
ksqlDB: the Superpower in the Kafka universe - Part 1
Is there more to Kafka than the usual producer and consumer API?
In a previous article, this question was raised to introduce alternative solutions offered by Kafka for designing and building stream processing applications. Streams (Kafka Streams API) rich library was presented as such an alternative to the known producer and consumer. Why then write another article? Well, brace yourself, good things come in pairs and here comes ksqlDB: another solution within the Kafka ecosystem to build stream processing applications.
Why is another solution necessary? How is this different from Kafka Streams and other frameworks? Which use cases and issues is it addressing?
Some interesting questions this and coming articles will try to answer. This article is part of a 3-part series. The goal as with the previous articles is to give an overview of tools, technologies and frameworks provided by Kafka to leverage the development of different stream processing applications ranging from simple stream processing to real-time processing. It's recommended but not mandatory to read the previous article "Harnessing the Power of Kafka" about Kafka Streams before this one. In this first part, an overview of ksqlDB and its benefits will be presented.
ksqlDB: An introduction
ksqlDB is an open-source event streaming database purposefully built for stream processing applications on top of Apache Kafka. ksqlDB is the evolution of KSQL, a streaming SQL engine designed for Kafka. The initial project KSQL was renamed ksqlDB after the release of important new functionalities.
Both KSQL and ksqlDB are open-source available projects and technologies licensed under the Confluent Community License. Though both technologies are freely available with code accessible on GitHub. It is important to notice that the Confluent Community License does not fulfill all requirements defined by the Open-Source Initiative for open-source projects. This license restricts the possibility for competitors to provide commercial competing SaaS offering to Confluent Products offerings. The next article (part 2) in this series will give an overview of the various licensing options.
KSQL, ksqlDB and Kafka Streams pursue the same goal: to simplify the process of building stream processing applications. This article will focus on ksqlDB, and will draw, when necessary, differences between KSQL and ksqlDB.
KsqlDB simplifies the way stream processing applications are built, deployed, and maintained, by providing and combining:
- high-level query language abstraction
- relational database modeling
- integrated access to components in the Kafka ecosystem (Kafka Connect and Kafka Streams).
KsqlDB was released by Confluent in 2019. "ksqlDB" here refers to ksqlDB 0.6.0 and beyond, and "KSQL" refers to all previous releases of KSQL (5.3 and lower). KsqlDB is not backward compatible with previous versions of KSQL, meaning that ksqlDB doesn't run over an existing KSQL deployment.
Benefits of an additional stream processing solution
Integration of Kafka Stream, Producer and Consumer APIs
ksqlDB (as also applies to KSQL) is built on Kafka Streams, the stream processing framework of Kafka for writing streaming applications and microservices. It provides, through a SQL interface, a query layer for building event streaming applications on Kafka topics. This is a great advantage because it encapsulates the streams API, consumer API, and producer API into a single API, leveraging benefits attached to the different abstractions used by these APIs.
The underlying picture gives an overview of the different Kafka APIs used beneath ksqlDB and how ksqlDB operations are translated in these various Kafka APIs.
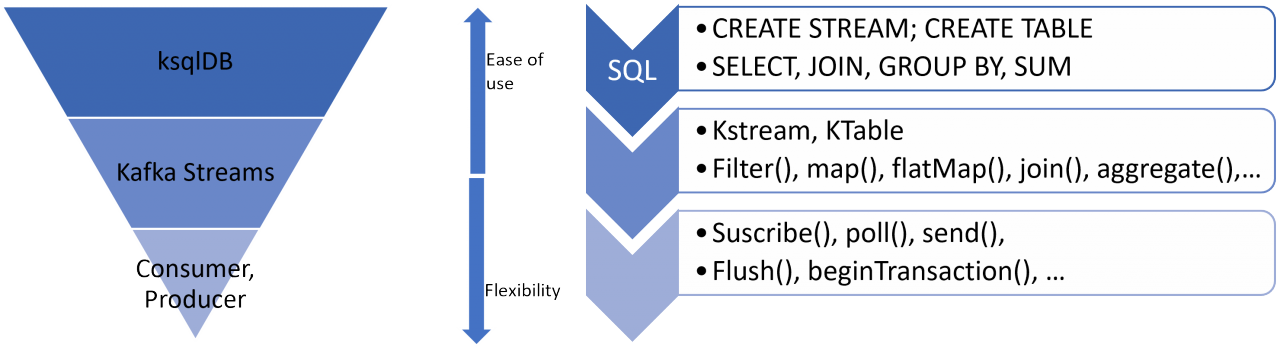
SQL statements in ksqlDB are translated into streams processors and topologies. Streams processors operators are executed on data collection underlying Kafka topics. Streams processors operations at their turn make use of consumers and producers API methods and operations.
Besides encapsulating and abstracting the APIs, ksqlDB makes use of all advantageous characteristics of Kafka Streams like the programming model, the various abstractions, the rich operations, internal organization for performant and fault-tolerant executions on topics and topics partitions.
The use of "event-at-a time" processing model (derived from Kafka Streams) combined to the power and simplicity of SQL hides the complexity of stream processing and facilitates the adoption and development of stream processing applications.
It is not necessary to understand topologies, processors to perform some tasks and inquiries.
In ksqlDB as in Kafka Streams, streams and tables are the two primary abstractions at the heart of processing logic. In ksqlDB they are referred to as collections. A stream represents an ordered, replayable, and fault-tolerant sequence of immutable data records. The article "Harnessing the Power of Kafka" gives a good understanding of data abstractions stream and table.
Events in ksqlDB (as in Kafka Streams) are manipulated by deriving new collections from existing ones and describing the changes between them. When a collection is updated with a new event, ksqlDB updates the collections that are derived from it in real-time.
The following picture depicts the processing of events in ksqlDB collections (tables). This example models an application that stores users' information in a Kafka topic called customers. The entries in the topic represent real world events happening over time.
The command CREATE TABLE is used to create the ksqlDB tables "customers" and "customers_cologne" containing respectively all customers and customers only residing in the city of cologne. For illustration purposes, the queries necessary to display the content of the tables were not displayed (select * from customers emit changes and select * from customers_cologne emit changes). Likewise, the structures of the ksqlDB tables were simplified to only represent the keys of a row contained within the tables. Other columns like name and city are left out of the picture.
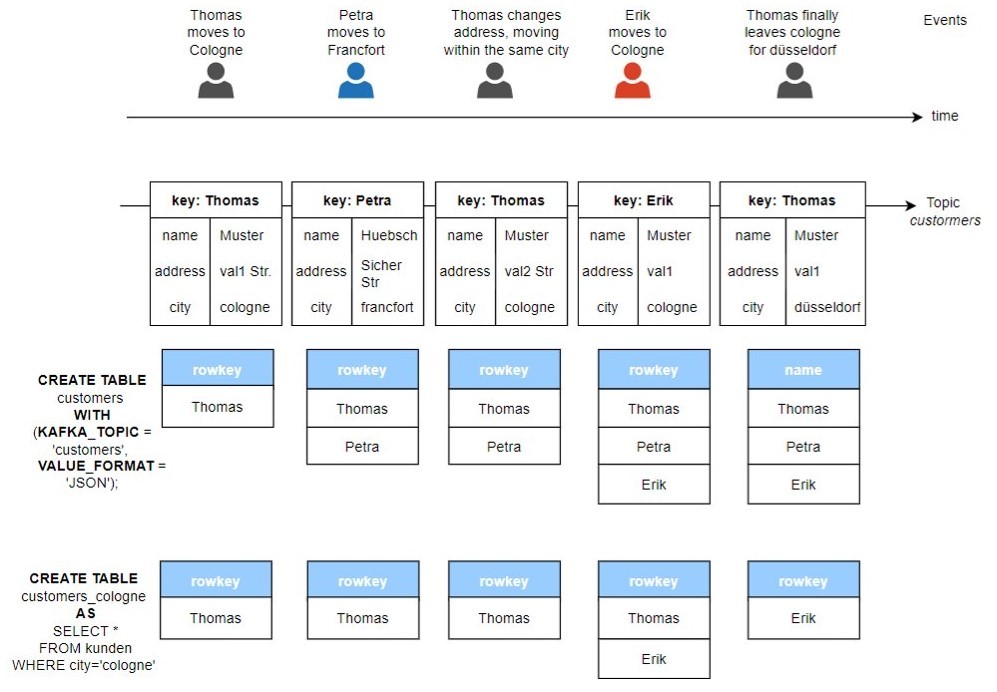
When the topic "customers" is updated, the tables "customers" and "customers_cologne" derived from the topic are updated accordingly.
The previous example (figure 2) illustrates also how defined programs operate continually over unbounded streams of events, ad infinitum, to stop only when explicitly terminated.
No coding necessary, no JVM
So far, we have known the producer, consumer, and streams APIs as ways of working with streams of data. All these approaches require some form of coding in a programming language such as Java or Python. ksqlDB (and KSQL) lower the entry bar to the world of stream processing, providing a simple and completely interactive SQL interface for processing data in Kafka. No longer is it required to write code. It is enough to use ANSI SQL based language, which is very widespread and has a greater acceptance and usage across different roles in IT companies.
The use of SQL instead of a programming language removes the necessity of a JVM and its setting for running a stream processing application. With ksqlDB, one can create continuously updating, materialized views of data in Kafka, and query those materializations in a variety of ways with SQL-based semantics.
SQL the Magic Bullet: the declarative factor, the SQL interface and the simplified logic
SQL is known to be a declarative query language since it only defines what data is desired for retrieval, abstracting over the "how" data is retrieved and built. Declarative approaches specify the "what" in contrary to the "how". Embracing this declarative approach, ksqlDB hides details about internal implementations and how the output is built, allowing users and developers to only consider what result is desired. This is also another advantage of ksqlDB (and KSQL).
By adapting SQL to streaming use cases, ksqlDB takes advantage of all the known benefits of systems using classical SQL:
- Succinct and expressive syntax that reads like English
- Declarative programming style
- A low learning curve
The use of SQL as a query language enables the use of stream processing logic by a larger audience. SQL is widely adopted in industries and used not only by developers. This allows all involved parties and stakeholders to be able to query and process the data.
In addition, ksqlDB enables an increase of productivity for application development. It takes less time to develop a stream processing application and the interactive character of SQL allows for faster feedback loops, cross-functional testing, and verification. The work is no longer solely dependent on developers. The desired logic and functionalities can be implemented and tested by a wider team of personas, all people who can write SQL queries.
Support of ETL processes through integration of different Kafka components
ksqlDB integrates Kafka Streams and Kafka Connect into a single solution. For a reminder, Kafka Streams allows users to develop stream processing logic and Kafka Connect offers access to external systems reading from the sources into topics or writing into the systems.
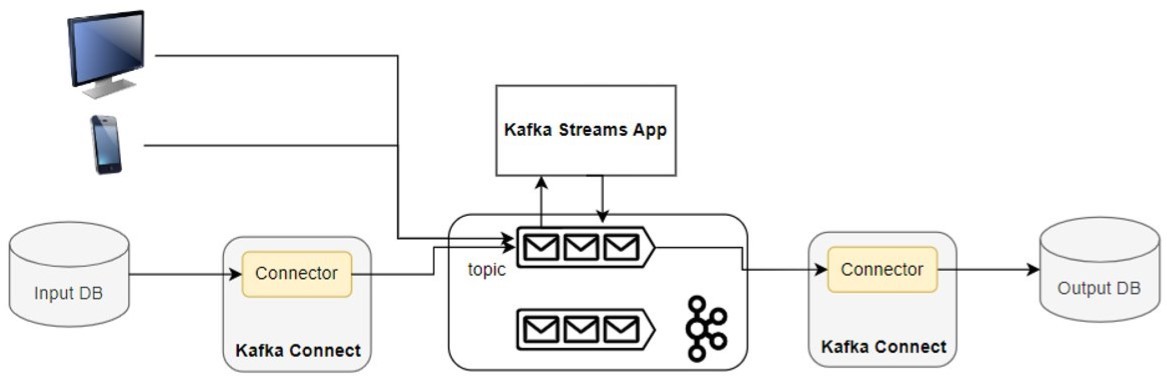
The figure 2 presents an example of a scenario in which external data to Kafka is processed by a Kafka Streams application and the output of the application is written to a sink (database). Data from different user interfaces and a database are stored into Kafka topics for further processing. This is a typical scenario when data from external sources and Kafka topics are to be processed. A data pipeline is needed to move data to and from the appropriate systems. Kafka Connect is commonly used as a support for ETL processes, allowing the extraction of data from numerous sources and the loading of processed data into numerous sinks. It provides an automatic way of extracting data from external sources into topics in the extraction process and writing topics data into sinks.
Developers of streaming applications must accomplish the following tasks:
- provide connectors if not existent to extract the data from the source database and write results into the desired sink (database)
- implement a producer application to write data from user interfaces into a Kafka topic
- implement a stream processing application with Kafka Streams to process all data, making use of the output connector to write the result into the defined sink
- maintain a Kafka Connect deployment, making sure the Connect installation runs. An external deployment is necessary to run Kafka Connect, and developers and teams must make sure to provide appropriate sink and source connectors for all tasks.
In its early form KSQL, the integration and use of non-Kafka data sources required additional architectural complexities and operational overhead due to the integration with Kafka Connect which required a separate overlay system and increased connector management.
The move from KSQL into the more advanced form, ksqlDB, is accompanied by the adding of a Kafka Connect integration within the architecture. Additional SQL constructs were defined not only to specify source and sink connectors but also to use in a simple way defined connectors in queries. It became also possible to manage and execute from within a ksqlDB application (or ksqlDB query) connectors in an externally deployed Kafka Connect cluster, or to run a distributed Kafka Connect cluster alongside a ksqlDB installation for an even simpler setup.
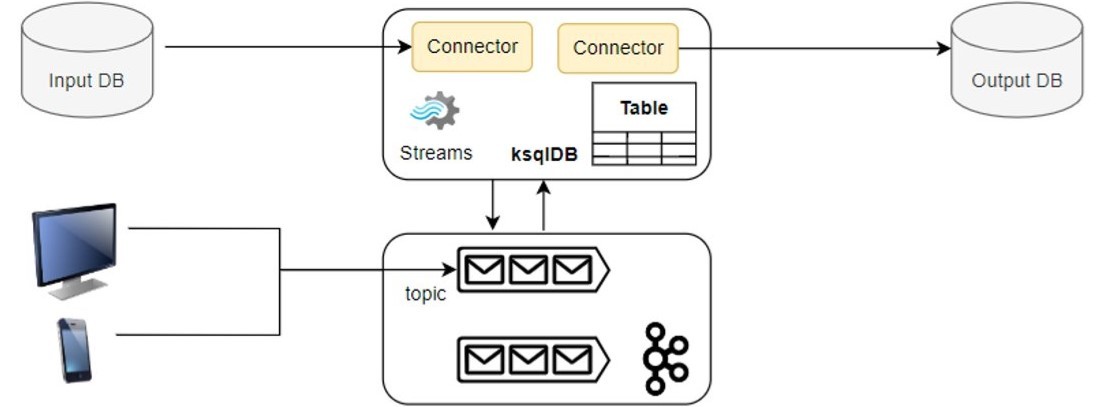
Figure 4 shows the difference ksqlDB brings into stream processing. In contrast to Figure 3, the work performed by the Kafka Streams App and the different connectors is integrated into ksqlDB. Data from the user interfaces and the input source is processed within a single application.
ksqlDB supports the full ETL life cycle of an event stream, covering the transformation part of an ETL process through the Kafka Streams integration and the extraction and loading parts through the Kafka Connect integration. Simply said, ETL based applications can be easily developed using ksqlDB only. With the help of SQL queries in ksqlDB, users can define sources and sinks connectors, extract from the sources, process data streams and write back the results to the sinks.
Summary
ksqlDB is "the streaming database for Apache Kafka". It simplifies the way stream processing applications are built through
- the integration of producer, consumer, streams, connect APIs, data abstractions and internal organization
- the use of SQL
This article gives an overview of ksqlDB and present some advantages it gives, providing in this way an answer to the questions of the benefits of an additional stream processing solution and the difference between this new approach and Kafka Streams. This article is part of a 3-part series.
The next article will drive deeper into ksqlDB and its architecture.
Senior Chief Consultant bei ORDIX
Kommentare