
Code Coverage – Kein zuverlässiges Qualitätsmaß
Eine der typischen Anforderungen an neue Software ist ein vorgegebenes Mindestmaß an Code Coverage, also am Anteil des Quellcodes, welcher durch automatisierte Tests ausgeführt wird. Vor allem in Bereichen wie Medizintechnik, Autoindustrie oder Finanzsysteme wird nicht selten 100 % Code Coverage verlangt. Doch selbst ein vollständig durch Tests abgedeckter Code ist nicht zwangsläufig fehlerfrei. Im vorliegenden Artikel lernen wir, was sich hinter dem Begriff Code Coverage verbirgt und warum eine 100%ige Abdeckung trügerisch sein kann. Wir stellen fest, dass die Kombination von Codeabdeckung mit sinnvollen Prüfungen in den Tests selbst und zusätzlichem Einbeziehen von Mutationstests wesentlich aussagekräftiger und erstrebenswerter für die Beurteilung der Codequalität ist, als das Messen der Abdeckung allein.
Bedeutung des Begriffs Code Coverage
Unter Code Coverage (Codeabdeckung) versteht man den prozentualen Anteil des Quellcodes, der von mindestens einem Test ausgeführt wird. Simpel ausgedrückt, lässt sich Code Coverage mittels folgender Formel berechnen:
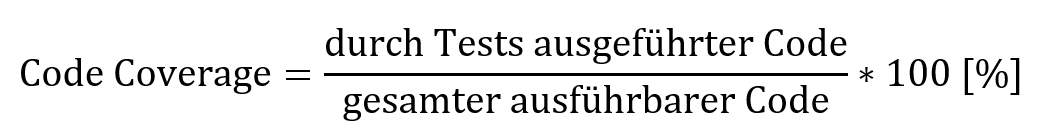
Mittels integrierter Werkzeuge (Beispiele sind weiter unten zu finden) führen die Entwickler:innen die Messung der Code Coverage normalerweise während der Durchführung der Unit- und Integrationstests durch.
Arten von Code Coverage
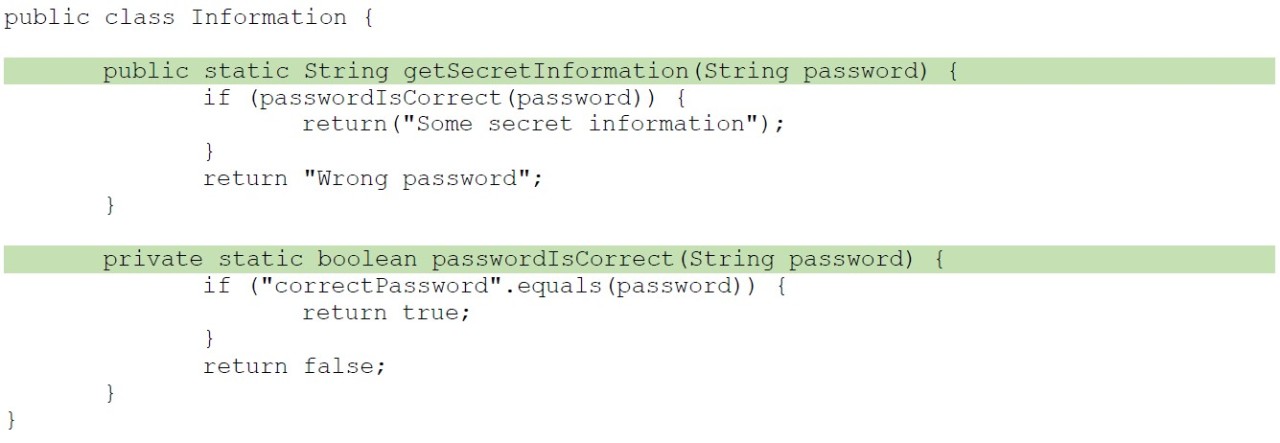
Function/Method Coverage (Funktionsabdeckung) = Anteil der Methoden, die (direkt oder indirekt) von mindestens einem Test aufgerufen werden.
Betrachten wir eine Klasse mit zwei Methoden und die dazugehörige Testklasse:
public class InformationTest {
@Test
public void testGetSecretInformation() {
String information = Information.getSecretInformation("correctPassword");
Assertions.assertEquals("Some secret information", information);
}
}
Durch den einzigen Unit-Test erhalten wir eine Funktionsabdeckung von 100 %, da der Aufruf der ersten Methode direkt im Test stattfindet und die zweite Methode von der ersten aufgerufen wird.
Line Coverage (Zeilenabdeckung) = Anteil der Codezeilen, in denen mindestens eine Anweisung innerhalb von mindestens einem Test aufgerufen wird.
Betrachten wir das obige Beispiel:

public class InformationTest {
@Test
public void testGetSecretInformation() {
String information = Information.getSecretInformation("correctPassword");
Assertions.assertEquals("Some secret information", information);
}
}
Wir sehen, dass nicht alle Zeilen durch den gegebenen Test abgedeckt werden. In beiden Methoden werden die letzten Zeilen nicht berührt, was wir durch einen zweiten Test nachholen können:
public class InformationTest {
@Test
public void testGetSecretInformation() {
String information = Information.getSecretInformation("correctPassword");
Assertions.assertEquals("Some secret information", information);
}
@Test
public void testGetSecretInformationWrongPassword() {
String returnValue = Information.getSecretInformation("wrongPassword");
Assertions.assertEquals("Wrong password", returnValue);
}
}
Nun haben wir nicht nur 100 % Funktionsabdeckung, sondern auch 100 % Zeilenabdeckung.

Branch Coverage (Zweigabdeckung) = Anteil der Zweige, die durch mindestens einen Test durchlaufen werden. Verzweigungen entstehen beispielsweise bei if-Abfragen und eine vollständige Zweigabdeckung kann dadurch erreicht werden, dass jeder Zweig durch einen Test ausgeführt wird. Bei einer if-Abfrage mit einer einzelnen Bedingung müssen also sowohl der true- als auch der false-Fall abgedeckt sein. Eine Schleife gilt als abgedeckt, wenn der true- und der false-Fall der Abbruchbedingung mindestens einmal eingetroffen sind. Im obigen Beispiel haben wir durch zwei vorliegende Tests bereits 100 % Branch Coverage erreicht.
Diese Art von Coverage ist insofern interessant, als es möglich ist, eine vollständige Zeilenabdeckung zu erreichen, jedoch nicht alle Szenarien des Funktionsablaufs zu berücksichtigen und so evtl. Fehler zu übersehen. Sehen wir uns die folgende fehlerhafte Funktion an:
public class SoccerMatch {
public static String getWinner(int goalsTeam1, int goalsTeam2) {
String winner = null;
if (goalsTeam1 > goalsTeam2) {
winner = "Team1";
}
return winner;
}
}
Schreiben wir nun einen Test, in dem wir das Szenario getWinner(2,1) prüfen, so erhalten wir das erwartete Ergebnis (der Gewinner ist Team1) und außerdem eine vollständige Funktions- und Zeilenabdeckung. Die Zweigabdeckung beträgt allerdings nur 50 %, da wir nur einen von zwei Zweigen durch den Test abdecken.

Fügen wir nun einen zweiten Test mit dem Aufruf getWinner(1,2) hinzu, um den zweiten Zweig abzudecken, so erhalten wir natürlich nicht Team2 als Gewinner und haben den Fehler entdeckt.
Path Coverage (Pfadabdeckung) = Anteil der Pfade, die durch mindestens einen Test durchlaufen werden. Um den Unterschied zwischen Branch und Path Coverage deutlich zu machen, schauen wir uns folgendes Beispiel an:
public class Greeting {
public static String greeting(boolean hasBirthday, boolean myFriend) {
String message = "Hello."; // 0
if (hasBirthday) { // 1
message += " Happy birthday!"; // 2
}
if (myFriend) { // 3
message += " Have a nice day!"; // 4
}
return message; // 5
}
}
Durch die Testaufrufe von greeting(true, true) und greeting(false, false) erreichen wir eine vollständige Zweigabdeckung, aber die Pfadabdeckung beträgt damit nur 50 %, da wir zwar die Pfade 0-1-2-3-4-5 und 0-1-3-5 dadurch abgedeckt haben, aber nicht die Pfade 0-1-2-3-5 (das wäre der Aufruf greeting(true, false)) und 0-1-3-4-5 (Aufruf greeting(false, true)).
Vor allem durch Schleifen entsteht schnell eine extrem hohe (unter Umständen sogar eine unendliche) Anzahl an Pfaden, die alle durch Tests abgedeckt sein müssten, um eine Pfadabdeckung von 100 % zu erreichen. Daher werden häufig etwas abgeschwächte Versionen der Pfadabdeckung ermittelt, indem die Anzahl der geforderten abgedeckten Pfade auf eine bestimmte Zahl reduziert wird.
Es gibt noch zahlreiche weitere Arten von Code Coverage (Loop Coverage, Statement Coverage, Parameter Value Coverage …), in der Praxis werden jedoch überwiegend Line und Branch Coverage als Metriken verwendet.
Hohe Abdeckung zeugt nicht von hoher Qualität
Selbst eine 100%ige Codeabdeckung (welcher Art auch immer) bietet keine Garantie für fehlerfreien Code. Schauen wir uns nochmal die Klasse SoccerMatch an. Um eine vollständige Zweigabdeckung (Branch Coverage) zu erreichen, haben wir zwei Unit-Tests geschrieben und die Szenarien „Team1 gewinnt“ und „Team2 gewinnt“ getestet. Das zweite Szenario in der ursprünglichen Variante lieferte nicht das erwartete Ergebnis. Angenommen, wir haben die Funktion wie folgt geändert:
public class SoccerMatch {
public static String getWinner(int goalsTeam1, int goalsTeam2) {
String winner = null
if (goalsTeam1 > goalsTeam2) {
winner = "Team1";
}
else {
winner = "Team2";
}
return winner;
}
}
Nun liefern die Tests mit den Aufrufen getWinner(2,1) und getWinner(1,2) jeweils das erwartete Resultat und 100 % Zweigabdeckung sind auch erreicht. Alles wunderbar? Jedoch, nur für Team2, denn beim Aufruf von getWinner(1,1) würden wir feststellen, dass bei Gleichstand das zweite Team den Sieg feiert, unsere Methode also trotz Abdeckung nicht fehlerfrei ist. Erst durch folgende Anpassung …
public class SoccerMatch {
public static String getWinner(int goalsTeam1, int goalsTeam2) {
String winner = null
if (goalsTeam1 > goalsTeam2) {
winner = "Team1";
}
else if (goalsTeam1 < goalsTeam2) {
winner = "Team2";
}
return(winner);
}
}
… wird die Methode fehlerfrei und liefert beim Testaufruf von getWinner(1,1) erwartungsgemäß null. Eine Aufwertung der Methode könnte allerdings noch durch das Ausschließen der negativen Eingaben erreicht werden.
Außerdem ist es wichtig zu berücksichtigen, dass für die Abdeckung nur die jeweiligen Aufrufe innerhalb der Tests ausschlaggebend sind, die Existenz von Assertions ist für die Berechnung irrelevant, denn diese berücksichtigt nur die Aufrufe der Codestellen. Somit ist es möglich, 100 % Code Coverage zu erhalten und dabei in keiner Weise das Verhalten des Programms zu prüfen.
Folgende fehlerhafte Methode …
public class Access {
public static String getAccessMessage(boolean denied) {
String message = "Access allowed";
if (denied) {
message.replace("allowed", "denied");
}
return message;
}
}
… kann durch die folgenden Tests vollständig abgedeckt werden:
public class AccessTest {
@Test
public void testAccessAllowed() {
String message = getAccessMessage(false);
}
@Test
public void testAccessDenied() {
String message = getAccessMessage(true);
}
}
Aber nur durch korrekte Assertions, d. h. durch das Prüfen, ob message tatsächlich den jeweils erwarteten Inhalt hat, wird auffallen, dass im true-Fall (also im zweiten Test) die Nachricht keinesfalls „Access denied“ lautet. Wenn wir also die Tests um sinnvolle Überprüfungen der Rückgabe erweitern, stellen wir fest, dass der zweite Test durchfällt.
public class AccessTest {
@Test
public void testAccessAllowed() {
String message = getAccessMessage(false);
Assertions.assertEquals("Access allowed", message);
}
@Test
public void testAccessDenied() {
String message = getAccessMessage(true);
Assertions.assertEquals("Access denied", message);
}
}
Die korrekte Implementierung der obigen Methode sieht wie folgt aus:
public class Access {
public static String getAccessMessage(boolean denied) {
String message = "Access allowed";
if (denied) {
message = message.replace("allowed", "denied");
}
return message;
}
}
Bestimmung von Code Coverage
Zahlreiche gängigen IDEs bieten Tools, welche die Codeabdeckung bestimmen und anzeigen können, z. B. JaCoCo für Java oder coverage.py für Python. Die Abdeckung wird während des Testdurchlaufs ermittelt und anschließend in Form eines Coverage Reports angezeigt. Häufig bieten die Tools die Möglichkeit zu bestimmen, welche Art der Abdeckung berechnet werden soll, oder auch gewisse Programmteile von der Berechnung auszuschließen (beispielsweise Testklassen oder automatisch generierte Getter/Setter-Methoden).
Fazit
Code Coverage bietet den Softwareentwickler:innen eine gute Orientierung für die Erstellung der Tests und weist auf Stellen im Quellcode hin, die möglicherweise nicht ausreichend durch Tests abgedeckt sind, vielleicht sogar unerreichbar sind und demnach Refactoring benötigen.
Ein hohes Maß an Code Coverage hingegen vermittelt den Eindruck einer sorgfältig getesteten Software und suggeriert damit eine niedrige Fehlerwahrscheinlichkeit.
In der Praxis zeugt allein ein hoher Abdeckungsgrad jedoch nicht zwangsläufig von hoher Qualität der Tests und auch der Software. Selbst, wenn ein Test keinerlei Assertions beinhaltet (und die Funktionsweise der aufgerufenen Methoden somit nicht überprüft), so sorgt ein solcher Test dennoch für Codeabdeckung. Hohe geforderte Abdeckung animiert außerdem zum Schreiben von wenig aussagekräftigen oder sogar überflüssigen Tests und kostet unnötig Zeit und Geld.
Es hat sich gezeigt, dass eine Codeabdeckung von 60 bis 80 % bereits eine gute Richtlinie darstellt und es wesentlich wichtiger ist, darauf zu achten, dass diese Zahl während der Weiterentwicklung nicht sinkt. Zusätzlich müssen die vorliegenden Tests nicht nur den Code abdecken, sondern auch sinnvolle Assertions beinhalten und das Verhalten der aufgerufenen Methoden entsprechend der gestellten Anforderungen prüfen, damit man eine Aussage über die Qualität der Tests und der Software machen kann. Zudem bieten Mutationstests eine zusätzliche Möglichkeit, die Qualität der automatisierten Tests zu messen. Die Bedeutung und Verwendung von Mutationstests ist im verlinkten Blogbeitrag beschrieben.
Seminarempfehlungen
ORACLE SQL DB-ORA-01
Zum SeminarEINFÜHRUNG IN DIE OBJEKTORIENTIERTE PROGRAMMIERUNG WEBINAR WEB-OO-01
Zum SeminarConsultant bei ORDIX
Kommentare