
Räum das mal weg: Die MariaDB Storage Engine S3
Viele Kunden betreiben Datenbanken, die permanent wachsen. So auch in diesem konkreten Fall. Unser Kunde betreibt einen sehr großen MariaDB Server mit mehreren hundert Terabyte an Daten. Ein Großteil der Daten muss aus regulatorischen Gründen verwahrt und im Zugriff bleiben. Änderungen an diesen Daten werden nicht mehr vorgenommen, sondern müssen nur lesbar vorgehalten werden. Eine Idee: Ab in die Cloud damit!
Wasser bis zum Hals!
In diesem konkreten Fall stand unserem Kunden das Wasser tatsächlich schon bis zum Hals. Der Datenbestand ist über mehrere Jahre (eigentlich Jahrzehnte) in den hundert TB-Bereich gewachsen. Beim Aufbau des Systems wurde nie in diesen Größenordnungen gedacht. Aufgrund einer sehr positiven Entwicklung im Geschäftsbereich hat sich das Wachstum in den letzten Jahren / Monaten weiterhin stark beschleunigt, weshalb derzeit an einem neuen Datenmanagement-Konzept für diesen Geschäftsbereich gearbeitet wird. Das Problem: Das neue Konzept, bzw. die neue Infrastruktur ist noch nicht „fertig“. Der Plattenplatz des Datenbank-Servers allerdings schon.
Wenn's mal wieder schnell gehen muss!
Aktuell werden schnelle Lösungen gesucht, die bis zur Einführung der neuen Lösungen buchstäblich das System am Leben halten. Aufgrund des (historischen) Datenmodells mit Tausenden an Schemata und Hunderttausenden an Tabellen scheinen viele übliche Ansätze akut nicht zielführend zu sein. Die Tabellen bzw. das Datenmodell ist für heutige Ansprüche an OLTP-System enorm zurückhaltend. In den Tabellen werden Messwerte bzw. Metriken zu hergestellten Produkten archiviert. Jede Tabelle repräsentiert dabei genau ein Produkt. Transaktionen und Fremdschlüssel werden nur in sehr eingeschränkten Bereichen verwendet, die nicht für den enormen Datenbestand verantwortlich sind.
Natürlich könnte versucht werden, Datenbank-Dateien zu „defragmentieren“, eine Komprimierung auf Datenebene implementieren, Datentypen und Indices optimieren oder gar das Datenmodell komplett umgestalten, um sich etwas mehr Luft zu verschaffen. Auch der Einsatz der altgedienten Engine „Archive“ stand auf der Agenda.
Simpel und gut?
Im Zuge der Diskussionen fiel uns auch die seit MariaDB 10.5.4 verfügbare Storage Engine S3 (steht für Simple Storage Service) ins Auge, die für diesen Zweck wie gemacht zu sein schien.
„The S3 storage engine is read only and allows one to archive MariaDB tables in Amazon S3, or any third-party public or private cloud that implements S3 API (of which there are many), but still have them accessible for reading in MariaDB."
Quelle: https://mariadb.com/kb/en/using-the-s3-storage-engine/
Für mich auf jeden Fall Anlass genug, die Engine einmal kurz zu testen und hier an dieser Stelle vorzustellen.
Die Engine verspricht, Tabellen mit wenig Aufwand in rein lesbarer Form in einem S3-kompatiblen Storage zu „archivieren“. Für mein kleines Test-Szenario greife ich von daher nicht nach den Sternen bzw. in die Cloud, sondern lieber zu Containern. Für mein „Setup“ habe ich mir jeweils ein aktuelles Docker-Image einer MariaDB und von MinIO heruntergeladen. Auf MinIO möchte ich an dieser Stelle nicht weiter eingehen. Für unseren Zweck reicht die Information, dass der MinIO-Container für unsere kleine Teststellung einen S3 API-kompatiblen Storage-Service bereitstellt.
Plug and Play?
In dem von mir genutzten MariaDB Image war das Plugin noch nicht verfügbar. Eine Nachinstallation war jedoch problemlos möglich:
bash> apt install mariadb-plugin-s3
Im Anschluss daran ließ sich das Plugin problemfrei über den Datenbank-Server laden:
MariaDB [(none)]> INSTALL SONAME 'ha_s3';
Parallel habe ich mir über die grafische Oberfläche von MinIO ein Bucket namens „mariadb“ und die notwendigen Berechtigungen für den Zugriff erstellt.
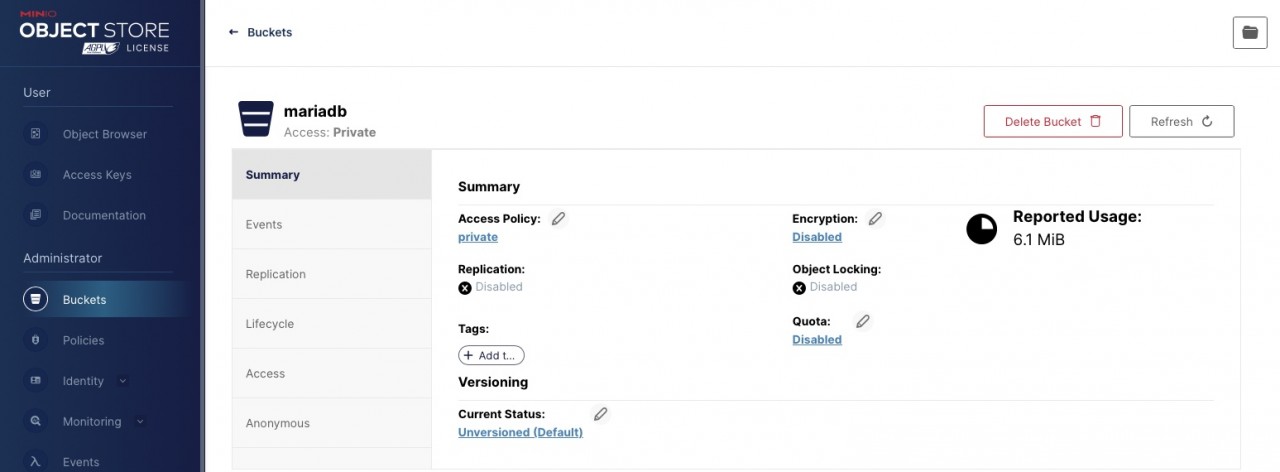
Im Eimer sein?
Um den „Bucket“ in MariaDB verwenden zu können, müssen ein paar Konfigurationen vorgenommen werden. Eine wesentliche Voraussetzung natürlich ist die netzwerkseitige Erreichbarkeit des S3-Storage. In unserem Fall, einer reinen Docker-Laborumgebung, ist dies mit wenigen Kommandos erledigt. In der Praxis, bei einem On-Prem installierten Datenbankserver, ist natürlich zu klären, wie ggf. auch auf einen in der Cloud befindlichen Storage-Service zugegriffen werden kann. Hier gibt es zudem einige sicherheitsrelevante Fragen im Vorfeld zu klären.
Die Konfiguration in unserem Fall sieht wie folgt aus:
cat /etc/mysql/mariadb.conf.d/50-server.cnf … [mariadb] s3=ON s3-bucket=mariadb s3-access-key=85TkJlqHyjOQf1c1 s3-secret-key=S9pyyO***** s3-region=eu-north-1 s3-host-name=172.18.0.3 # IP des MinIO Containers s3-debug=On # Fehler sollen protokolliert werden s3-port=9000 s3-use-http=ON
Nach dem Neustart des DB-Servers ist das Plugin nutzbar:
MariaDB [information_schema]> select plugin_name, plugin_status from information_schema.plugins where plugin_name = 'S3'; +-------------+---------------+ | plugin_name | plugin_status | +-------------+---------------+ | S3 | ACTIVE | +-------------+---------------+ 1 row in set (0.001 sec)
Das kann weg!
Für unseren Test bauen wir uns eine kleine, eigentlich große 😉, Tabelle, die wir dann im Anschluss auf den S3 Storage „archivieren möchten“. Wir erzeugen über eine Prozedur „generate_big_data“ ein paar Datensätze in der Tabelle „bigdata“ und überprüfen das Ergebnis:
DELIMITER //
CREATE PROCEDURE generate_big_data()
BEGIN
DECLARE i INT DEFAULT 0;
DECLARE dataX CHAR(200);
DECLARE dataY CHAR(200);
DROP TABLE IF EXISTS bigdata;
CREATE TABLE bigdata (
id INT NOT NULL AUTO_INCREMENT PRIMARY KEY,
DataX CHAR(200),
DataY CHAR(200)
) ENGINE=InnoDB;
WHILE i < 500000 DO
SET dataX = CONCAT('DataX_', i);
SET dataY = CONCAT('DataY_', i);
INSERT INTO bigdata (DataX, DataY) VALUES (dataX, dataY);
SET i = i + 1;
END WHILE;
END //
DELIMITER ;
MariaDB> select data_length/1024/1022 "data in MB" from information_schema.tables where table_name = 'bigdata';
+--------------+
| data in MB |
+--------------+
| 224.17221135 |
+--------------+
1 row in set (0.011 sec)
Nun verschieben wir die erzeugte Tabelle über einen „alter table“-Befehl in die Engine „S3“.
MariaDB> alter table bigdata engine = 'S3'; Query OK, 500000 rows affected (1.744 sec) Records: 500000 Duplicates: 0 Warnings: 0
Ein Zugriff auf die Daten ist nach wie vor problemlos möglich. Das Hinzufügen oder Löschen von Datensätzen funktioniert jedoch nicht mehr.
MariaDB> select * from bigdata limit 5; +----+---------+---------+ | id | DataX | DataY | +----+---------+---------+ | 1 | DataX_0 | DataY_0 | | 2 | DataX_1 | DataY_1 | | 3 | DataX_2 | DataY_2 | | 4 | DataX_3 | DataY_3 | | 5 | DataX_4 | DataY_4 | +----+---------+---------+ 5 rows in set (0.027 sec) MariaDB> insert into bigdata values (null, 'X', 'Y'); ERROR 1036 (HY000): Table 'bigdata' is read only MariaDB> delete from bigdata where id < 10; ERROR 1036 (HY000): Table 'bigdata' is read only
Strukturelle Veränderungen per "alter table" sind hingegen zulässig:
alter table bigdata add DataZ varchar(100) default "Welcome in S3"; Query OK, 500000 rows affected (1.338 sec) Records: 500000 Duplicates: 0 Warnings: 0 MariaDB [very_big]> alter table bigdata add index I_DataX (DataX); Query OK, 500000 rows affected (2.456 sec)
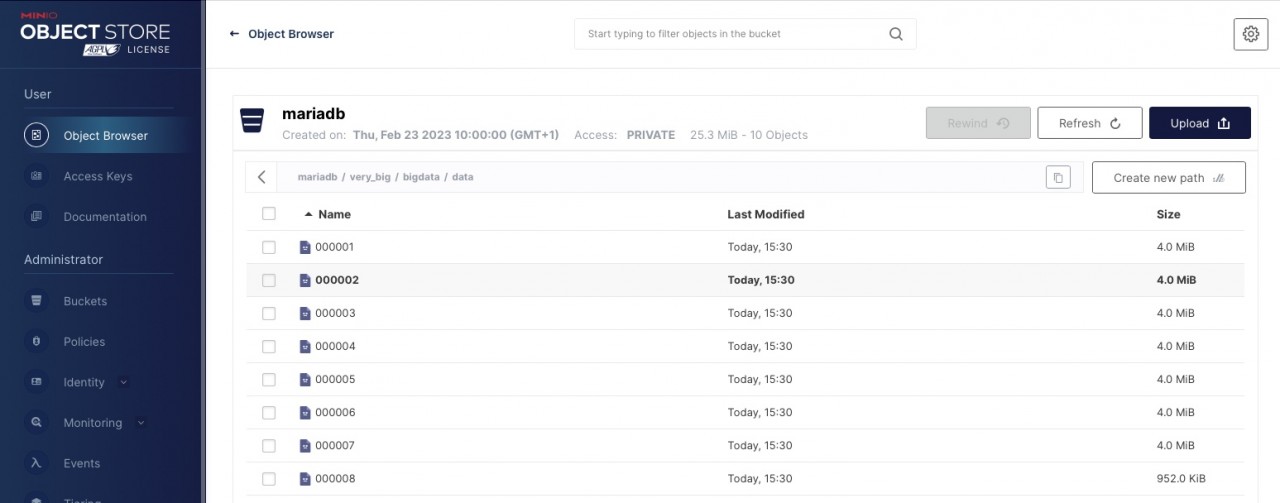
Ein Blick in unser „Bucket“ zeigt ebenfalls, dass die Daten mittlerweile auf unserem S3 Storage angekommen sind. Die Daten wurden dabei in unserem Fall in 4 MB großen Blöcken abgelegt:
Fazit: Alles ist im Eimer!
Die Anbindung eines S3 Storage zur "Archivierung" von Daten ist mit MariaDB problemlos möglich. Neben der rein technischen Funktionalität und um die (!) ging es hier, sind im Detail natürlich grundlegende Fragen im Vorfeld zu klären:
- Kann ich mit den Einschränkungen der Storage Engine leben?
- Wie sieht die Performance aus?
- Kann ich einen entfernten (in der Cloud befindlichen) S3 Storage überhaupt anbinden?
- Welche Auswirkungen hat dies auf mein Backup-Konzept?
- …
Seminarempfehlung
MYSQL ADMINISTRATION DB-MY-01
Zum SeminarPrincipal Consultant bei ORDIX
Kommentare