
Data Science in der Google Cloud – Wie einfach ist der Start und was sollte beachtet werden?
Für mein Masterarbeitsprojekt sollte ein Deep-Learning-Modell zur Generierung von Musik entwickelt werden. Dies ging mit hohen Anforderungen an die benötigte Hardware einher. Heutzutage kann diese Hardware über Cloud Provider wie Google, Amazon oder Microsoft mit ein paar Klicks, ohne Installation von zu Hause, genutzt werden. Auch die benötigte Software wird direkt bereitgestellt. Wie einfach und günstig ist der Start allerdings wirklich und auf was muss geachtet werden?
In diesem Artikel werden genau diese Fragen aus eigener praktischer Erfahrung beantwortet und hilfreiche Tipps für den Start mit Data Science in der Google Cloud an die Hand gegeben.
Aller Anfang ist schwer…
In dem Blogartikel „Data Science Workbench in der Google Cloud“ hat David Hagens bereits gezeigt, wie eine einfache Data Science Workbench aussehen und aufgebaut werden kann. Dafür werden verwaltete JupyterLab-Instanzen auf einer VM in der Google Cloud erstellt. Jede VM kommt mit einer eingebundenen Festplatte auf der kleinere Datensätze, Modellparameter, Statistiken oder Ähnliches gespeichert werden können. Außerdem gibt es einen geteilten Cloud Storage Bucket mit wesentlich größerem Speicherplatz für das Ablegen großer Datenmengen.
Bei Nutzung dieser Workbench kommen dem Data-Scientisten weitere Fragen in den Kopf. Wie bringe ich meine Daten in die Google Cloud? Wie stelle ich meinem Deep-Learning-Modell die Daten zur Verfügung? Woher weiß ich, wie viel RAM ich benötige und wie leistungsstark die GPU sein muss? Wie kann ich sehen, ob die Hardware auch optimal genutzt wird? Welche Kosten kommen auf mich zu?
Wie sehen die Speicherung und der Transfer der Daten aus?
Die Speicherung der großen Datenmengen (in meinem Anwendungsfall Audiodaten) erfolgte in einem Cloud Storage Bucket, auf den von allen JupyterLab-Instanzen zuzugreifen war. Das Hochladen kann über den Webbrowser erfolgen, wie in Abbildung 1 zu sehen ist.
Bei großen Datenmengen ist dies allerdings unhandlich und langsam, da bei dem Upload keine weiteren Parameter eingestellt werden können. Hier bietet sich das Befehlszeilen-Tool „gsutil“ an. Damit kann der Datentransfer zwischen einem externen Speicherort (z.B. lokales Filesystem) und dem Cloud Storage Bucket oder auch innerhalb der GCP über die Befehlszeile der VM gesteuert werden. Mit dem Zusatz „gsutil -m“ kann beispielsweise Multi-Verarbeitung aktiviert werden, wodurch der Upload von vielen Einzeldateien stark beschleunigt wird. Eine vollständige Dokumentation und weitere hilfreiche Parameter finden sie unter: https://cloud.1d5920f4b44b27a802bd77c4f0536f5a-gdprlock/storage/docs/gsutil. Eine weitere Möglichkeit Daten zu übertragen ist der Storage-Transfer-Service, welcher im Projekt nicht genutzt wurde. Die Funktionalität und Tipps, wann dieser besser geeignet ist als gsutil, ist unter folgendem Link zu finden: https://cloud.1d5920f4b44b27a802bd77c4f0536f5a-gdprlock/storage-transfer/docs/overview?hl=de.
Die Preise für die Speicherung der Daten in einem Cloud Storage Bucket belaufen sich je nach ausgewählter Speicherart auf maximal wenige Cents pro GB und Monat. Zugriffe auf die Daten im Bucket werden in drei Kategorien unterteilt: Vorgänge der Klasse A, der Klasse B und kostenlose Vorgänge. Das Hochladen der Daten (insert) fällt unter die etwas teurere Klasse A, Abfragen der Daten (get) unter die günstigere Klasse B und das Löschen der Daten ist kostenlos (delete). Oft wird bei einer Aktion allerdings mehr als ein Vorgang getriggert, wodurch die Kostenaufschlüsselung schwieriger nachzuvollziehen ist. Ein konkretes Beispiel wird später gezeigt. Eine Preisauflistung der Speicherung und der Vorgänge finden Sie hier.
Wie erfolgt die Bereitstellung der Daten zum Deep-Learning-Modell?
Sind die Daten einmal im Cloud Storage Bucket ist die naheliegendste Idee, die Daten direkt vom Bucket in den Hauptspeicher zum Trainieren des Modells zu laden. Dafür kann der Bucket in der VM mit Hilfe von Cloud Storage FUSE gemountet und dann wie ein lokales Filesystem verwendet werden. Die Dokumentation dazu finden Sie hier.
Dieses sehr einfache, schnelle und unkomplizierte Vorgehen bringt einige Nachteile mit sich. Cloud Storage unterstützt keine Gleichzeitigkeit und kein Sperren. Wenn mehrere User Schreibvorgänge auf dieselben Daten im Bucket ausführen, wird der letzte Vorgang ohne Berücksichtigung der vorherigen ausgeführt und es kommt zu einem „lost update“. Die Latenz ist auch erheblich höher, als das Laden von einem lokalen Filesystem. Der aber wohl größte Nachteil, der im Projekt aufgetreten ist, ist die anfangs sehr unübersichtliche Kostenberechnung. Es sind viel höhere Kosten durch das Löschen, Erstellen und Transferieren der Daten entstanden als angenommen. Durch eine beispielhafte Aufschlüsselung der Vorgänge unter https://cloud.1d5920f4b44b27a802bd77c4f0536f5a-gdprlock/storage/docs/gcs-fuse#charges wird dies erst ersichtlich. So werden beispielsweise selbst bei dem kostenlosen delete-Vorgang noch weitere list-Vorgänge der Klasse A ausgeführt, welche Kosten verursachen. Beim Arbeiten mit großen Datensätzen mit vielen Einzeldateien können hier schnell hohe Beträge zusammen kommen.
Des Weiteren wird von den Entwicklern in der Dokumentation vor ungewolltem Verhalten von Cloud Storage FUSE gewarnt.
Eine Alternative für das Bereitstellen der Daten ist der Google Filestore, der hier nicht weiter behandelt, aber bei dem Entwurf einer Workbench berücksichtigt werden sollte.
Wie lege ich die Größe des RAMs und die GPU fest?
Der Computertyp, sowie die verwendete Grafikkarte (wenn verfügbar) kann ohne Probleme nach Erstellung einer JupyterLab-Instanz ohne Datenverlust angepasst werden. Hierfür kann einfach ein anderer Computertyp über das Dropdown-Menü in der Notebookübersicht ausgewählt werden, so wie in Abbildung 2 gezeigt.
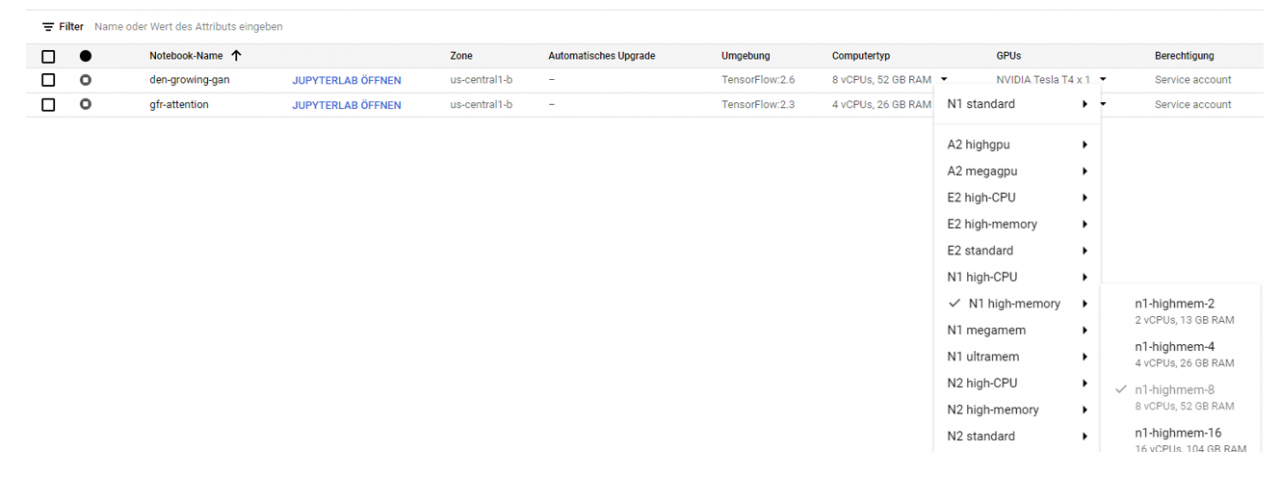
Die Empfehlung ist daher, während der Entwicklungszeit mit geringeren Ressourcen anzufangen und erst für die finale Berechnung die nötige Hardware auszuwählen.
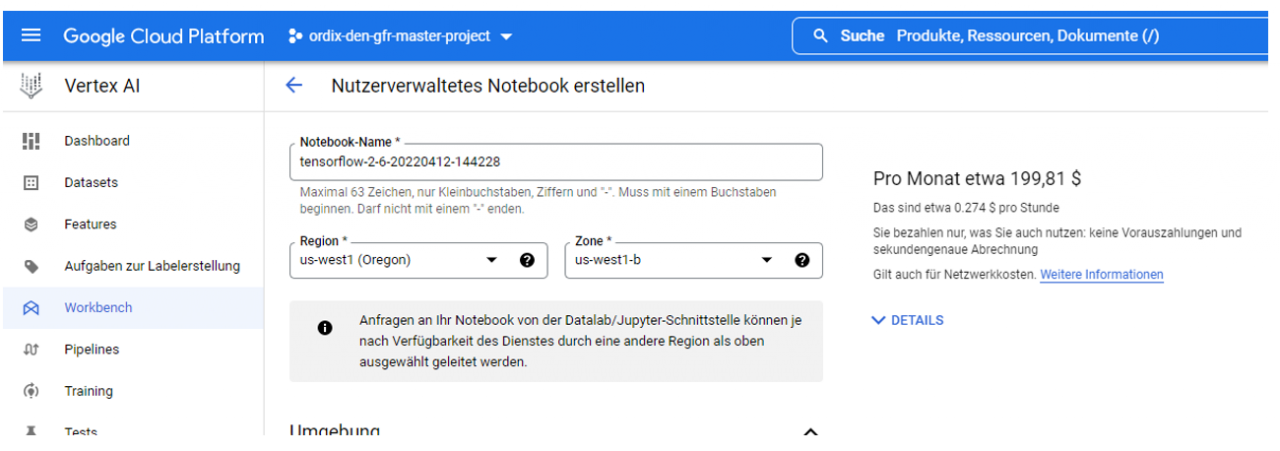
Die Kostenberechnung ist hier sehr übersichtlich. Schon bei der Erstellung der JupyterLab-Instanz wird direkt angezeigt, wie viele Euro die Instanz pro Stunde kostet, wie in Abbildung 3 zu sehen. Hierbei wird nur die Uptime berechnet. Es ist daher wichtig, die Instanz herunterzufahren, wenn sie nicht benötigt wird. Anzumerken ist, dass aufgrund der Ressourcenknappheit nicht immer eine Grafikkarte zur Berechnung zur Verfügung steht. Dies sollte bei der Planung der Projekte berücksichtigt werden.
Wie sehe ich, ob die Auswahl der Hardware richtig war?
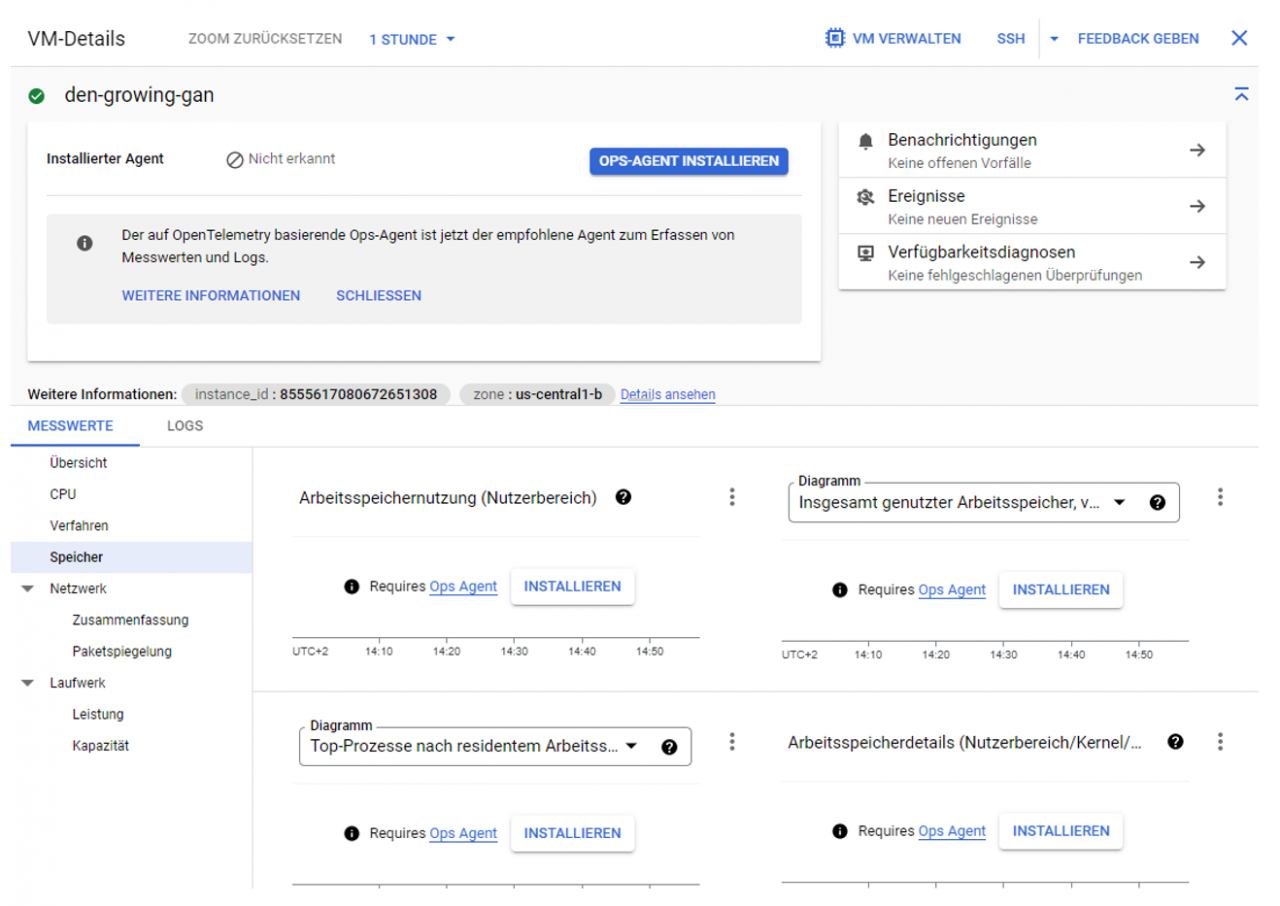
Im Bereich Monitoring unter dem Reiter „VM-Instanzen“ kann ein Dashboard zu den Metriken der JupyterLab-Instanz aufgerufen werden. Kennzahlen, wie z.B. die CPU-Auslastung, stehen standardmäßig zur Verfügung. Für das Monitoring des RAMs muss zusätzlich ein Ops Agent installiert werden. Dies kann sehr einfach über den Knopf „Installieren“ erfolgen, welcher in Abbildung 4 zu sehen ist. Falls dies zu einer Fehlermeldung führt, kann mit Hilfe der kompletten Dokumentation versucht werden den Fehler zu beheben.
Auch für das Überwachen der GPU-Leistung muss erst ein Agent installiert werden. Dies ist etwas komplizierter als das Installieren des RAM-Monitoring-Agenten. Erst muss über einen git-Befehl der Agent auf die VM geladen und anschließend in eine virtuelle Python-Umgebung eingebunden werden. Nun muss noch eingestellt werden, dass dieser Agent beim Start der VM mit gestartet wird. Dieser etwas kompliziertere Prozess ist in folgender Dokumentation gut beschrieben: https://cloud.1d5920f4b44b27a802bd77c4f0536f5a-gdprlock/compute/docs/gpus/monitor-gpus.
Wie gut ist die Entwicklungsumgebung?
Die Entwicklungsumgebung ist eine voll funktionsfähige JupyterLab-Instanz. Google bietet die Möglichkeit direkt Tensorflow oder PyTorch mit den nötigen Konfigurationen für das Verwenden einer GPU auf der Instanz vorzuinstallieren. Weitere Pakete können über pip oder conda sehr einfach nachinstalliert werden.
Wie einfach ist der Start mit Data Science in der Google Cloud nun?
Die Google Cloud ermöglicht es in wenigen Klicks eine funktionsfähige JupyterLab-Instanz mit aktuellen Tensorflow oder PyTorch-Versionen zum Laufen zu bringen. Wird mit lokalen Daten auf der VM gearbeitet, entstehen neben übersichtlichen Kosten für die Uptime der VM keine weiteren Kosten. Werden größere Datenmengen in einem Cloud Storage Bucket gehalten, können diese zur Berechnung direkt in das RAM der VM geladen werden. Dabei können jedoch versteckte Kosten durch unübersichtliche Vorgangsausführungen entstehen. Reicht der Arbeitsspeicher nicht aus oder muss eine leistungsfähigere GPU verwendet werden, kann dies einfach über ein Dropdown-Menü geändert werden, ohne dass weiterer Verwaltungsaufwand hinzukommt. Für das Monitoring des RAM und der GPU muss zusätzlich ein Agent installiert werden. Trotz eventueller Installationsschwierigkeiten bietet Google hier ein gutes Monitoring, welches im Vergleich zu on-premises deutlich einfacher aufzusetzen ist. Das Installieren von Paketen in der Entwicklungsumgebung funktioniert einwandfrei und es steht der volle Funktionsumfang einer JupyterLab-Umgebung zur Verfügung.
Durch die Komplexität der zahlreichen Services und des enormen Umfangs an Dokumentation, der zu jedem Service zur Verfügung steht, kann der Start mit der Google Cloud etwas holprig und unübersichtlich verlaufen. Dennoch bietet die Google Cloud alle Funktionalitäten, die sich ein Data-Scientist wünscht. Durch gute Planung und Kenntnisse der Services kann sehr schnell eine Data Science Workbench aufgebaut und genutzt werden.
Seminarempfehlungen
Cloud Computing Essentials CLOUD-COMP
Zum Seminar
Kommentare