
Harnessing the power of Kafka
Is there more to Kafka than the usual producer and consumer APIs?
Kafka, the event streaming platform, is usually known for its producer and consumer APIs allowing applications to write, store and retrieve events from the platform in a decoupled way. In the age of ubiquity of compute resource and huge volume of data being generated, it offers the possibility to store in very efficient, robust, and highly available way, the huge volume of data, acting as a broker for all involved parties and applications.
How can one build (stream processing) applications with near-real time to real-time ability? What alternatives are available and provided by Kafka to support and leverage the design and implementation of applications with various requirements, ranging from simple stream processing to real-time processing?
This article is part of a series aiming to provide a good understanding of Kafka technologies and their use to solve different challenges.
Introduction
Applications use the producer API to publish and store streams of events on the platform, and the consumer API to consume all stored events. Kafka is more than its producer and consumer API. Kafka Streams and ksqlDB are two additional Kafka APIs useful to build easily custom applications to process streams of events to gain insight in data and generate new streams of data.
This article presents Kafka Streams.
Kafka Streams
Streams also known as Kafka Streams API is a stream processing library built for Apache Kafka. It is part of the official Kafka project. It allows real-time processing of data, enabling the design and implementation of stateful and stateless applications either with the use of stream processing operations like filters, joins, maps, aggregations or through the definition of the underlying processing topology. Furthermore, it is described by Kafka as the "easiest way to write mission-critical, real-time applications and microservices".
The increase of the demand for near-real time to real-time processing capabilities of streaming data has driven the development of the Kafka Streams API. Before Kafka Streams, batch processing or batch-oriented approaches were used by stream processing frameworks to build applications to consume data from Kafka topics and process the collected data in chunks (batches) and then store the output for later use.
Why an additional stream processing library?
Difference in processing model
Before the release of the first versions of Kafka Streams in Kafka 0.10.0 in 2016 and during its early days, there were mainly 2 options for building Kafka based stream processing applications:
- the use of the Consumer and Producer APIs
- or the use of another stream processing framework like Apache Spark (Spark Streaming) and Apache Flink.
Stream processing applications built solely on the Consumer and Producer APIs tend to become very quick complex with a lot of code to write when nontrivial operations like records aggregations, joins and event grouping are necessary. Additional effort is also required to provide robustness and availability, allowing the application to be fault-tolerant and recoverable. Application developers must implement availability and recoverability strategies.
When considering the second alternative to make use of stream processing frameworks like Apache Spark or Apache Flink, it is worth noticing that these frameworks use a batch-oriented approach to consume, process and write new data from collected data in different Kafka topics. Even when these frameworks differentiate between a batch processing and stream processing mode (in their functionalities) for the development of applications, the batching strategy is still used in different form to achieve the seemingly defined "streaming processing mode": the stream processing functionality of these framework make use of micro-batching processing.
Micro-batching is a variant of traditional batch processing, allowing the collection of data in small frequently occurring group of data (batches) in contrast to a batch processing acting on a larger group of data. In this form, micro batching allows executors to execute a certain logic on data collected after a small given duration of time. This approach suffers drawbacks in use cases requiring lower latency and real-time ability, to respond to business relevant questions.
Kafka Streams on the other hand uses a different approach to stream processing known as "event-at-a-time" processing, where events are processed immediately, one at a time, as they appear. This approach provides a lower latency compared to the prevailing micro-batching approach, making it easy to consume and process streams of events as they move through data pipelines. It is worth noticing that contrary to existing stream processing frameworks, Kafka Streams only supports stream processing. This is known as kappa architecture. The Lambda architecture refers to frameworks supporting both batch and stream processing.
Difference in deployment model
Other stream processing frameworks like Apache Spark or Apache Flink require the use of additional dedicated platform(s) (processing cluster) for submitting and running the different stream processing programs. This introduces more complexity and overhead.
Kafka Streams being a Java library simplifies the development and execution of stream processing applications, removing all costs attached to use and maintenance of a dedicated cluster. Getting started becomes much easier. To build a stream processing application, the Kafka Streams dependency is simply required to be added to a program. For Java, adding the Kafka Streams dependency in the maven or gradle build file is sufficient.
Kafka Streams was designed with the goal to simplify stream processing, providing a framework/utility with simple application model which fulfills the most important goals for data systems which are scalability, reliability, and maintainability.
Is it all? What else does Kafka Streams provide?
Built on top of Kafka client libraries, the Kafka Streams greatly simplifies the stream processing of topics. "Kafka Streams is a client library for processing and analyzing data stored in Kafka." (https://kafka.apache.org/10/documentation/streams/core-concepts.html)
It is important to define some keywords which will be used in the following points. A stream is an abstraction provided by Kafka Streams, representing an unbounded, continuous updating data set (https://kafka.apache.org/10/documentation/streams/core-concepts.html). Kafka Streams being a client library for processing and analyzing data stored in Kafka, a stream processing application is a program that makes use of the Kafka Streams API.
A simplified flow representation
Kafka Streams follows a programming paradigm called dataflow programming, which models a program as a directed graph, a series of steps made of inputs, outputs, and processing stages with the data flowing between the various operations.
The processing logic in a Kafka Streams application structured as a directed acyclic graph (DAG) represents how data flows through a set of various steps. These steps also called processors form a topology.
There are 3 types of processors in Kafka Streams:
- Source processors: Sources represent the origin of data used as input of Kafka Streams applications. Sources are where information flows into the Kafka Streams application, for example a Kafka topic. Data read from the input sources are sent into one or more stream processors
- Stream processors: Stream processors apply transformation logic on the input stream data. Stream processors make use of built operators provided by the Kafka Streams library.
- Sink processors: Sinks represent the destination of enriched, transformed (processed) stream data (records). Processed records can be written back to Kafka or sent to an external system via Kafka Connect.
A stream processor topology is thus a collection of processors concretely defined as an acyclic graph of sources, processors, and sinks processors. The picture 1 gives an example of a topology and the different processors building this topology.
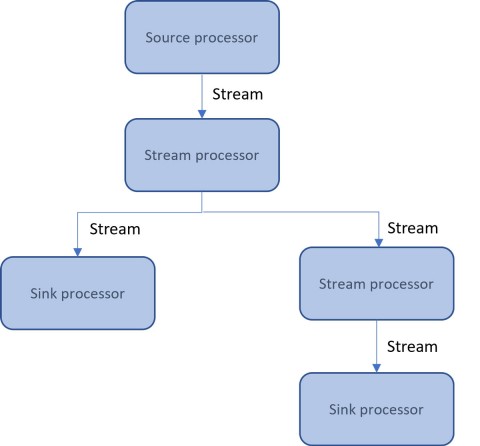
A simple topology can be considered as a triple input (consume), process and write. Kafka Streams divides a topology in smaller topologies, sub-topologies, to parallelize the processing work. This is useful when, for example, an application consumes and combines records from various topics for processing. In the picture 1, the right-hand branch having a stream processor and a sink processor after the main stream processor represents a sub-topology.
Kafka Streams use a depth-first processing strategy while processing the topology. Each record consumed from Kafka goes through the whole topology (each processor in the topology) before another record is processed. This means that only one record goes through the topology at once. In case of a simple topology, each record consumed will be processed and possibly written to another topic or external sink before consuming the next record. In case of multiple sub-topologies, the depth-first strategy is applied to independent sub-topologies, which will be processed independently of each other. The single-event rule does not apply to the entire topology, but to each sub-topology.
Simple abstraction for stream data: Streams and tables
Kafka Streams use 2 different ways to model data in topologies: a stream (also called a record stream) or a table (also known as a changelog stream).
A stream represents an unbounded, continuous updating data set. A stream records the history of what has happened in the world as a sequence of immutable records. A stream is "an ordered, replayable, and fault-tolerant sequence of immutable data records" according to the official Kafka Streams specification, where a record (also known as log) on the other hand is simplified a key-value Pair.
A table contrary to the stream represents the state of the world at a given point in time, usually now. A table can be considered as a continually updating view of a stream. In few words, streams record history and tables represent state (https://www.confluent.io/blog/kafka-streams-tables-part-1-event-streaming/); A stream provides immutable data and support only insertion of new immutable records. A table on the other hand provides mutable data, since new event records can be inserted and existing rows updated and if necessary deleted, only the latest representation of each key being kept.

The picture depicts the difference between stream and table representations and the possibility of conversion between both. At a time t4 when Offset 3 is received, {action: logout} is the state keeping the latest value for the key Thomas, thus representing the last action done by User Thomas. This value will be stored in the table as the current state for records with key Thomas, overwriting the formal value {action: login}, where {action: logout} is only added to the stream. This interchangeably conversion between tables and streams is called stream-table duality.
As we can see in this example, it is important when choosing between tables and streams, to consider whether only the latest state/representation of a given key is necessary, or the entire history of records.
A stream can be turned into a table using aggregations operations like count, sum and a table to stream by capturing all changes made to the table (insert, update, delete).
If records written to Kafka are immutable, how is it possible to model data as updates, using a table representation of a Kafka topic? The answer to this question in the next article.
Stateless and stateful processing
The Kafka Streams library combines the various data models (Streams and tables) with multiple operators to support the implementation of both stateless and stateful stream processing applications.
In a stateless processing, no memory of previous records is necessary. In this form of stream processing, a record is consumed, processed, and forgotten. No memory of previous computational logic is required and necessary in the processing. In a stateful processing, on the other hand, information about previous consumed and processed records of the topology is necessary. This is usually the case in aggregations, joins or windowing use cases where the result of intermediate computation in a processor is necessary to process further nodes/processors in the topology.
Kafka Streams provides various operators for working with data in a stateless or stateful way. "Stateless operators" are thus operators that only need to look at the current record to perform an action. Some operators like filter (filtering of records), map (adding and/or removing fields), branch (branching streams), merge (merging streams) are considered stateless. Other operators like count, sum, join are considered "stateful operators" since they require knowledge of previous events.
An application is considered stateless if it only requires stateless operators. Whenever one or more stateful operators is/are used, the application is then considered stateful.
Rich time-based operations
The notion of time and how it is modeled is a critical aspect in stream processing frameworks. Kafka Streams uses 3 different notions of time: event time, processing time and ingestion time. These different conceptions will impact the execution and result of operations such as windowing, which are based on time boundaries.
The wall-clock time here is the physical time at a given environment, producer, or broker.
Event-time is the time when a data record symbolizing an event was originally created (at the source). It is a timestamp set by a producer (application sending data to Kafka) and is usually the current wall-clock time of the producer’s environment when the event is created.
Ingestion time is according to the official specification the "point in time when an event or data record is stored in a topic partition by a Kafka broker". The ingestion time always occurs after the event time. It is a timestamp set by the broker; thus represents the timestamp of the current wall-clock time of the broker’s environment.
Processing time is "the point in time when the event or data record happens to be processed by the stream processing application". It is the time when the record is being consumed. This occurs after the event time and ingestion time.
Kafka provides two configuration options to set when records are ingested: createTime and LogAppendTime, one at the broker level and the other one at the topic level. The topic-level config takes precedence over the broker-level config. A configuration of LogAppendTime at the topic level will override the value of the timestamp set by the producer when the record is appended to a topic. The CreateTime option will rather enforce the event-time semantic, by making sure to keep the original producer's timestamp in the record.
Kafka Streams leverages windowing, a method for grouping records with the same key for the purpose of aggregation and joining. Windowing operations are available in the Kafka Streams DSL. The different records subgroups also called windows are tracked per record key. Windows are used to group records with some close temporal proximity, depending on the time semantic used to define the temporal proximity. In case of event-time semantics, the temporal proximity can be interpreted as "records that occurred around the same time," whereas with processing-time semantics, it can be interpreted as "records that were processed around the same time.". There are four different types of windows in Kafka Streams.
- Tumbling windows: Tumbling windows are fixed-sized windows that never overlap. They are defined using the window size and have predictable ranges since they are aligned with the epoch.
- Hopping windows: Hopping windows are fixed-size windows that may overlap. They are defined using the window's size and the advance interval, to specify how much forward the window can move. When advance interval <= window size, widows overlap, causing some records to appear in multiple windows. Hopping windows have predictable time ranges since they are aligned with the epoch.
- Session windows: Session windows are variable-sized windows enclosing periods of activity followed by gaps of inactivity. They are defined using the inactivity gap. If the inactivity gap is "5 s", then each record that has a timestamp within five seconds of the previous record with the same key will be merged into the same window. Otherwise, if the timestamp of a new record is greater than the inactivity gap (in this case, five seconds), then a new window will be created.
- Sliding windows: Sliding windows use windows that are aligned to the record timestamps (as opposed to the epoch). Sliding join windows are thus fixed-sized windows that are used for joins and created using the JoinWindows class. Two records fall within the same window if the difference between their timestamps is less than or equal to the window size. Lower and upper window boundaries are inclusive.
- Since Kafka Streams 2.7.0 sliding windows can be used for aggregations. Records will fall within the same window if the difference between their timestamps is within the specified window size and grace period. Like sliding join windows, the lower and upper window boundaries are both inclusive.
A grace period can be defined for windows to specify the maximum period to wait to declare data records out-of-order for a window. Records occurring after the grace period of a window will be discarded and not processed in the window.
In case of time-based stream processing operations, Kafka Streams chooses the event to process based on its timestamp, making use of TimestampExtractor interface. The TimestampExtractor interface provides the basic behavior for associating a given record with a timestamp. The default behavior is to use the event timestamp (either set by the producing application or by the Kafka broker). A custom TimestampExtractor can be used in case the timestamp is embedded as a payload in the record.
Simplified and flexible programming models
The Kafka Streams library provides 2 ways to define the stream processing topology: the Kafka Stream DSL and the Processor API.
The Stream DSL is considered a high-level API compared to the low-level Processor API. The high-level Stream DSL is built on the Processor API internally and uses a declarative, functional programming style to build stream processing applications. It provides some high-level abstractions for streams and tables in the form of KStream, KTable, and GlobalKTable, allowing stateless and stateful transformations and windowing.
The Processor API on the other hand uses an imperative programming style and is suited for lower-level access to data, more granular access to the application state. It also offers more fine-grained control over the timing of certain operations. In so doing, it allows developers to define and use custom processors and to interact with state stores.
The following table gives an overview of a Hello World application programmed in Java with the Streams DSL and Processor API. The code developed using the Streams DSL is on the left side, and the code using the Processor API is on the right.
// the builder is used to construct the topology
StreamsBuilder builder = new StreamsBuilder();
// read from the source topic, "users"
KStream<Void, String> stream = builder.stream("users");
// for each record that appears in the source topic,
// print the value
stream.foreach(
(key, value) -> {
System.out.println("(DSL) Hello, " + value);
});
// you can also print using the `print` operator
// stream.print(Printed.<String, String>toSysOut().withLabel("source"));
// build the topology and start streaming
KafkaStreams streams = new KafkaStreams(builder.build(), config);
streams.start();
// the builder is used to construct the topology
Topology topology = new Topology();
topology.addSource("UserSource", "users");
topology.addProcessor("SayHello", SayHelloProcessor::new, "UserSource");
// build the topology and start streaming!
KafkaStreams streams = new KafkaStreams(topology, config);
System.out.println("Starting streams");
streams.start();
public class SayHelloProcessor implements Processor<Void, String, Void, Void> {
@Override
public void init(ProcessorContext<Void, Void> context) {
// no special initialization needed in this example
}
@Override
public void process(Record<Void, String> record) {
System.out.println("(Processor API) Hello, " + record.value());
}
@Override
public void close() {
// no special clean up needed in this example
}
}
Summary
Kafka Streams aims with a simple dataflow approach and easy data and programming models to simplify the development of stream processing applications. This article gave a good overview of features and functionalities of the Kafka Streams. The next article will present ksqlDB the other alternative used in the Kafka ecosystem to develop stream processing applications.
For more information about Kafka, Kafka Streams and/or ksqlDB visit seminar.ordix.de and book the Kafka seminar.
Seminarempfehlungen
Apache Kafka Grundlagen
Zum SeminarApache Kafka eine Einführung - kostenloses Webinar
Zum SeminarSenior Chief Consultant bei ORDIX
Kommentare