
Put that away: The MariaDB Storage Engine S3
Many customers operate databases that are constantly growing. This was also the case in this specific instance. Our client operates a very large MariaDB server with several hundred terabytes of data. A large part of the data must remain stored and accessible for regulatory reasons. Changes to this data are no longer made, but must be kept readable. One idea: off to the cloud with it!
Water up the neck!
In this specific case, our client was up to its neck in water. The data stock had grown over several years (decades) into the hundred TB range. When the system was set up, no one ever thought in these dimensions. Due to a very positive development in the business area, the growth has continued to accelerate strongly in the last few years / months, which is why they are currently working on a new data management concept for this business area. The problem is that the new concept and the new infrastructure are not yet "ready". The disk space of the database server, however, "was done".
When you need to go fast!
Currently, quick solutions are being sought that literally keep the system alive until the new solutions are introduced. Due to the (historical) data model with thousands of schemas and hundreds of thousands of tables, many common approaches do not seem to be effective. The tables or the data model is enormously restrained for today's demands on OLTP systems. Measured values or metrics for manufactured products are archived in the tables. Each table represents exactly one product. Transactions and foreign keys are only used in very limited areas, which are not responsible for the enormous amount of data.
Of course, one could try to "defragment" database files, implement compression at the data level, optimize data types and indices or even completely redesign the data model to get some more breathing space. The use of the veteran engine "Archive" was also on the agenda.
Simple and good?
During the discussions, we also noticed the storage engine S3 (stands for Simple Storage Service), which has been available since MariaDB 10.5.4 and seemed to be made for this purpose.
„The S3 storage engine is read only and allows one to archive MariaDB tables in Amazon S3, or any third-party public or private cloud that implements S3 API (of which there are many), but still have them accessible for reading in MariaDB."
Quelle: https://mariadb.com/kb/en/using-the-s3-storage-engine/
The engine promises to "archive" tables in a purely readable form in an S3-compatible storage with little effort. For my small test scenario, I therefore do not reach for the stars or into the cloud but prefer to use containers. For my "setup", I downloaded a current Docker image of a MariaDB and of MinIO. I don't want to go into MinIO any further at this point. For our purpose, the information that the MinIO container provides an S3 API-compatible storage service for our small test setup is sufficient.
Plug and play?
The plugin was not yet available in the MariaDB image I used. However, a subsequent installation was possible without any problems:
bash> apt install mariadb-plugin-s3
Afterward, the plugin could be loaded without any problems via the database server:
MariaDB [(none)]> INSTALL SONAME 'ha_s3';
In parallel, I used the MinIO graphical interface to create a bucket called "mariadb" and the necessary permissions for access.
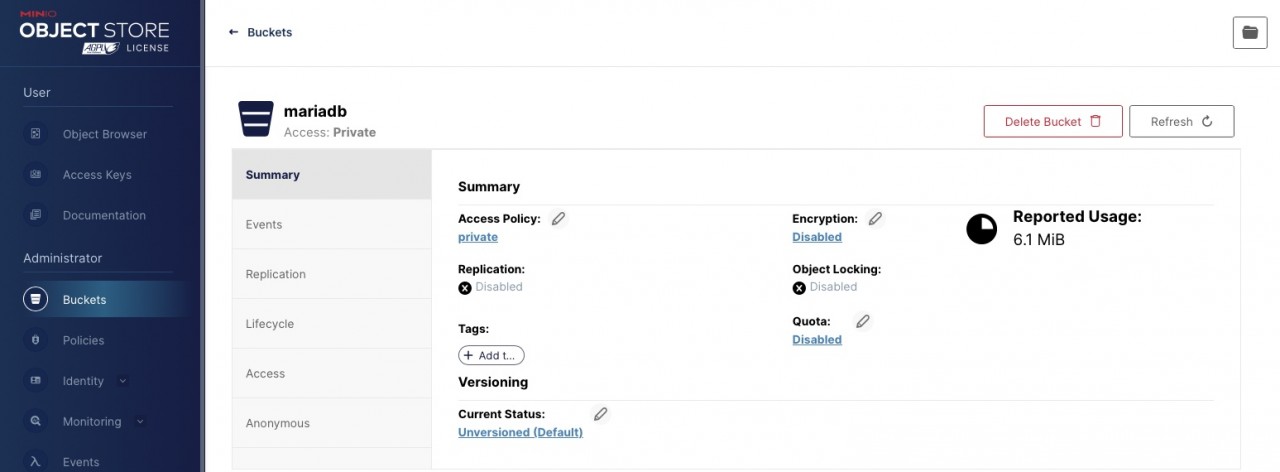
Everything is in the bag … uh … bucket?
To be able to use the "bucket" in MariaDB, a few configurations must be made. An essential prerequisite is, of course, the accessibility of the S3 storage on the network side. In our case, a pure Docker lab environment, this is done with a few commands. In practice, with a database server installed on-prem, it is of course necessary to clarify how a storage service located in the cloud can be accessed. There are also some security-relevant questions to be clarified in advance.
The configuration in our case is as follows:
cat /etc/mysql/mariadb.conf.d/50-server.cnf … [mariadb] s3=ON s3-bucket=mariadb s3-access-key=85TkJlqHyjOQf1c1 s3-secret-key=S9pyyO***** s3-region=eu-north-1 s3-host-name=172.18.0.3 # IP des MinIO Containers s3-debug=On # Fehler sollen protokolliert werden s3-port=9000 s3-use-http=ON
After restarting the DB server, the plugin can be used:
MariaDB [information_schema]> select plugin_name, plugin_status from information_schema.plugins where plugin_name = 'S3'; +-------------+---------------+ | plugin_name | plugin_status | +-------------+---------------+ | S3 | ACTIVE | +-------------+---------------+ 1 row in set (0.001 sec)
That can be gone!
For our test, we build a small, actually a large 😉 table, which we then want to "archive" to the S3 storage. We generate a few data records in the table "bigdata" via a procedure "generate_big_data" and check the result:
DELIMITER //
CREATE PROCEDURE generate_big_data()
BEGIN
DECLARE i INT DEFAULT 0;
DECLARE dataX CHAR(200);
DECLARE dataY CHAR(200);
DROP TABLE IF EXISTS bigdata;
CREATE TABLE bigdata (
id INT NOT NULL AUTO_INCREMENT PRIMARY KEY,
DataX CHAR(200),
DataY CHAR(200)
) ENGINE=InnoDB;
WHILE i < 500000 DO
SET dataX = CONCAT('DataX_', i);
SET dataY = CONCAT('DataY_', i);
INSERT INTO bigdata (DataX, DataY) VALUES (dataX, dataY);
SET i = i + 1;
END WHILE;
END //
DELIMITER ;
MariaDB> select data_length/1024/1022 "data in MB" from information_schema.tables where table_name = 'bigdata';
+--------------+
| data in MB |
+--------------+
| 224.17221135 |
+--------------+
1 row in set (0.011 sec)
Now we move the created table into the engine "S3" via an "alter table" command.
MariaDB> alter table bigdata engine = 'S3'; Query OK, 500000 rows affected (1.744 sec) Records: 500000 Duplicates: 0 Warnings: 0
Access to the data is still possible without any problems. However, adding or deleting records no longer works.
MariaDB> select * from bigdata limit 5; +----+---------+---------+ | id | DataX | DataY | +----+---------+---------+ | 1 | DataX_0 | DataY_0 | | 2 | DataX_1 | DataY_1 | | 3 | DataX_2 | DataY_2 | | 4 | DataX_3 | DataY_3 | | 5 | DataX_4 | DataY_4 | +----+---------+---------+ 5 rows in set (0.027 sec) MariaDB> insert into bigdata values (null, 'X', 'Y'); ERROR 1036 (HY000): Table 'bigdata' is read only MariaDB> delete from bigdata where id < 10; ERROR 1036 (HY000): Table 'bigdata' is read only
Structural changes per "alter table", on the other hand, are permissible:
alter table bigdata add DataZ varchar(100) default "Welcome in S3"; Query OK, 500000 rows affected (1.338 sec) Records: 500000 Duplicates: 0 Warnings: 0 MariaDB [very_big]> alter table bigdata add index I_DataX (DataX); Query OK, 500000 rows affected (2.456 sec)
A look at our bucket also shows that the data has now arrived at our S3 storage. In our case, the data was stored in 4 MB blocks:
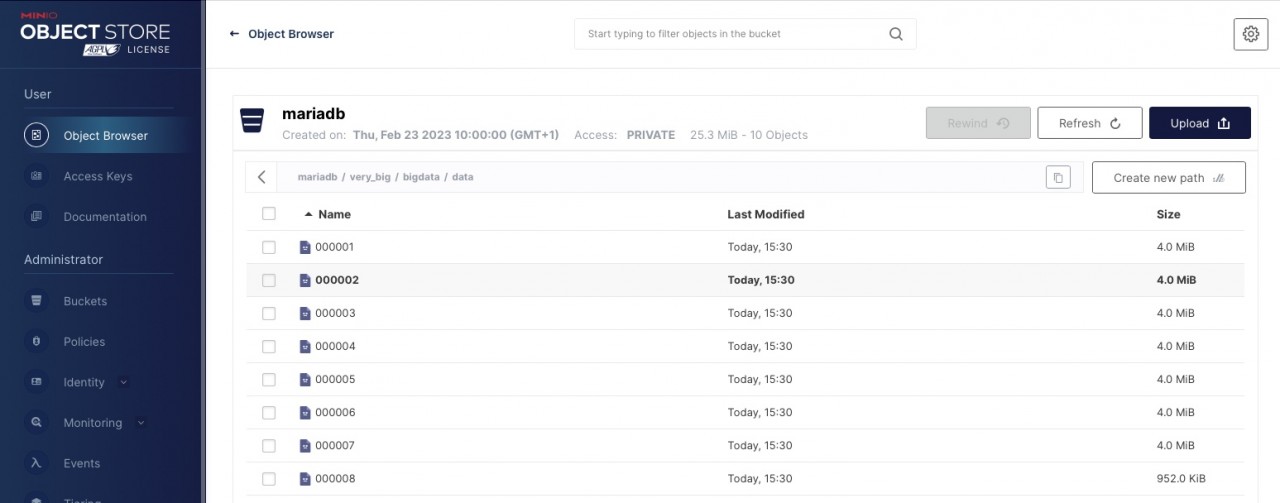
Conclusion: Everything is in the bag … uh … bucket!
The connection of an S3 storage for "archiving" data is easily possible with MariaDB. In addition to the purely technical functionality, which is what we are talking about here, there are of course fundamental questions that need to be clarified in advance:
- Can I live with the limitations of the storage engine?
- What does the performance look like?
- Can I connect a remote (in the cloud) S3 storage at all?
- What impact will this have on my backup concept?
- ...
Do you also have a space problem on your MySQL and / or MariaDB server? Please contact us. We are also happy to discuss other database products.
Principal Consultant bei ORDIX
Kommentare