben.
Alle installierbaren Demos kann man anzeigen mit:
stackablectl demo list
Nun kann man mit fertig erstellten Stackable Cluster arbeiten, das auch hinter einem Web-Proxy funktioniert.
Um dies zu erreichen, wurden zunächst die grundlegenden Voraussetzungen wie DNS, Firewall, Kernel Module und Proxy Settings konfiguriert und installiert. Im Anschluss wurde Kubernetes, die Infrastruktur für Stackable, installiert. Die abschließende Installation von Stackable selbst gestaltet sich einfach und der Aufbau eines Clusters kann mittels Infrastructure as Code in einem Manifest bereitgestellt werden.
Für eine Einführung in die Nutzung sowie den Umgang mit Stacks und Stacklets, lesen Sie bitte den folgenden Artikel zur Stackable Data Platform.
Zusätzlich zu der offiziellen Dokumentation ist dieser Artikel auf der Stackable-Website zu empfehlen.
Für alle, die sich gerne tiefer mit den Themen rund um die Stackable Data Platform beschäftigen möchten, können uns gerne auf unser Stackable Grundlagen Seminar ansprechen.
Viel Spaß mit Stackable :)
Seminarempfehlung
STACKABLE GRUNDLAGEN WORKSHOP STACK-01
Mehr erfahrenSenior Consultant
Kommentare