
Wenn KI den Spickzettel zückt (1/2): Wie funktioniert Retrieval Augmented Generation (RAG)?
Wir möchten euch Lisa vorstellen. Lisa kommt ins Büro und muss dringend eine wichtige rechtliche Information für ihr aktuelles Projekt finden. Vor ihr liegt ein riesiges PDF-Dokument mit den neuesten gesetzlichen Bestimmungen – seitenlang, komplex und unübersichtlich. Sie weiß, dass irgendwo in diesem Dokument die Antwort steckt, aber sie hat weder die Zeit noch die Nerven, sich durch all die Paragrafen zu kämpfen.
Zum Glück gibt es KI! Statt stundenlang zu suchen, lädt Lisa das PDF einfach in einen KI-Assistenten. Dieser durchsucht das Dokument für Lisa und liefert eine präzise Antwort auf ihre spezifische Frage. Dieser Prozess lässt sich als Augmented Generation bezeichnen.
Und es wird noch besser: In Zukunft muss Lisa nicht einmal mehr das Dokument selbst hochladen, sondern die KI findet es eigenständig. Dieser Ansatz wird als Retrieval Augmented Generation (RAG) bezeichnet, eine Technologie, die den gesamten Prozess effizienter macht. Auch Lisas Chef kann davon profitieren, denn wenn weniger Zeit für mühsame Recherchen investiert wird, dann bleibt seinem Team mehr Raum für strategische und kreative Aufgaben.
In diesem Artikel erklären wir, wie RAG funktioniert, welche Vorteile und Herausforderungen es gibt und wo es bereits erfolgreich eingesetzt wird.
Was ist Retrieval Augmented Generation (RAG)?
RAG verbindet die beiden Hauptkomponenten Retrieval und Generation:
Retrieval (Nachschlagen): Das System ruft relevante Informationen aus einer Wissensdatenbank, einem Dokumentarchiv oder sogar dem Internet ab.
Generierung (Antworten): Basierend auf den gefundenen Daten erstellt ein Sprachmodell eine sinnvolle, kontextspezifische Antwort. Dabei werden seine Fähigkeiten erweitert („Augmented"), indem es nicht nur auf sein vorab trainiertes Wissen zugreift, sondern auch die zuvor gefundenen Daten einbezieht.
Dieses zweistufige Verfahren ermöglicht es Sprachmodellen, gezielt auf domänenspezifische und aktuelle Informationen zuzugreifen, anstatt sich ausschließlich auf ihr statisches Trainingswissen zu verlassen.
Der RAG-Prozess
Um den Ablauf von RAG besser zu verstehen, werfen wir einen Blick auf das folgende Schaubild:
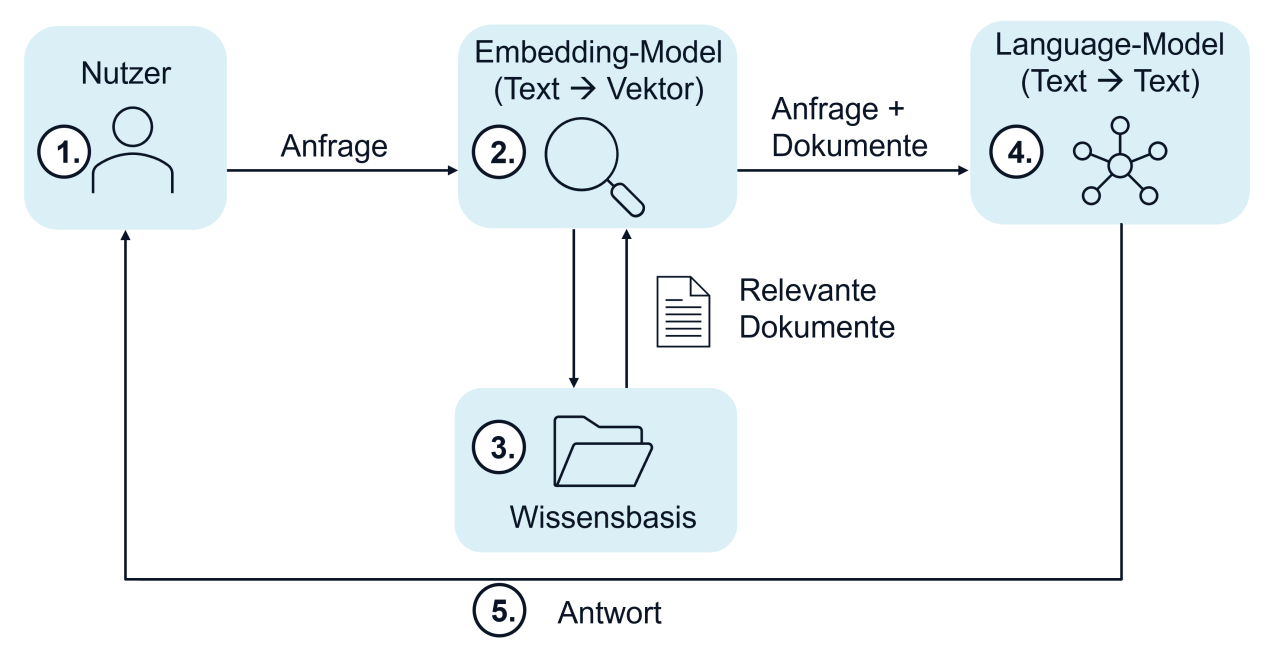
- Ein:e Nutzer:in stellt eine Anfrage – Das kann eine konkrete Frage sein, wie „Welche Vorteile hat RAG?", oder eine offene Suchanfrage, wie „Informationen über RAG-Architektur".
- Ein Embedding-Model verarbeitet die Anfrage – Es wandelt den Text in einen numerischen Vektor um, der die semantische Bedeutung der Anfrage erfasst. Dieser Vektor wird dann genutzt, um in der Wissensbasis nach ähnlichen Inhalten zu suchen.
- Die Wissensbasis wird durchsucht – Die gespeicherten Dokumente liegen ebenfalls als Vektoren vor. Durch einen Vergleich der Vektoren wird ermittelt, welche Dokumente inhaltlich am besten zur Anfrage passen. Je ähnlicher sich die Vektoren sind, desto näher liegen auch ihre Bedeutungen beieinander.
- Ein Language-Model verarbeitet die Informationen – Das Sprachmodell bekommt die ursprüngliche Anfrage und die gefundenen Dokumente, um daraus eine präzise Antwort zu generieren.
- Die Antwort wird an den/die Nutzer:in zurückgegeben – Das System gibt die generierte Antwort an den/die Nutzer:in aus.
Vorteile von RAG
Der Einsatz von Retrieval Augmented Generation bringt mehrere Vorteile mit sich:
- Aktualität: Anders als klassische Sprachmodelle, die nur auf ihrem Trainingsdatensatz basieren, kann RAG auf aktuelle Informationen zugreifen, ohne ein zeitaufwendiges und rechenintensives Retraining zu erfordern.
- Genauigkeit: Durch die Integration spezifischer Wissensquellen erhöht sich die Präzision der Antworten, insbesondere bei komplexen oder domänenspezifischen Fragen.
- Flexibilität: Unternehmen können ihre eigenen Wissensdatenbanken einbinden, um maßgeschneiderte und relevante Antworten zu erhalten. Dazu gehören beispielsweise interne Dokumentationssysteme, Wissensmanagement-Plattformen, Support-Ticketsysteme oder ERP-Systeme.
Herausforderungen von RAG
Trotz der Vorteile gibt es einige Herausforderungen bei der Implementierung von RAG:
- Qualität der Wissensbasis: Die Genauigkeit und Relevanz der Antworten hängen maßgeblich von der Qualität, Aktualität und Struktur der hinterlegten Wissensquellen ab. Unvollständige, veraltete oder schlecht aufbereitete Daten können zu fehlerhaften oder unbrauchbaren Ergebnissen führen. Dem kann durch regelmäßige Aktualisierung, strukturierte Datenaufbereitung und kuratierte Inhalte entgegengewirkt werden.
- Fehleranfälligkeit beim Retrieval: Das System muss relevante Informationen aus einer großen Menge an Dokumenten abrufen. Falls das Retrieval fehlschlägt oder irrelevante Inhalte liefert, kann das Sprachmodell falsche oder unpassende Antworten generieren, selbst wenn die eigentliche Wissensbasis korrekt ist. Der Einsatz fortschrittlicher Suchalgorithmen oder die Implementierung von Feedback-Mechanismen, bei denen die abgerufenen Dokumente nochmals auf Relevanz hinsichtlich der Anfrage geprüft werden, kann die Abrufqualität optimieren.
- Halluzinationen: Obwohl RAG gezielt externe Informationen abruft, besteht weiterhin das Risiko, dass das Modell Fakten erfindet oder falsche Zusammenhänge herstellt. Dies kann passieren, wenn das Sprachmodell Lücken in den Daten mit plausibel klingenden, aber falschen Aussagen füllt. Gänzlich ausschließen lassen sich Halluzinationen bei generativen Modellen nicht, aber das Risiko lässt sich verringern, indem das Modell Unsicherheiten kennzeichnet oder Quellenhinweise gibt. Zudem helfen Reflektions-Mechanismen, bei denen die generierte Ausgabe nochmals überprüft wird.
- Datenschutzbedenken: Die Nutzung externer Sprachmodell-Anbieter kann Datenschutzfragen aufwerfen, insbesondere wenn sensible Unternehmensdaten verarbeitet werden. Eine Alternative besteht darin, selbst gehostete Modelle zu nutzen, die jedoch entsprechende IT-Ressourcen und Wartung erfordern.
Anwendungsfälle von RAG
RAG kann für ein breites Spektrum an Anwendungsfällen eingesetzt werden:
- Kundensupport: Unternehmen können Chatbots mit RAG ausstatten, um personalisierte und präzise Antworten auf Kundenanfragen zu geben.
- Unternehmensinterne Wissensmanagementsysteme: Mitarbeitende können durch RAG-gestützte Systeme effizienter auf relevante Informationen zugreifen, ohne lange in Dokumentationen suchen zu müssen.
- Analyse wissenschaftlicher Dokumente: In der Forschung hilft RAG dabei, relevante wissenschaftliche Artikel und Studien schnell zu identifizieren und Informationen effizient zusammenzufassen.
- Softwareentwicklung: Entwickler:innen können RAG verwenden, um Code-Snippets zu finden, Fehler zu analysieren und technische Dokumentationen schneller zu durchsuchen.
- Marketing & Marktforschung: Unternehmen setzen RAG ein, um Marktanalysen zu automatisieren, Trends zu erkennen und aussagekräftige Berichte zu erstellen.
- Recht & Compliance: Juristische Abteilungen nutzen RAG zur schnellen Analyse von Verträgen, Gesetzen und Richtlinien, um fundierte Entscheidungen zu treffen.
- Bildung & E-Learning: Lernplattformen integrieren RAG, um personalisierte Erklärungen zu liefern, Lernmaterialien verständlich aufzubereiten und gezielt bei Fragen zu helfen.
Wie fange ich an mit RAG?
Um ein RAG-System erfolgreich aufzubauen, sind mehrere technische Komponenten erforderlich:
- Sprachmodelle: Auswahl eines geeigneten Modells wie GPT, Gemini, Llama oder DeepSeek.
- Embeddingmodelle: Wandeln Text in Vektoren um, z. B. mit text-embedding-ada-002, BGE oder E5.
- Vektordatenbanken: Systeme wie ChromaDB, Pinecone oder Weaviate speichern und durchsuchen eingebettete Dokumente effizient.
- Frameworks: Open-Source-Tools wie LangChain oder Haystack erleichtern die Orchestrierung der verschiedenen Komponenten. Eine flexible Möglichkeit zur Steuerung von RAG-Workflows bietet LangGraph, das wir bereits in einem eigenen Blogartikel vorgestellt haben. (https://blog.ordix.de/ki-workflows-mit-langgraph-zum-intelligenten-agenten)
- Datenquellen: Eine strukturierte und qualitativ hochwertige Sammlung von Dokumenten und Wissen für akkurate Ergebnisse.
Im zweiten Teil dieser Blogartikel-Reihe werden wir Schritt für Schritt zeigen, wie ihr ein RAG-System in der Praxis umsetzen könnt.
Fazit
Retrieval Augmented Generation bietet eine innovative Möglichkeit, KI-Modelle mit aktuellen und spezifischen Informationen anzureichern. Durch die Kombination von gezieltem Nachschlagen und intelligenter Antwortgenerierung kann RAG die Effizienz in Unternehmen erheblich steigern. Trotz bestehender Herausforderungen zeigt sich das Potenzial dieser Technologie in diversen Einsatzgebieten. Und die Entwicklung geht weiter: Bereits heute ermöglichen RAG-Systeme die Verarbeitung multimodaler Datenquellen (Text, Bilder, Videos) und integrieren sich nahtlos in Unternehmenslösungen.
Möchtet ihr wissen, wie ihr RAG für euer Unternehmen nutzen können? Kontaktiert uns gerne und lasst uns gemeinsam herausfinden, wie diese Technologie eure Prozesse beschleunigen kann!
Seminarempfehlungen
GRUNDLAGEN MODERNER DATENNUTZUNG - DATA LITERACY DATA-LIT
Mehr erfahrenMACHINE LEARNING BASICS DB-AI-01
Mehr erfahrenJunior Consultant bei ORDIX
Kommentare