
Ops, DevOps, DevSecOps und jetzt noch GitOps?! Aber was ist das eigentlich genau?
Wer heutzutage in der Cloud- und Kubernetes-Landschaft Anwendungen bereitstellt, ist bestimmt einmal über diesen Begriff GitOps gestolpert. Es handelt sich dabei um eine Strategie, Deployments und Infrastruktur – ähnlich wie Quellcode – mithilfe eines Versionskontrollsystems wie Git zu verwalten und steuern. Der große Vorteil ist, dass jede Änderung nachvollzogen und existierende Mechanismen wie Pull Request zur Organisation von Anpassungen verwendet werden können.
Was ist GitOps genau?
GitOps knüpft fließend an die existierenden Ideen aus dem Bereich Infrastructure as Code (IaC) an und erweitert diese. Während die Idee bei IaC lediglich darin besteht, Infrastruktur und Konfiguration mithilfe von Quellcode und Konfigurationssprachen wie YAML und JSON darzustellen und dadurch reproduzierbarer zu machen, geht GitOps einen Schritt weiter und verbindet diese Ideen mit der Versionierung und dem Monitoring von Betriebszuständen sowie Continuous-Deployment-Strategien. Dadurch soll sichergestellt werden, dass zu jedem Zeitpunkt ein eindeutiger, vorhersehbarer Zustand der Infrastruktur und der darauf ausgeführten Anwendungen existiert. Dies ist nur möglich, wenn der Soll-Zustand klar formuliert und an einem definierten Ort hinterlegt ist. Dieser Ort wird von dem verwendeten Versionskontrollsystem bereitgestellt. In den allermeisten Fällen ist es ein Git-Repository, daher auch der Name „GitOps", es ist aber auch denkbar, Subversion oder Mercurial zu verwenden. Der Vorteil bei der Verwendung eines solchen Tools ist, dass nicht nur der aktuelle Soll-Zustand, sondern auch alle vorherigen Versionen gespeichert sind und bei Bedarf abgerufen werden können. Wenn etwa die neuste Version der eingespielten Software einen kritischen Fehler hat, kann mithilfe der Versionsverwaltung wieder auf einen alten, fehlerfreien Stand gewechselt werden. Ein weiterer großer Vorteil der Commit-History, besteht darin, dass sie ein Audit-Log aller Vorgänge darstellt. Dies kann in einigen Anwendungsgebieten zum Sicherheitskonzept gehören und verpflichtend sein.
Der Weg zum GitOps-Pattern
Das GitOps-Pattern wurde von Alexis Richardson (CEO - Weaveworks) 2017 erstmals beschrieben. Seitdem hat sich eine lebendige Softwarelandschaft mit einer aktiven Community rund um GitOps-Werkzeuge entwickelt. Um diese Entwicklung besser zu verstehen und das Konzept hinter GitOps greifbarer zu machen, lohnt es sich, ein wenig in die Vergangenheit zu schauen und zu betrachten, aus welchen Ideen diese Herangehensweise entstanden ist.
Die Idee hinter GitOps ist nichts Neues. Bereits vor der Prägung des Wortes „GitOps" wurden die Vorgehensweisen in der Praxis von Administratoren und Entwicklungsteams eingesetzt. Häufig jedoch nur in Teilen und mit vielen benutzerdefinierten Skripten und Anwendungen.
Das nachfolgende Bild zeigt einen möglichen Deployment-Ablauf, wie er in vielen Unternehmen umgesetzt wird. Zum Einsatz kommen Git, zur Versionierung des Quellcodes, sowie eine CI-Pipeline zum automatischen Linten, Testen, und Bauen der Anwendung. Die Veröffentlichung findet ebenfalls automatisch, mithilfe einer CD-Pipeline, statt. Sie nimmt die gebaute Anwendung und kopiert diese auf das Zielsystem, wo sie anschließend ausgeführt wird.
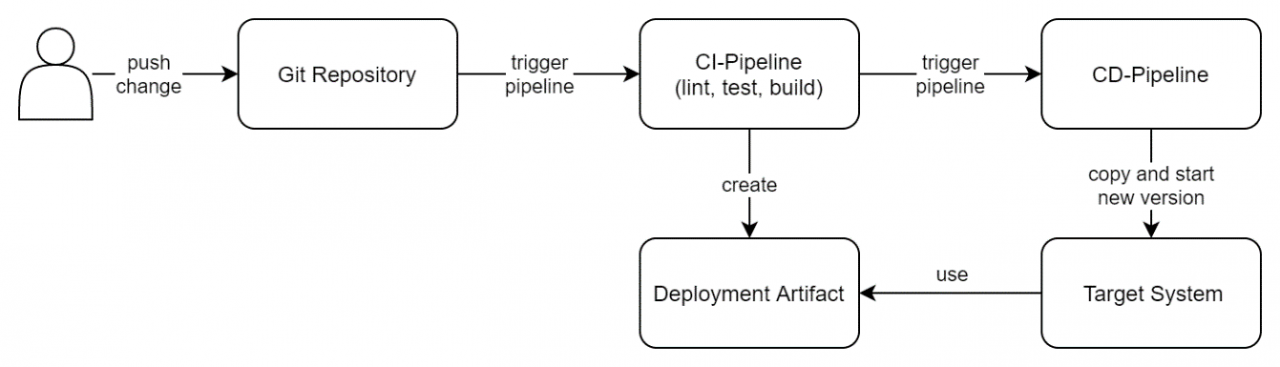
Auf den ersten Blick ist nichts an diesem Vorgehen falsch. Was gibt es aber dennoch auszusetzen?
Die Anwendung ist an das operationale Environment gebunden. Dieses muss von einem Administrator manuell bereitgestellt und angepasst werden, sollte eine Änderung notwendig sein. Dies führt zu personellen Abhängigkeiten und somit unweigerlich zu Verzögerungen im Deployment-Ablauf.
Eine Möglichkeit diese Abhängigkeiten abzuschaffen, ist es, jedem Teammitglied Zugriff auf das Zielsystem zu geben. Somit kann ein Entwickler/Administrator selbstständig notwendige Änderungen vornehmen und ist auf niemanden angewiesen. Was im ersten Moment vielleicht flexibel klingt, hat jedoch mehrere Nachteile:
- Es steigert die Wahrscheinlichkeit, dass das System (egal ob wissentlich oder nicht) fehlkonfiguriert wird
- Es steigert die Angriffsfläche des Systems, gegenüber externen Parteien, da mehrere Benutzer existieren, die mit entsprechenden Rechten kritische Änderungen auszuführen können
Besser ist es, den direkten Zugriff für alle Entwickler und Administratoren zu unterbinden und stattdessen mithilfe von Infrastructure as Code und einer erweiterten CD-Pipeline die Infrastruktur indirekt zu verwalten.
Ein weiteres Problem ist, dass der Zustand der Anwendung nach dem Deployment-Prozess nicht mehr oder nur manuell überprüft wird. Sollte die Anwendung abstürzen oder fehlkonfiguriert werden, existiert keine Instanz, die das aktiv überwacht und korrigiert. Der Fehler wird erst durch manuelles Eingreifen wieder behoben.
Viel schlimmer noch, wenn Änderungen auf dem System durchgeführt, jedoch nicht dokumentiert wurden, kann es schwer werden den alten Zustand nach einem Absturz wiederherzustellen.
Geht das besser? Ja, wenn eine klare und an einem eindeutigen Ort liegende Definition des Soll-Zustands existiert, kann das Zielsystem mithilfe von Skripten oder Anwendungen diesen automatisch sicherstellen.
Der folgende Abschnitt beschäftigt sich auf theoretischer Ebene mit möglichen GitOps-Architekturmodellen zur Umsetzung der genannten Verbesserungen.
GitOps-Architektur
In diesem Abschnitt werden drei Ansätze beschrieben, um eine GitOps-Architektur umzusetzen. Es wird dabei nur das theoretische Konzept zur Umsetzung dieser Ansätze beschrieben, daher sind die Begriffe absichtlich sehr abstrakt gehalten. So kann unter einem Deployment Artefakt eine Java-JAR-Datei, eine EXE-Datei oder ein Container Image gemeint sein. GitOps gibt keine Software vor, vielmehr konzentriert es sich auf die Struktur und Umsetzung der Deployment-Architektur. Dennoch sollte angemerkt werden, dass GitOps insbesondere in Cloud-Landschaften sowie Kubernetes eingesetzt wird, da diese Umgebungen durch ihre Schnittstellen eine optimale Möglichkeit zur Automatisierung und Überwachung bieten.
push-basierte Deployments mit einem Repository
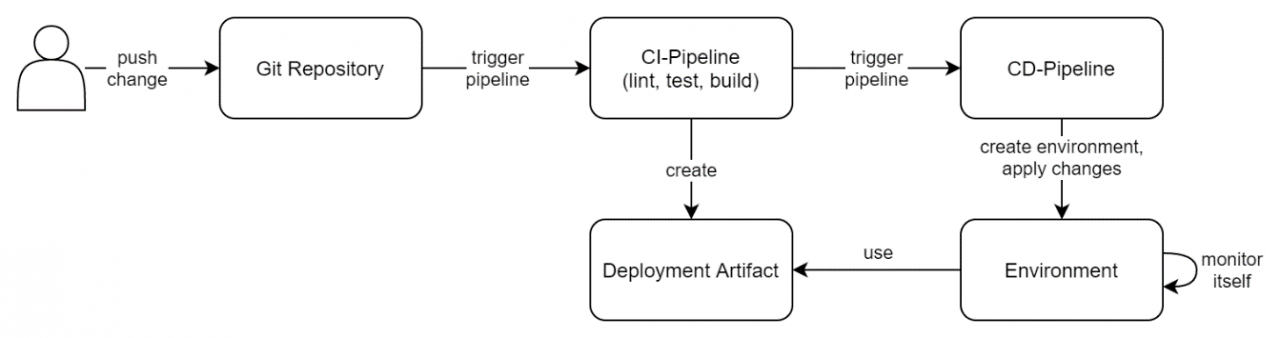
Manuelle Eingriffe auf dem Server Verhindern – Zwei Szenarien:
Um dieses Beispiel etwas greifbarer zu machen, können folgende zwei Szenarien verglichen werden.
- Auf einem System ist ein Webserver (z.B. NGINX, Apache HTTP Server) installiert, dieser wurde durch einen zuständigen Administrator bereits konfiguriert und wird von ihm verwaltet. Nachdem ein Entwickler eine Änderung an einer Webseite vorgenommen und ins Repository übernommen hat, werden entsprechende CI- und CD-Pipelines durchlaufen, welche die Anwendung bauen und anschließend automatisiert bereitstellen. Letztere kopiert die fertig gebaute Webseite auf den Server und legt sie in einem Ordner ab, der vom Administrator vordefiniert und vom Webserver verwendet wird. Der Webserver stellt nun die neue Version der Anwendung bereit. Sollte eine Anpassung am Webserver notwendig sein (z.B. Erhöhung des benötigten Arbeitsspeichers), muss dies manuell vom Systemadministrator durchgeführt werden.
- Nachdem ein Entwickler eine Änderung an einer Anwendung vorgenommen hat, wird die vorhandene CI- und CD-Pipeline durchlaufen. Die CD-Pipeline kopiert jedoch keine Anwendung, sondern nutzt Automatisierungs- und Orchestrierungswerkzeuge (z.B. Ansible, Puppet, Terraform), um das Zielsystem so zu konfigurieren, dass die Anwendung ohne manuellen Eingriff lauffähig ist. Die Konfiguration des Systems wird mithilfe von Template-Dateien, welche ebenfalls im Repository liegen, angegeben. So können benötigte Einstellungen und Software automatisiert installiert werden, bevor die eigentliche Anwendung auf das Zielsystem kopiert und gestartet wird. Wenn Änderungen an dem System notwendig sind, werden diese in den Template-Dateien angegeben, woraufhin die
Pipelines ausgelöst werden und diese ausführen.
push-basiertes Deployment: Manchmal Unabdingbar
Aus den Beispielen wird klar, wie der manuelle Eingriff auf dem Server durch die Verwendung der überarbeiteten CD-Pipeline verhindert wird. Dadurch wird das Sicherheitsrisiko aus dem ersten Beispiel, bei dem jeder Entwickler das Recht hatte auf das System zuzugreifen, behoben. Der Nachteil ist jedoch, dass diese Rechte an die CD-Pipeline „übergeben" wurden. Da Pipelines häufig im Kontext des Repository behandelt werden (z.B. in GitLab/GitHub sind es spezielle Dateien, die zusätzlich im Repository liegen), können Entwickler/Administratoren dieselben Aktionen indirekt mithilfe der Pipeline ausführen. Um dies zu verhindern, müsste es untersagt sein, die Pipeline-Datei zu verändern, was häufig nicht möglich ist. Ein weiterer Nachteil ist, dass das System zwar automatisch installiert und konfiguriert, jedoch nicht überwacht wird. Sollte sich die Umgebung durch manuelle Einflüsse oder externe Umstände verändern, kann das System diese Umstände nicht automatisch erkennen und entsprechend reagieren. Daher muss zusätzlich, während der Installation der notwendigen Softwarepakete durch die Automatisierungstools, ebenfalls Software zur Überwachung (Monitoring) des eigentlichen Systems aufgespielt werden.
Trotz der Nachteile, gibt es Fälle in denen ein push-basiertes Deployment unabdingbar ist. Wenn etwa die notwendige Infrastruktur zum hosten der Anwendung erst durch die CD-Pipeline hochgefahren und aufgebaut wird, kann diese logischerweise keine Software installiert haben, die das System vorkonfigurieren könnte.
Im Abschnitt „Pull-basierte Deployments mit zwei Repositories" wird ein zweites Repository hinzugefügt, welches zum Verwalten von Änderungen an der Infrastruktur zuständig ist. Dieses Konzept kann analog für ein push-basiertes Deployment verwendet werden.
pull-basierte Deployments mit einem Repository
Im Gegensatz zu push-basierten Deployments besitzen pull-basierte Deployments keine CD-Pipeline. Stattdessen wird ein sogenannter „GitOps-Operator" eingesetzt. Dabei handelt es sich um eine Software, welche periodisch überprüft, ob das Ziel-Repository neue Änderungen hat und diese gegebenenfalls anwendet (pull).
GitOps ist durch das Wachstum von Cloud-Native-Technologien und Kubernetes entstanden. Entsprechend fokussieren sich GitOps-Operatoren in den meisten Fällen auf das Bereitstellen von Anwendungen für solche Umgebungen. So wird unter anderem der Ist-Zustand des Kubernetes-Clusters überwacht und mit dem Soll-Zustand aus dem Repository verglichen. Bei Abweichungen versucht der Operator mithilfe von erneuten Deployments, Neuinstallationen und Konfigurationen wieder den Soll-Zustand zu erreichen.
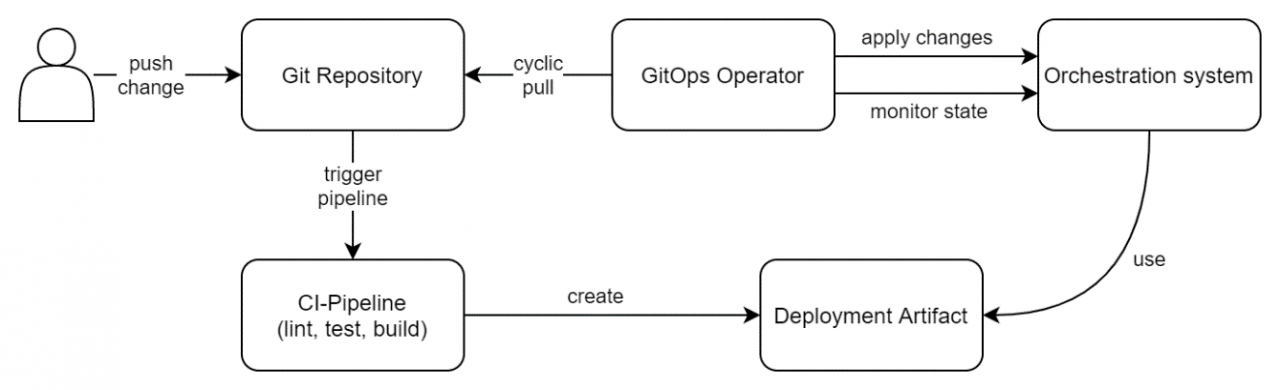
Abbildung 3 beschreibt einen möglichen Aufbau, bei dem mithilfe eines Repository und eines GitOps-Operators automatische Deployments umgesetzt werden. Der GitOps-Operator überprüft periodisch (z.B. alle 3 Minuten), ob dem Git-Repository neue Änderungen hinzugefügt wurden. Ist dies der Fall, werden diese auf dem Zielsystem angewandt. Gleichzeitig überwacht der Operator das zu orchestrierende System, um sicherzugehen, dass der Ist-Zustand dem Soll-Zustand aus dem Repository gleicht. Sollte der Zustand abweichen, werden die entsprechenden fehlerhaften Ressourcen konfiguriert und neu gestartet. Wenn beispielsweise nach einem „git push" die Template-Dateien, welche die Anwendung beschreiben, aktualisiert und ein neues Container-Image der Anwendung durch die CI-Pipeline gebaut wurde, wird der GitOps-Operator diese auf dem Zielsystem (z.B. Kubernetes) aktualisieren. Im Falle von Kubernetes wird das neue Container-Image durch Kubernetes aktualisiert (siehe Abbildung 3 „use").
pull-basierte Deployments mit zwei Repositories
(Dev + Infrastructure)
Der letzte Ansatz, der in diesem Blogpost betrachtet wird, kann als Erweiterung des Abschnitts pull-basierten Deployments mit einem Repository angesehen werden. Es gibt einige Gründe den Anwendungscode von den Infrastruktur-Templates zu trennen. Wenn beispielsweise nur eine Änderung an der Infrastruktur getätigt werden muss (z.B. Erhöhung der Replika), ist es unnötig die CI-Pipeline zum Linten, Testen und Bauen der Anwendung, auszulösen. Durch das Hinzufügen eines zusätzlichen Infrastruktur-Repository kann der Quellcode der Anwendung von der benötigten unterliegenden Infrastruktur getrennt und somit separat verwaltet werden. Dies erlaubt es auch, den Zugriff auf Ressourcen feingranularer einzustellen. Beispielsweise können nur ausgewählte Entwickler/Administratoren das Recht erhalten, Änderungen im Infrastruktur-Repository vorzunehmen.
Ein weiterer Grund kann aus dem technischen Problem entstehen, dass Templates nach einer Änderung im Quellcode automatisch durch eine Pipeline aktualisiert werden sollen (z.B. Erhöhung der Version im Template). Wenn sowohl Quellcode als auch Templates für die Infrastruktur im selben Repository liegen, kann ein „git commit" der durch die Pipeline ausgeführt wurde, dazu führen, dass sie sich selbst erneut auslöst, wodurch eine Endlosschleife gestartet wird. Dies kann mit einem zweiten Repository verhindert werden, indem die CI-Pipeline des Dev-Repository einen Commit auf dem Infrastruktur-Repository ausführt. Dieses Vorgehen ist in Abbildung 4 grafisch dargestellt.
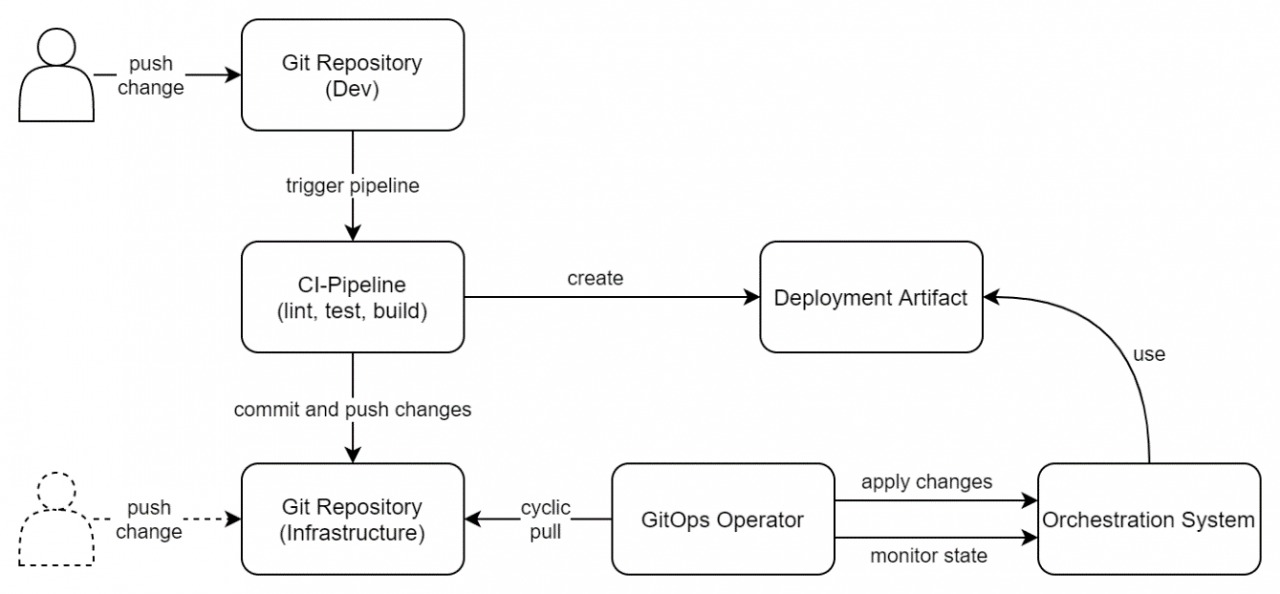
Um den Weg einer Quellcodeänderung bis zur Bereitstellung genauer zu verstehen, wird nachfolgend der Prozess aus Abbildung 4 noch einmal genauer beschrieben:
Nachdem ein Entwickler eine neue Änderung in das Git-Repository hinzugefügt hat, wird automatisch die CI-Pipeline gestartet. Diese überprüft die getätigten Änderungen und erstellt anschließend ein einsatzbereites Deployment Artefakt. Außerdem führt sie als letzten Schritt eine Anpassung (z.B. Angleichen der Container-Image-Version an das neu gebaute Image der CI-Pipeline), der Deployment-Templates im Infrastruktur-Repository, aus. Die Pipeline hat dazu die Rechte, vordefinierte Anpassungen im Repository mithilfe von „git commit" und „git push" Befehlen vorzunehmen. Nun wird der GitOps-Operator, der auf Änderungen im Infrastruktur-Repository hört, beim nächsten, periodischen pull die getätigten Änderungen der CI-Pipeline in der Deployment-Umgebung anwenden.
Das Dev-Repository sowie der Anwendungsquellcode haben somit keinen direkten Bezug mehr zum GitOps-Operator und dem Deployment-Prozess. Sollten größere Änderungen an der Infrastruktur notwendig sein, können diese im Infrastruktur-Repository, gesondert vom eigentlichen Anwendungscode, vorgenommen werden.
Fazit & Ausblick
In diesem Blogartikel wurde das Konzept hinter dem GitOps-Pattern erklärt und mit theoretischen Architekturmodellen Beispiele für die Umsetzung gegeben. GitOps ist eine Herangehensweise, Anwendungen und notwendige Infrastruktur automatisiert bereitzustellen und zu verwalten und kann als Erweiterung zum Infrastructure as Code-Konzept gesehen werden. Grundsätzlich stellt das Pattern nur eine Deployment-Struktur dar und ist daher plattformunabhängig. In der Praxis wird das Konzept jedoch meistens im Kontext von Cloud-Technologien und Kubernetes eingesetzt. GitOps-Operatoren wie ArgoCD und Flux sind beispielsweise für den Betrieb im Kubernetes Cluster ausgelegt. Um also eine praxistaugliche Deployment-Architektur nach dem GitOps-Pattern zu modellieren, darf die eingesetzte Ziellandschaft nicht außer Acht gelassen werden. Beispielsweise ist die Umsetzung von GitOps ohne die Verwendung von Kubernetes in der Theorie problemlos möglich. In der Praxis jedoch sind die bekanntesten und erfolgreichsten GitOps-Operatoren begrenzt auf das genannte Orchestrierungs-Tool.
Die in diesem Artikel beschriebenen Modelle können als Grundlage und Leitfaden zur Ausarbeitung einer eigenen Deployment-Strategie nach dem GitOps-Pattern verwendet werden. Dabei sollten die Vor- und Nachteile der einzelnen Vorgehensweisen beachtet werden. Beispielsweise ist eine pull-basierte Deployment-Strategie einer push-basierten, wenn möglich, vorzuziehen, da diese eine höhere Sicherheit bietet, sowie die Möglichkeit mitbringt das Zielsystem mithilfe des GitOps-Operators direkt zu überwachen. Auch ist ein Aufbau mit zwei Repositories in den meisten Fällen besser, da viele Struktur- und Berechtigungsprobleme vermieden werden (seperation of concerns).
Zum Abschuss sollten noch die Themen erwähnt werden, die nicht in diesen Blogartikel gepasst haben, aber dennoch für das Thema „GitOps" relevant sind. Da dieser Artikel sich mit dem grundlegenden Konzept hinter GitOps beschäftigt hat, wurden konkrete Beispiele zur Umsetzung des beschriebenen Vorgehens absichtlich vernachlässigt. Dazu sollen weitere Blogartikel folgen. So sollen die GitOps-Operatoren ArgoCD und Flux jeweils einen eigenen Artikel erhalten. Auch soll das Thema „GitOps in einer Microservice Architektur" gesondert betrachtet werden, da dort optimierte Modelle verwendet werden können. Themen wie Branch-Verwaltung im Kontext von GitOps, sowie unterschiedliche Deployment-Umgebungen (dev, test, prod) wurden ebenfalls nicht behandelt, sind in der Praxis jedoch sehr relevant.
Weiterbildung gesucht?
Sie haben Interesse an einer Weiterbildung oder Fragen zum Thema? Sprechen Sie uns an oder besuchen Sie einen unserer Kurse aus unserem Seminarshop:
Zu unseren Seminaren
Junior Consultant bei ORDIX
Kommentare