
Neuigkeiten im Überblick - Apache Hadoop 3 (Teil 1)
Die Features der Hadoop Version 3 sind bereits seit Ende 2017 verfügbar, wurden aber erst Mitte 2018 von den großen kommerziellen Distributionen adaptiert. Es gibt zu beachtende Änderungen, wie zum Beispiel die Neubelegung der Service Ports, aber auch neue Features, wie den Support für Erasure Coding innerhalb des HDFS. Die Plattformen Hortonworks HDP 3 und Cloudera CDH 6 enthalten Hadoop 3, es werden jedoch nicht zwingend alle Features unterstützt. Wir geben einen Überblick über die Neuerungen und beleuchten die wichtigen Features der neuen Hadoop-Version.
Was bringt Hadoop 3?
Obwohl Hadoop 3 schon länger verfügbar ist, basieren viele produktive Deployments noch auf Hadoop 2. Dies liegt vor allem daran, dass die kommerziellen Distributionen die neuen Open-Source-Versionen mit einem zeitlichen Versatz adaptieren. Im Folgenden werden wir die wichtigsten neuen Features beleuchten, um einen Überblick über die Änderungen zu geben.
Speicherplatz einsparen mit Erasure Coding
Mit Hadoop 3 kommt ein mächtiges Feature, das eine starke Reduzierung des Brutto-Datenverbrauchs durch das HDFS ermöglicht. Bisher war es üblich, die Datenblöcke dreifach zu replizieren, was einen Speicher-Overhead von 200% mit sich bringt. Mit Erasure Coding lässt sich der Overhead auf bis zu 40% reduzieren.
Bei Erasure Coding werden die Daten meist in 1024-KB-Blöcke aufgeteilt und zu einer konfigurierbaren Anzahl an Datenblöcken Paritätsblöcke generiert. Zur Widerherstellung von verlorenen Datenblöcken (z.B. Ausfall eines
DataNodes), werden die Paritätsblöcke zur Berechnung genutzt. Als theoretische Grundlage dienen unter anderem Reed-Solomon-Codes, welche bereits in anderen Bereichen praktisch angewendet werden (z.B. bei optischen Datenträgern oder im Festplattenverbund RAID 6).
Ein großer Vorteil in bestehenden Clustern ist die Möglichkeit, Replikation und Erasure Coding gleichzeitig betreiben zu können. So lassen sich verschiedene Policies für Erasure Coding auf einzelne Verzeichnisse im HDFS gleichzeitig aktivieren. Eine Migration erfolgt dann über einfaches Kopieren im HDFS.
Für den Produktivbetrieb empfiehlt es sich, die Intel ISA-L Library einzubinden, um die Berechnungen für Erasure Coding nativ ausführen zu lassen. Weil der Datendurchsatz groß genug ist, wird der mögliche Bottleneck auf Netzwerkhardware und Festsplatten verlagert [Q1].
Darüber hinaus ist zu beachten, dass der Vorteil des geringeren Speicherverbrauchs bei besonders vielen kleinen Dateien zunichte gemacht wird. Eine Datei, die kleiner als 1024 Kibibyte ist, verbraucht bei drei Datenblöcken und zwei Paritätsblöcken trotzdem 300% Speicher.
Wie funktioniert Schreiben, Lesen und Verarbeiten mit Erasure Coding?
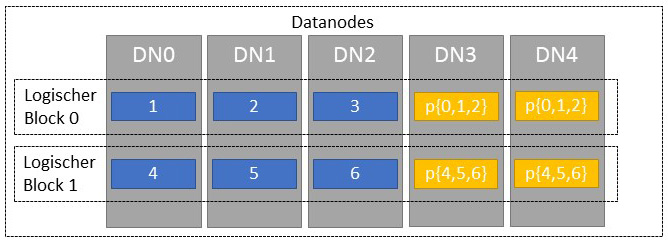
Beim Schreiben teilt der HDFS Client die Daten in Blöcke auf, die meist 1024 KB groß sind. Je nach Einstellung (Coding Policy) werden jeweils für eine feste Anzahl an Blöcken Paritätsblöcke generiert (siehe Abbildung 1). Die Blöcke werden dann über die DataNodes verteilt (siehe Abbildung 2). Dabei muss die Anzahl der DataNodes mindestens der Anzahl der Daten- und Paritätsblöcken entsprechen. Bei der Coding Policy RS-6-3-1024k würde man mindestens neun DataNodes benötigen, um sechs Daten- und drei Paritätsblöcke verteilen zu können.
Beim Lesevorgang werden zunächst nur die DataNodes vom Client angesprochen, die Datenblöcke enthalten. Nur falls ein DataNode mit dem angeforderten Datenblock ausfällt, werden die Paritätsblöcke angefordert und Berechnungen zur Widerherstellung durchgeführt.
Im Gegensatz zur Dreifachreplikation, ist bei Erasure Coding keine Data Locality gegeben, wenn Berechnungen (z.B. Spark oder Mapreduce) auf Daten ausgeführt werden. Die Blöcke werden streifenweise (Striped Layout) abgelegt. Vor einer Verarbeitung wird dadurch mehr Netzwerklast erzeugt, da logisch zusammenhängende Daten zunächst zusammengefasst werden müssen.

Welche Coding Policies gibt es?
Hadoop 3 erlaubt die Verwendung verschiedener Konfigurationen für Erasure Coding als Policies. Die Policy XOR-2-1-1024K ist kein Reed-Solomon-Code, sondern basiert auf der bitweisen Verknüpfung XOR (Exklusives-Oder).
Die Policies bieten für verschieden Cluster-Konfigurationen Vor- und Nachteile. Für eine größere Anzahl an Daten- und Paritätsblöcken, wird ein entsprechend großer Cluster vorausgesetzt. Eine geringere Anzahl an Blöcken verringert die Ausfalltoleranz.
Die Datenblöcke enthalten die Nutzdaten und die Paritätsblöcke sichern gegen Ausfälle und Datenverlust. Zum Beispiel bietet der Code RS-3-2-1024k eine Verlusttoleranz von bis zu zwei Blöcken bei fünf Blöcken insgesamt.
| Policy | Datenblöcke | Paritätsblöcke | Blockgröße |
| RS-3-2-1024k | 3 | 2 | 1024 KiB |
| RS-6-3-1024k | 6 | 3 | 1024 KiB |
| RS-10-4-1024k | 10 | 4 | 1024 KiB |
| RS-LEGACY-6-3-1024k | 6 | 3 | 1024 KiB |
| XOR-2-1-1024k | 2 | 1 | 1024 KiB |
Wie werden Erasure-Codes aktiviert?
Die Policies zur Verwendung der Erasure Codes müssen zunächst für den Cluster über die Shell aktiviert werden:
$ hdfs ec -enablePolicy -policy
Beispiel:
$ hdfs ec -enablePolicy -policy RS-3-2-1024k
Anschließend wird für ein Verzeichnis und dessen Unterverzeichnisse rekursiv die Policy gesetzt:
$ hdfs ec -setPolicy -path -policy
Beispiel:
$ hdfs ec -setPolicy -path /folder/subfolder -policy RS-3-2-1024k
Alle Daten, die sich in diesem Pfad befinden werden nun mit Erasure Coding im HDFS verteilt. Für die Migration dreifach replizierter Daten nach Erasure Coding, reicht ein Verschieben oder Kopieren aus:
$ hadoop fs -mv /replicated_data /ec_data
Unterstützung von mehr als drei HDFS NameNodes
Bisher erlaubte Hadoop 2 nur ein Deployment mit bis zu zwei NameNodes. Hadoop 3 hebt diese Grenze auf und erlaubt mehr NameNodes gleichzeitig. Zu einem Zeitpunkt darf weiterhin nur ein NameNode aktiv sein (Active-
Passive) und in die Edit-Logs der JournalNodes schreiben. Die JournalNodes dienen der Synchronisation der NameNodes. Das automatische Failover kann mit dem Zookeeper Failover Controller (ZKFC) in Verbindung mit einem Zookeeper-Cluster realisiert werden.
Wie wird ein Split-Brain-Szenario verhindert?
Um bei einem möglichen Split-Brain-Szenario, zum Beispiel bei einer Netzwerktrennung, ein gleichzeitiges Schreiben in die Edit-Logs durch unterschiedliche NameNodes zu vermeiden, wird der Quorum Journal
Manager (QJM) verwendet.
Jeder NameNode handelt mit den JournalNodes eine zentrale Epoch-Zahl aus. Bei mehreren aktiven NameNodes wird der zuerst anfragende NameNode gewinnen – sofern die Mehrheit der JournalNodes die neue Epoch-Zahl bestätigt.
Alle anderen NameNodes, die danach versuchen, eine Epoch-Zahl festzulegen, scheitern und fahren sich selbst herunter. Der tatsächlich aktive NameNode sendet nun mit jeder Schreibanfrage die Epoch-Zahl mit, welche durch die JournalNodes mit der zentralen zur Autorisierung verglichen wird.
Links/Quellen
[Q1] Einführung in Erasure Coding (Cloudera Blog)
http://blog.cloudera.com/blog/2015/09/introduction-to-hdfs-erasure-coding-in-apache-hadoop/
Fortsetzung
Lesen Sie den nächsten Teil zu "Neuigkeiten im Überblick - Apache Hadoop 3" hier in unserem Blog. Nicht verpassen!
Kommentare