
Docker Security Internals: Sind meine Container sicher und wenn ja warum?
Technologische Probleme
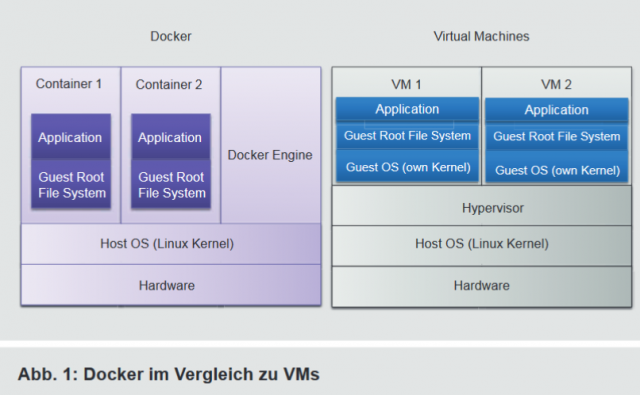
Im Gegensatz zur Voll- bzw. Paravirtualisierung (z. B. VMware ESXi oder KVM), bei denen jeder Gast einen eigenen Kernel benötigt, nutzen Container den Kernel des Hostsystems. Dies ermöglicht eine bessere Performance, da der Hypervisor und der Kernel des Gastsystems als Zwischenschicht entfallen (siehe Abbildung 1). In diesem Umstand ist jedoch auch der größte Nachteil der Container-Virtualisierung begründet. Aufgrund der geringen Trennung sind vielfältige Maßnahmen notwendig, um die Container voneinander und vom Host-System abzugrenzen und deren Rechte einzuschränken.
Security auf verschiedenen Ebenen
Die Sicherheitsmaßnahmen, die von Docker genutzt werden, werden auf unterschiedlichen Ebenen realisiert. Auf der untersten Ebene implementiert der Kernel u. a. Namespaces und Control Groups, die die grundlegenden Funktionalitäten für die Container-Virtualisierung unter Linux bereitstellen. Die zweite Ebene bilden z. B. die Mandatory Access Control (MAC) Lösungen AppArmor und SELinux, die den Kernel um zusätzliche Sicherheitsfeatures erweitern. Darüber hinaus kann Docker selbst abgesichert werden. Dies umfasst Einschränkungen beim Zugriff auf den Daemon, Tools für die Analyse der Images auf Sicherheitsprobleme und den Betrieb einer eigenen Docker Registry. Die verschiedenen Möglichkeiten auf den einzelnen Ebenen werden im Folgenden erläutert.
Namespaces
Docker nutzt die Kernel-Namespaces, um die Container voneinander abzugrenzen. Sie ermöglichen es, Container isoliert voneinander und vom Host-System zu betreiben, indem sie eine Abstraktionsschicht um die globalen Ressourcen bilden. Für die Prozesse in einem Namespace scheint es, als hätten sie alleinigen Zugriff auf die jeweiligen Ressourcen. Die Namespaces bilden somit die grundlegendste und wichtigste Security-Ebene. Kurz gesagt: Ohne Namespaces keine Docker-Container. Der Kernel implementiert die Namespaces IPC, Mount, Network, PID, User und UTS, die in den folgenden Abschnitten erläutert werden. Zudem wird aufgezeigt, wie diese Namespaces von Docker genutzt werden können.
Der IPC-Namespace stellt den Containern einen isolierten Zugriff auf System V IPC Objects (Message Queues, Semaphoren und Shared Memory Segmente), sowie POSIX Message Queues bereit. Jeder IPC-Namespace hat eigene System V IPC Identifier und ein eigenes POSIX Message Queue Filesystem. Damit sind die Objekte nur für die Prozesse in dem Namespace sichtbar. Wenn ein IPC-Namespace zerstört wird, werden automatisch alle IPC-Objekte, die zu diesem Namespace gehören, gelöscht. Bei Docker haben alle Container standardmäßig einen eigenen IPC-Namensraum. Beispielsweise ist es jedoch mit der Option --ipc="container:test" möglich, einen Container zu starten, der den IPC-Namespace mit dem Container „test" teilt.
Mithilfe des Mount-Namespace kann Prozessen eine separate Sicht auf die Dateisystem-Hierarchie ermöglichtwerden. Er spielt somit für Docker eine zentrale Rolle. Jedem Container wird ein eigenes root-Filesystem auf Basis eines konfigurierbaren Image zur Verfügung gestellt. Darüber hinaus bietet Docker vielfältige Möglichkeiten, Daten über Volumes innerhalb von Containern bereitzustellen. Dies liegt nicht im Fokus dieses Artikels, kann aber in dem Docker-Artikel in den ORDIX® news 2/2015 nachvollzogen werden.
Die Isolation von Netzwerk-Ressourcen (u. a. Netzwerk-Devices, Protokoll-Stacks und Firewalls) erfolgt über den Network-Namespace. Docker-Container verfügen ohne spezielle Konfiguration über ein eigenes Loopback und ein eigenes virtuelles Interface, welches mit einer Bridge verbunden ist und die Kommunikation nach außen ermöglicht. Dies entspricht der Option --net=bridge. Um einen Container vollständig von der Außenwelt abzuschotten, kann er mit der Option --net=none gestartet werden. Ähnlich wie beim Mount-Namespace bietet Docker auch im Bereich Networking viele weitere Optionen. So kann ein Container den Network-Namespace etwa mit dem Host-System oder einem anderen Container teilen.
Für den Betrieb von Containern ist es wichtig, dass diese einen eigenen PID-Namespace besitzen, damit sie keine Kenntnis von den Prozessen außerhalb ihres Namensraums haben. Durch die hierarchische Anordnung der PID-Name-spaces ist es dem Parent Namespace möglich, die Prozesse seiner Children zu sehen und zu beeinflussen. Dies führt dazu, dass ein Prozess in einem Child Namespacemehrere PIDs besitzt – eine in seinem Namensraum und eine in dem Parent Namespace (Host-System). Für Docker Container wird automatisch ein eigener PID-Name-space generiert. Bei besonderen Anforderungen kann der Container mittels --pid=host auch den Namensraum mit dem Host-System teilen.
Ein wichtiger Schritt für die Sicherheit von Containern ist die Unterstützung des User-Namespace durch die Docker Engine ab Version 1.10. Seitdem kann ein Container eine eigenständige UID- und GID-Range besitzen, die außerhalb des Containers auf einen unprivilegierten Benutzer gemappt wird. Demnach können Prozesse innerhalb eines Containers als Benutzer root laufen und damit in dem Namespace über entsprechende Rechte verfügen, auf dem Host-System agieren sie aber „nur" als normaler Benutzer. Im Gegensatz zu den anderen Namespaces wird der User-Namespace von Docker nicht per Default verwendet, sondern muss erst aktiviert werden. Dies lässt sich damit begründen, dass bei der Verwendung des Namespace eine Koordination mit anderen Komponenten erforderlich ist. Zum Beispiel beim Mapping von Volumes vom Host in den Container, müssen im Vorfeld die Dateirechte angepasst werden, damit der Container auf diese zugreifen kann.
Über die Option --userns-remap=default erfolgt die Aktivierung global, die dem Docker Daemon beim Start mitgegeben werden kann. In Folge dessen wird für alle Container der User-Namespace automatisch aktiviert, der jedoch über die Option --userns=host beim Erstellen eines Containers explizit wieder deaktiviert werden kann. Der Parameter default für die Option userns-remap bewirkt, dass Docker einen Benutzer und eine Gruppe mit dem Namen dockremap erstellt, falls diese noch nicht existieren. Darüber hinaus wird eine 65536 lange, zusammenhängende Range in der /etc/subuid bzw. /etc/subgid reserviert, die auf den Benutzer bzw. die Gruppe dockremap gemapped wird.
Docker Container werden standardmäßig mit einem eigenen UTS-Namespace gestartet. Sie verfügen somit über einen eigenen Host- und Domänenamen. Um den UTS-Namespaces des Hosts auch im Container zu nutzen, kann dieser mit der Option --uts=host erstellt bzw. gestartet werden. Aus Security-Sicht ist von einer solchen Konfiguration jedoch abzuraten, da aus dem Container der Hostname des Host-Systems geändert werden könnte.
Control Groups
Control Groups oder kurz Cgroups sind die zweite Kernkomponente der Container-Virtualisierung unter Linux. Sie wurden in der ORDIX® news 3/2010 bereits ausführlich besprochen und dort können die im Folgenden erwähnten Eigenschaften im Detail nachvollzogen werden. Docker nutzt die Cgroups mit Blick auf das Thema Security, um die Ressourcennutzung von Containern zu beschränken, so dass sie sich untereinander und das Host-System nicht beeinflussen können. Im Wesentlichen können die in Abbildung 2 aufgeführten Eigenschaften über die angegebene Option beim Erstellen bzw. Starten des Containers gesetzt werden. Seit der im April 2016 veröffentlichten Docker Version 1.11 kann zusätzlich der PIDs Resource Controller verwendet werden, der mit dem Kernel 4.3 eingeführt wurde. Dieser ermöglicht die Limitierung der Anzahl der Prozesse in einer Control Group und kann damit z. B. verhindern, dass Fork-Bomben in einem Container das ganze System beeinträchtigen.

Capabilities
Die Capabilities sind ein Standard-Feature des Linux-Kernels und stehen schon mehrere Jahre zur Verfügung. Sie werden allerdings verhältnismäßig selten eingesetzt, da ihre Konfiguration tiefe Kenntnisse über die verwendeten Applikationen erfordern. Von Docker werden sie jedoch standardmäßig eingesetzt, da sie die Sicherheit von Containern erhöhen. Im Allgemeinen wird mithilfe von Capabilities das starre root/non-root Rechtesystem von Linux durch eine granulare Rechteverwaltung abgelöst. Ein root-User in einem Container benötigt nicht die vollständigen root-Rechte, da ein Großteil der Verwaltung auf dem Host-System erfolgt und im Container nur die eigentliche Anwendung betrieben wird.
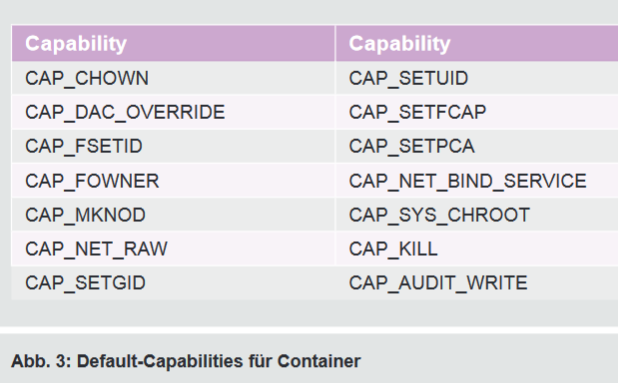
Docker entzieht den Containern viele Rechte (Capabilities), so dass auch der root-User in einem Container bestimmte Tasks nicht ausführen kann. Zu diesen gehören z.B. alle Mount-Operationen und das Laden von Kernel-Modulen. Dabei wurde ein Whitelist-Ansatz gewählt und dem Container werden nur die explizit definierten Rechte gewährt. Eine vollständige Liste ist in Abbildung 3 aufgeführt. Dies erschwert Angreifern, die Zugriff zu einem Container erlangt haben, den Ausbruch erheblich. Der Administrator hat die Möglichkeit, Capabilities über den Standard hinaus anzupassen, indem er über die Optionen --cap-add bzw. --cap-drop weitere Capabilities hinzufügt oder entfernt.
Seccomp-Profile
Ein weiteres Feature des Linux-Kernels ist der Secure Computing Mode (Seccomp). In Verbindung mit Docker wird verhindert, dass Applikationen in einem Container definierte Systemcalls ausführen können. Dies überschneidet sich zum Teil mit den beschriebenen Capabilities, bietet aber einen detaillierteren Ansatz. Docker unterstützt Seccomp seit der Version 1.10 und ermöglicht die Konfiguration der erlaubten bzw. verbotenen Systemcalls über JSON-Profile. Wenn der Kernel Seccomp unterstützt, werden alle Container mit einem Default-Profil gestartet, das aktuell den Aufruf von 44 Systemcalls verbietet. Das Default-Profil kann entweder mit der Option --security-optseccomp=unconfined deaktiviert oder durch die Angabe eines selbst erstellen Profils überschrieben werden
AppArmor, SELinux & Co
Mandatory Access Control (MAC) Systeme ermöglichen es über die üblichen Dateisystemrechte hinaus, den Zugriff auf Objekte für einzelne Prozesse zu regulieren. Dies kann genutzt werden, um die Rechte von Containern einzuschränken und damit zur Sicherheit beizutragen. Für Linux stehen mehrere Lösungen zur Verfügung, u. a. AppArmor, Grsecurity, SELinux, Smack und TOMOYO. Da die wichtigsten Distributionen entweder AppArmor oder SELinux einsetzen, werden nur diese beiden Lösungen im Folgenden vorgestellt. Beide nutzen das Linux Security Modules (LSM) Framework des Kernels und bieten somit einen ähnlichen Funktionsumfang.
AppArmor ist seit der Version 2.6.36 im Kernel integriert und wird von den Suse-Distributionen und Ubuntu eingesetzt. Die Konfiguration von AppArmor für einzelne Anwendungen erfolgt über sogenannte Profile, die entwedervon dem Distributor mitgeliefert oder händisch erstellt werden müssen. Der Vorteil von AppArmor liegt in der guten Lesbarkeit der Profile. Dies erleichtert den Einstieg und macht die Nutzung auch für weniger versierte Administratoren möglich. Für Docker werden bereits Profile von Suse (/etc/apparmor.d/docker) bzw. Ubuntu (/etc/apparmor.d/docker-default) mitgeliefert. Sie regulieren u. a. den Zugriff auf /proc und /sys und werden, wenn AppArmor aktiviert ist, automatisch genutzt.
SELinux wurde mit dem 2.6er-Kernel eingeführt und ursprünglich von der NSA entwickelt. Es ist die Default-MAC-Lösung der Red Hat Distributionen, die aktuell einen Großteil der Entwicklung tragen. Im Vergleich zu AppArmor bietet SELinux eine detailliertere Konfiguration, die jedoch deutlich komplexer ist. Alle Dateien, Verzeichnisse, Devices usw. werden mit einem Label (Security-Context) versehen. Dieses besteht aus den Informationen User, Role, Type und Level, die eine Kombination aus Role- Based Access Control (RBAC), Type Enforcement (TE) und optional Multi-Category Security (MCS) und Multi-Level Security (MLS) ermöglichen. Für Docker unter Red Hat wird eine Policy, in der verschiedene Rules zusammengefasst sind, mitgeliefert. Sie sichert mittels Type Enforcement das Host-System ab. Zusätzlich werden die einzelnen Container voneinander abgegrenzt, indem jedem Container ein eindeutiges Level zugewiesen wird (MCS).
Absicherung des Daemons
Neben dem Einsatz der verschiedenen Kernelfeatures und einer der MAC-Lösungen, sollte der Docker Daemon (Engine) abgesichert werden. Da der Daemon als root läuft, hat jeder Benutzer, der Container starten kann, im Prinzip root-Rechte auf dem System. Er könnte z. B. /etc als Volume in einem Container zur Verfügung stellen und damit die Passwort-Hashes in der /etc/shadow lesen und diese evtl. entschlüsseln. Dies wird zwar in der Standardkonfiguration von AppArmor und SELinux unterbunden, häufig wird Docker aber auch ohne eine MAC-Lösung eingesetzt bzw. deren Konfiguration könnte fehlerhaft sein.
Dementsprechend sollte es nur definierten Benutzern möglich sein, Container zu starten. Die Engine kann Anfragen über drei verschiedene Sockets (Unix, TCP und FD) empfangen. Es ist notwendig, die Möglichkeiten des Zugriffs für die verschiedenen Arten zu kennen, um diese ggf. einzuschränken. Der Socket (/var/run/docker.sock), der der Default ist, sollte mit möglichst geringen Rechten versehen werden. Abhängig von der genutzten Distribution unterscheiden sich die Standardrechte und Docker ist entweder nur als root bzw. auch für Mitglieder der Gruppe docker verwendbar.
Die Option -H fd:// für den Docker-Daemon führt dazu, dass der beschriebene Socket nicht vom Docker-Daemon selbst, sondern über Socket-Aktivierung von systemd angelegt wird und dieser die Anfragen an Docker weiterleitet. In diesem Fall müssen die Rechte - falls erforderlich - in der docker.socket Unit angepasst werden. In einem professionellen Umfeld wird Docker häufig aus der Ferne administriert. Um den Zugriff zu ermöglichen, muss Docker mit der Option –H <IP-Adresse>:<Port> gestartet werden. Diese Verbindung ist jedoch ohne weitere Konfiguration unverschlüsselt und unautorisiert. Über die Option --tlsverify und mit der Angabe eines Zertifikats, dessen Keys und dem Zertifikat der CA kann die Verbindung zum Client verschlüsselt werden. Zusätzlich akzeptiert der Daemon nur noch Verbindungen von Clients, die über ein entsprechendes Client-Zertifikat verfügen.
Authorization Plugins
Beim Twistlock AuthZ Broker erfolgt die Authentifizierung über Docker, indem der Benutzername aus dem Client-Zertifikat genutzt wird. Auf Basis dieses Namens kann konfiguriert werden, welche Operationen der Nutzer durchführen darf. Die Möglichkeiten reichen von der Freigabe aller Befehle bis hin zu einem readonly-Zugriff auf die Logfiles eines bestimmten Containers. Somit kann Docker auch in Umgebungen eingesetzt werden, in denen unterschiedliche Parteien Zugriff auf eine Engine haben.
Images im Fokus
Die Absicherung des Hosts und die Trennung der Container untereinander wurden in den bisherigen Punkten erläutert. Letztendlich werden jedoch Anwendungen in Containern betrieben, die ebenfalls möglichst sicher sein sollten. Docker hat Ende 2015 mit Nautilus ein Projekt vorgestellt, mit dem die Images im offiziellen Repository auf Schwachstellen überprüft werden. Nautilus ist jedoch, trotz anderer Versprechen, noch nicht für die Öffentlichkeit freigegeben.
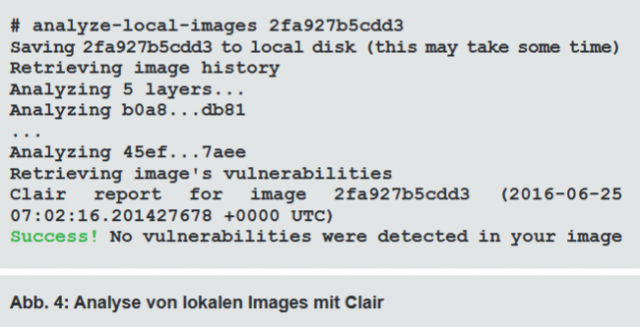
Mit Clair steht jedoch eine Alternative bereit, die von CoreOS entwickelt wird. Clair führt statische Analysen durch und scannt damit Images und nicht laufende Container. Dabei wird jede Schicht des Images separat analysiert. Für die Erkennung von Schwachstellen greift Clair auf die Common Vulnerabilities and Exposures (CVE) Datenbanken von Debian, Red Hat und Ubuntu zurück. Der einfachste Weg, Clair einzusetzen, ist das analyze-local-images Tool. Mit ihm können eigene oder aus dem Docker Hub bezogene lokale Images auf Sicherheitsprobleme untersucht werden (siehe Abbildung 4). Wird eine eigene Docker Registry betrieben, kann Clair in die Registry integriert werden, um die Analyse zu automatisieren.
Kein root im Container
Eine weitere Maßnahme zur Absicherung der Container ist, Applikationen innerhalb des Containers, wie auch auf einem normalen System, möglichst ohne root-Rechte zu betreiben. Je weniger Rechte eine Applikation hat, umso schwieriger ist es für einen Angreifer, über die Applikation hinaus Rechte zu erlangen. Dieser Grundsatz gilt auch für Docker-Umgebungen und ebenfalls wenn der User-Namespace eingesetzt wird. Es sollte somit schon im Dockerfile über die Option USER<non-rootUser> sichergestellt werden, dass die Applikation als unprivilegierter Benutzer läuft.
Private Registry
Das öffentliche Verzeichnis für Docker Images ist das Docker Hub. Es bietet Zugriff auf tausende Images der Community und aus offiziellen Quellen. Dies erlaubt einen schnellen und unkomplizierten Betrieb von Docker, aber es gibt trotzdem mehrere Gründe, eine eigene Registry zu betreiben. Dafür sprechen z. B. die volle Kontrolle über den Speicherort der Images, der fehlende Zwang für eine Verbindung ins Internet und aus Security-Sicht die Möglichkeit, die verfügbaren Images zu kontrollieren. Für den Betrieb einer privaten Registry kann entweder die unter der Apache-Lizenz veröffentlichte und frei verfügbare Docker Registry oder die Trusted Registry, für die die Docker Inc. Support anbietet, verwendet werden. Im einfachsten Fall wird die freie Registry in einem Container betrieben. Dafür steht das offizielle Image registry bereit.
Fazit
Dieser Artikel hat gezeigt, dass vielfältige Maßnahmen auf den unterschiedlichen Ebenen zur Verfügung stehen, um Docker Container sicher betreiben zu können. Insbesondere in den letzten Releases (seit Anfang 2016) sind viele Features hinzugekommen, die zur Sicherheit von Containern beitragen. Die Betrachtung der einzelnen Features auf unterschiedlichen Ebenen vereinfacht deren Einordnung und bringt Ordnung in das Chaos. Dies ist wichtig, da nur eine Kombination aus den Kernel-Features, den MAC-Lösungen (AppArmor und SELinux), der Absicherung der Engine und die sichere Gestaltung der Images einen sicheren Betrieb von Docker ermöglichen.
Quellen
[Q1] Schürmann, Tim, „Systemsicherheit erhöhen mit Grsecurity".
In: ADMIN, IT Praxis & Strategie,
http://www.admin-magazin.de/Das-Heft/2012/04/Systemsicherheit-erhoehen-mit-Grsecurity
[Q2] Docker Security:
https://sreeninet.wordpress.com/2016/03/06/docker-security-part-1overview/
[Q3] Frazelle, Jessi, „Docker Engine 1.10 Security Improvements",
https://blog.docker.com/2016/02/docker-engine-1-10-security/


Principal Consultant bei ORDIX
Kommentare