
Talend, NiFi, Spark & Pandas als Data- Engineering-Tools? - Datapreprocessing von Wetterdaten
In meinem letzten Blogartikel habe ich die Data Science Pipeline (DSP) und insbesondere den Bereich des Data Engineerings anhand meines Praxisprojekts "Evaluierung & Dokumentation der Data Science Pipeline (mit Fokus auf den Data Engineering Kreislauf)" vorgestellt. Dabei lag der Fokus vor allem auf den verschiedenen Arbeitsschritten des Data Engineering Kreislaufs. Dieser Kreislauf bildet das Fundament eines jeden Data-Science-Projektes und zudem die theoretische Basis für die folgenden Inhalte. Dieser Blogartikel konzentriert sich auf mögliche Data-Engineering-Tools, welche im Evaluationsteil meiner Praxisphase untersucht wurden. Zu den evaluierten Tools gehören Python-Bibliotheken wie Pandas und Open Source Tools wie Apache Spark, Talend Open Studio for Data Integration und Apache NiFi. Die Tool-Auswahl wurde aufgrund von Popularität, vorhandenem Expertenwissen innerhalb der ORDIX AG sowie der freien Verfügbarkeit der
Technologien getroffen. So sind alle abgebildeten Technologien in Inhalten der ORDIX Seminare vertreten.

Vorverarbeitung von Wetterdaten
Die Evaluation der verschiedenen Tools erfolgte anhand der Vorverarbeitung von Wetterdaten. Diese frei verfügbaren Daten des Deutschen Wetterdienstes werden zudem in unseren Hadoop und NoSQL-Schulungen als Beispielsdatensätze genutzt. Dabei durchlaufen die Rohdaten die Prozessschritte des Data Engineerings, um schließlich in ein definiertes Zielformat überführt zu werden. Anschließend können diese vorverarbeiteten Daten als Beispieldaten für unsere Schulungen dienen oder aber als Input für verschiedene Modelle im Machine Learning. Somit habe ich mit allen Tools den gleichen Vorverarbeitungsprozess von Wetterdaten durchgearbeitet und konnte daraus jeweilige Vor- und Nachteile ableiten.
Es folgt eine kurze Beschreibung der einzelnen Arbeitsschritte des Data Engineerings. Für eine detaillierte Beschreibung weise ich auf meinen Blogartikel: "Ein Einstieg in die Data Science Pipeline - Meine zweite Praxisphase" hin. Die Wetterdaten wurden im ersten Arbeitsschritt, der Data Collection, aus verschiedenen Formaten ausgelesen, sodass sie weiter verarbeitet werden können. Im nächsten Schritt, der Data Exploration, wurden Möglichkeiten zur Erkundung der Daten untersucht, welche dazu dienen, Wissen über die Datenbasis aufzubauen.
Daraufhin werden im Data Cleaning fehlerhafte Daten lokalisiert und behandelt. Abschließend können weitere Transformationen oder Anreicherungen im Schritt der Data Transformation durchgeführt werden.
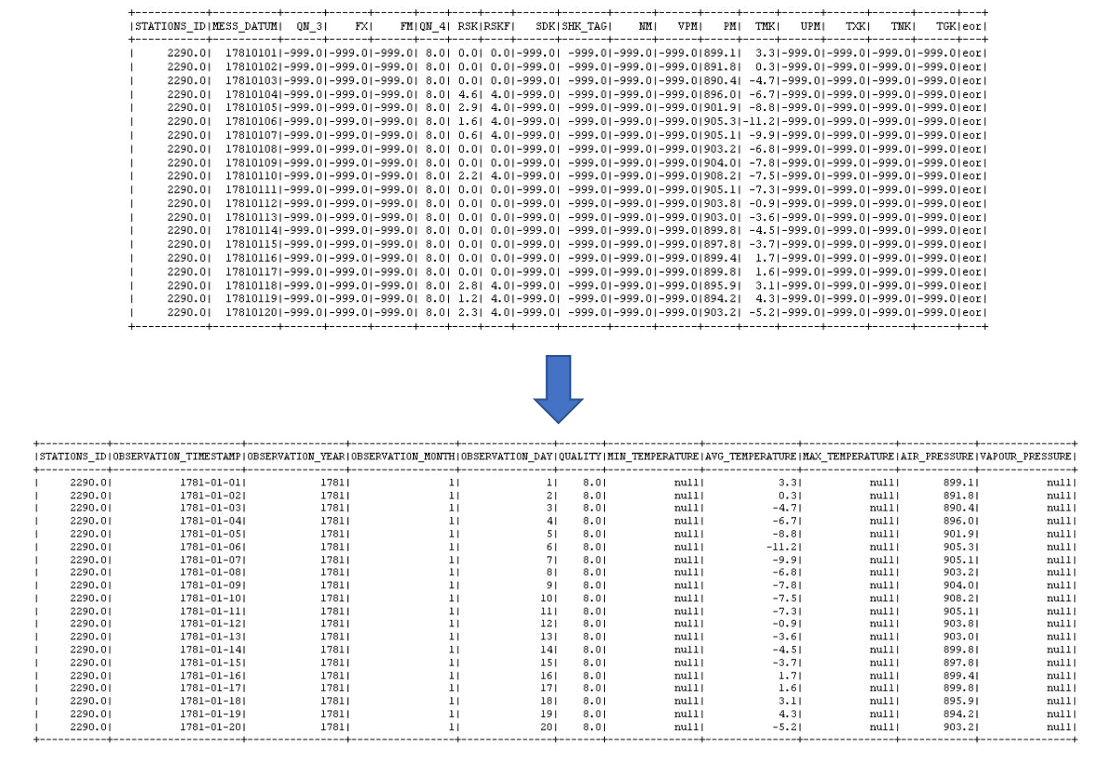
In der unteren Abbildung wird die Ausgangslage und das Zielformat der Wetterdaten abgebildet. Im Zuge dessen wurde die Spaltenanzahl reduziert, die Spaltennamen und -inhalte angepasst sowie fehlerhafte bzw. nicht vorhandene Werte durch "null" ersetzt. Natürlich ist ein Ersetzen durch "null" nicht immer sinnvoll, der Einfachheit halber wurde dies jedoch im Showcase als Teilschritt des Data Cleanings festgelegt.
Tools
Die Arbeitsschritte des Data Engineerings weisen Parallelen zum klassischen ETL-Prozess aus dem Bereich des Datawarehousing auf, daher wurde das ETL-Tool Talend in meiner Evaluation miteinbezogen. Das Akronym ETL steht dabei für Extract, dem Extrahieren von Daten aus verschiedenen Datenquellen ,Transform, der Verarbeitung der Daten und Load, dem Einlesen der Daten auf ein Zielsystem. Weiterhin ist zu betonen, dass eine Vielzahl an ETL-Tools auf dem Markt existieren. Einen Überblick im "ETL-Tool-Jungle" bietet dieser Blogartikel, welcher die Thematik ausführlich beleuchtet. Zudem wird hier der ORDIX ETL-O-MAT als softwarebasierte Entscheidungshilfe für die ETL-Toolauswahl vorgestellt.
Talend Open Studio for Data Integration
Talend Open Studio for Data Integration bringt die typischen Vorteile eines ETL-Tools mit sich. Dazu zählt vor allem die einfache Handhabung, welche den Programmieraufwand auf ein Minimum reduziert. Via Drag and Drop können einzelne Komponenten in der GUI zu einem Job zusammengestellt werden. Grundlegende Java Kenntnisse sind jedoch von Vorteil, da das Tool Java Code generiert. Eine kurze Einarbeitungsphase genügte, um die verschiedenen Schritte des Data Engineerings für das Anwendungsbeispiel zügig durchzuarbeiten.
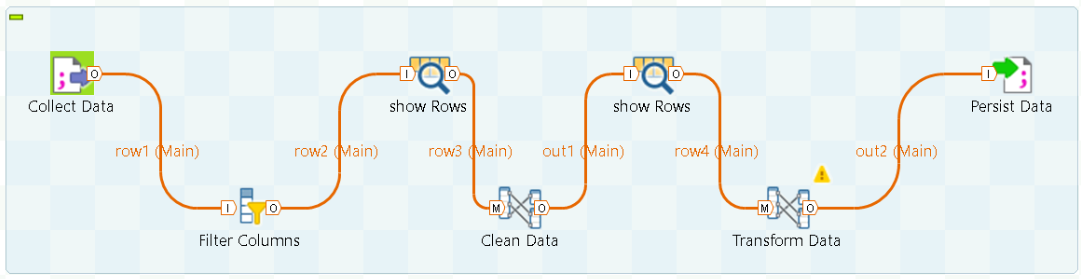
Die obige Abbildung zeigt wie die Vorverarbeitung von Wetterdaten als Job in Talend umgesetzt und zugleich visualisiert wurde. Zu Beginn wurde eine Semicolon-separierte Datei eingelesen, welche die zu verarbeiteten Wetterdaten enthält. Daraufhin wurden mittels tFilterColumns-Komponente nicht benötigte Spalten, durch Definition eines Schemas, aussortiert. Optional können die Zwischenergebnisse wie in diesem Beispiel mittels tLogRow-Komponente betrachtet werden. Die darauf folgenden tMap-Komponenten verarbeiten die Daten, um schließlich das
gewünschte Zielformat zu erhalten. Anschließend wird das Ergebnis des Jobs wiederum in einer gesonderten Datei persistiert.
Anzumerken ist, dass dies nur einen sehr simplen Job in Talend darstellt und weitaus komplexere Jobs erzeugt werden könnten. Ferner existiert eine umfangreiche Auswahl an Komponenten und Datensenken, welche zur Verarbeitung und Extraktion bzw. Persistierung der Daten verwendet werden kann.
Talend Open Studio for Big Data
Ein weiteres Talend-Produkt stellt Talend Open Studio for Big Data dar. Dieses ist, wie der Name schon erahnen lässt, auf Big-Data-Technologien ausgerichtet, welche vor allem dem Hadoop-Ecosystem zuzuschreiben sind und sich im erweiterten Komponentenportfolio widerspiegelt. Dabei wird MapReduce-Code erzeugt, der für verteilte Systeme geeignet ist. Tatsächlich können via Talend auch Spark-Jobs erzeugt werden. Möchte man Spark-Jobs verwenden, welche wesentlich performanter als MapReduce-Jobs sind, wird dies jedoch nur durch proprietäre Softwareprodukte aus dem Hause Talend ermöglicht.
Pandas und Spark
Im Gegensatz zu üblichen ETL-Tools werden alle Data Engineering Schritte nun unter Nutzung von Jupyter Notebook als IDE selbst entwickelt. Pandas ist eine Open-Source Python-Bibliothek, die im Data-Science-Umfeld weit verbreitet ist und für die Datenmanipulation sowie -analyse entwickelt wurde. Das Wetterdatenbeispiel konnte mittels Pandas leicht bewältigt werden. Zudem zeichnet sich Pandas in Kombination mit Bibliotheken zur Visualisierung hervorragend für die Data Exploration aus.
Bei Datenmengen, die größer als der Arbeitsspeicher sind, stößt Pandas jedoch an seine Grenzen. Hier kommt PySpark ins Spiel. PySpark ermöglicht die Nutzung von Python-APIs für Apache Spark, einem Framework für Cluster Computing, welches hervorragend für Big-Data-Analysen und -Verarbeitungen geeignet ist. Für tiefere Einblicke in die Thematik PySpark ist folgende Blogartikelreihe mit dem Namen "(PySpark) on YARN" zu empfehlen sowie dieser Blogartikel über Pyspark in Verbindung mit Hadoop und dem Paket- und Umgebungsmanager Conda.
Im Folgenden werden Auszüge des PySpark-Codes für die Vorverarbeitung der Wetterdaten vorgestellt, dabei wurde Pandas für die Data Exploration verwendet. Nachdem die Wetterdaten via Web-Scraping in das HDFS (Hadoop File System) geladen wurden, wurden die Daten mittels spark.read.csv() als PySpark-Dataframe eingelesen. Dort können neben dem Pfad optionale Parameter wie Header und Schema festgelegt werden. Beim Einlesen der Daten empfiehlt es sich, ein Schema selbst zu definieren, da die automatische Schemaerfassung via Spark bei größeren Datensätzen zu Performance-Einbußen führen kann. Eine Möglichkeit ist die Schemadefinition mittels StructType & StructField, wie es im Code-Beispiel angewandt wurde.
# Data Extraction
# Define schema and filepath
weather_data_path='/user/ordix/datasets/extracted_data/*.txt'
weather_data_schema = StructType([StructField('STATIONS_ID',DoubleType(),True),
StructField('MESS_DATUM',StringType(),True),
StructField('QN_3',DoubleType(),True),
StructField(' FX',DoubleType(),True),
StructField(' FM',DoubleType(),True),
StructField('QN_4',DoubleType(),True),
StructField(' RSK',DoubleType(),True),
StructField('RSKF',DoubleType(),True),
StructField(' SDK',DoubleType(),True),
StructField('SHK_TAG',DoubleType(),True),
StructField(' NM',DoubleType(),True),
StructField(' VPM',DoubleType(),True),
StructField(' PM',DoubleType(),True),
StructField(' TMK',DoubleType(),True),
StructField(' UPM',DoubleType(),True),
StructField(' TXK',DoubleType(),True),
StructField(' TNK',DoubleType(),True),
StructField(' TGK',DoubleType(),True),
StructField('eor',StringType(),True)])
# Read data of all stations into one dataframe
df = spark.read.csv(weather_data_path,
header=True,
sep = ";",
schema=weather_data_schema)
Da PySpark bislang keine Plotting-Funktionalität bereitstellt, bietet es sich an, die Data Exploration mittels Pandas auf einem Sample eines PySpark Dataframes durchzuführen. In beiden Tools werden Dataframes als Datenstrukturen verwendet, um tabellarische Daten zu manipulieren. Es ist möglich PySpark-Dataframes in Pandas-Dataframes umzuwandeln, so dass zwischen Pandas und PySpark im Code einfach hin und her gewechselt werden kann. Dies kann mit der Funktion toPandas umgesetzt werden, wie es im folgenden Code-Snippet beispielhaft gezeigt wird. So können mithilfe von Pandas Plotting-Funktionalität Histogramme zur Visualisierung und Analyse des Wertebereichs verschiedenen Spalten generiert werden.
# Data Exploration example # convert Sample of a Pyspark-Dataframe to Pandas-Dataframe and visualize as histrogram df.sample(False,0.1).toPandas().hist(figsize=(20,10))
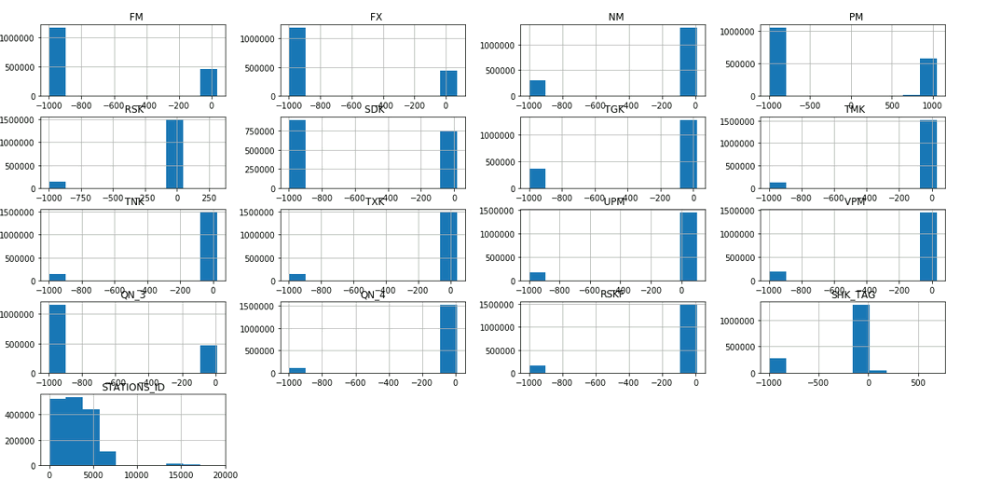
Nachdem ein Verständnis über die Struktur und den Inhalt der eingelesen Daten mithilfe von Pandas aufgebaut wurde, können die Wetterdaten mittels PySpark gesäubert werden. Im Data Cleansing wurden nicht benötigte Spalten entfernt, deskriptivere Spaltennamen vergeben und fehlende Werte durch None ersetzt. Dabei hat der Deutsche Wetterdienst fehlende Werte in den Rohdaten mit dem Wert -999 markiert, was aus der Data Exploration abgeleitet werden konnte.
# Data Cleansing
# Delete Whitespaces in Header
new_column_name_list= list(map(lambda x: x.strip(), df.columns))
df = df.toDF(*new_column_name_list)
# Drop unsued columns
columns_to_drop = ['QN_3', #QN_3 Qualitätsniveau
'FX', #Tagesmaximum Windspitze m/s
'FM', #Tagesmittel Windgeschwindigkeit m/s
'RSK', #tägliche Niederschlagshöhe mm
'RSKF', #Niederschlagsform
'SDK', #tägliche Sonnenscheindauer
'SHK_TAG',#Tageswert Schneehöhe
'NM', #Tagesmittel des Bedeckungsgrades
'UPM', #Tagesmittel der Relativen Feuchte %
'TGK', #Minimum der Lufttemp. am °C Erdboden in 5cm Höhe
'eor', #Ende data record
]
df = df.drop(*columns_to_drop)
# Rename Columns
df =df.withColumnRenamed('MESS_DATUM', 'OBSERVATION_TIMESTAMP'). \
withColumnRenamed('QN_4', 'QUALITY'). \
withColumnRenamed('VPM', 'VAPOUR_PRESSURE'). \
withColumnRenamed('PM', 'AIR_PRESSURE'). \
withColumnRenamed('TMK', 'AVG_TEMPERATURE'). \
withColumnRenamed('TXK', 'MAX_TEMPERATURE'). \
withColumnRenamed('TNK', 'MIN_TEMPERATURE')
# Replace Missing Values (marked by -999) with None
df = df.na.replace(-999.0,None)
Zuletzt wurde der Dataframe in der Data Transformation mit weiteren Spalten angereichert, welche aus dem Beobachtungsdatum abgeleitet wurden. Nachdem die Spaltenreihenfolge angepasst wurde, liegt das Dataframe im gewünschten Zielformat vor. Abschließend wurde das Dataframe mittels DataFrame.write im HDFS als CSV-File persistiert.
# Data Transformation and Persistance
# Convert Observation_timestamp from string to datetype
df = df.withColumn('OBSERVATION_TIMESTAMP',to_date(df.OBSERVATION_TIMESTAMP,
'yyyyMMdd').alias('OBSERVATION_TIMESTAMP'))
# Split observation_timestamp into year, month and day column
df = df.withColumn('OBSERVATION_DAY',dayofmonth('OBSERVATION_TIMESTAMP'))
df = df.withColumn('OBSERVATION_MONTH',month('OBSERVATION_TIMESTAMP'))
df = df.withColumn('OBSERVATION_YEAR',year('OBSERVATION_TIMESTAMP'))
# Rearrange columns
df = df.select(
['STATIONS_ID',
'OBSERVATION_TIMESTAMP',
'OBSERVATION_YEAR',
'OBSERVATION_MONTH',
'OBSERVATION_DAY',
'QUALITY',
'MIN_TEMPERATURE',
'AVG_TEMPERATURE',
'MAX_TEMPERATURE',
'AIR_PRESSURE',
'VAPOUR_PRESSURE',
]
)
# Persist dataframe as csv-file
df.write.format("csv").mode("overwrite").save("/user/rho/datasets/transformed_dat
a")
Die PySpark Syntax ist an die von Pandas angelehnt, sodass sich der Code des Datapreprocessing von Pandas und Pyspark nur geringfügig unterscheidet. Daher wurde hier nur eine Kombination zwischen Pandas und PySpark vorgestellt. Ein weiterer Vorteil der Nutzung von PySpark ist die Möglichkeit in späteren Schritten der Data Science Pipeline auf die SparkML, also der Machine-Learning-Funktionsbibliothek von Spark, zurückzugreifen.
Apache NiFi
Apache NiFi ist ein Open Source Tool, welches den Datenfluss zwischen verschiedenen Systemen automatisieren kann. In NiFis browserbasierter GUI kann ein DataFlow via Drag-and-Drop mittels vorgefertigter Prozessoren sehr schnell umgesetzt und zugleich visualisiert werden. Wie man Daten mit Apache NiFi migrieren kann, können Sie hier nachlesen. Einen Überblick der GUI bietet die folgende Abbildung. Dort ist der Dataflow für das vorgestellte Wetterdaten-Szenario dargestellt.
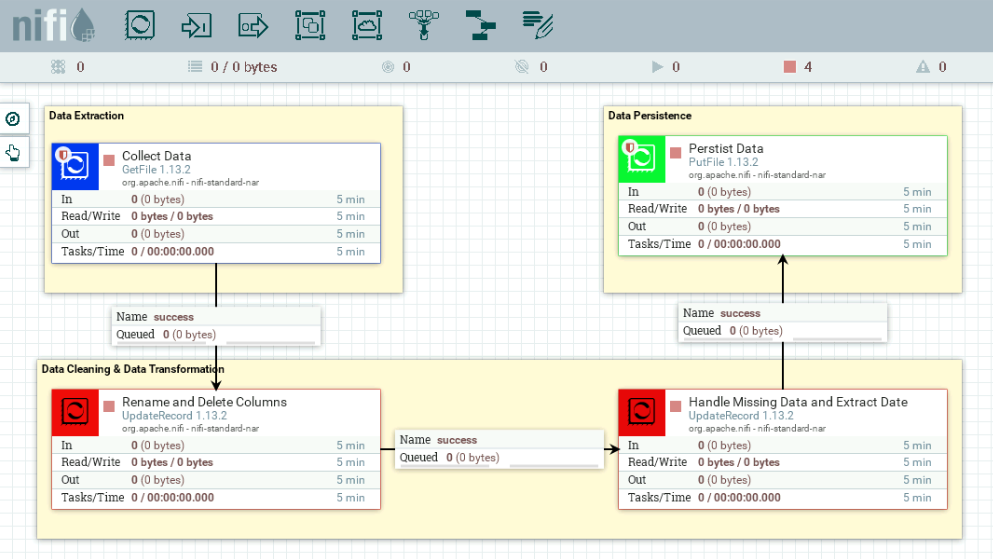
Im abgebildeten Dataflow werden zuerst die Wetterdaten in Form von Semicolon-separierten Textdateien mittels GetFile-Prozessor eingelesen. Alle eingelesenen Daten werden in NiFi durch sog. FlowFiles repräsentiert, welche aus den zwei Hauptbestandteilen 'content' und 'attributes' bestehen. 'Content' bezieht sich dabei auf die Inhalte der eingelesenen Daten und 'attributes' repräsentiert die Metadaten. Falls das Einlesen erfolgreich war, werden die FlowFiles daraufhin an den nächsten Prozessor weitergeleitet. In den beiden UpdateRecord-Prozessoren werden die FlowFiles mittels der NiFi-Expression Language ins Zielformat überführt. Ferner wurden Schemata für die UpdateRecord-Prozessoren definiert, um Input und Output zu spezifizieren. Letztlich werden die Files an einem anderen Ort im Dateiverzeichnis, durch Verwendung des PutFile-Prozessors, abgelegt.
Im Vergleich zu den anderen vorgestellten Tools ist das Data Cleaning und die Data Transformation in NiFi weniger intuitiv gestaltet. Jedoch ist die NiFi-Dokumentation sehr ausführlich und das Daten Einlesen sowie - Persistieren deutlich simpler gestaltet. Folglich kann Apache NiFi ebenfalls als Data Engineering Tool verwendet werden, ist jedoch mit etwas mehr Entwicklungsaufwand auf Seiten der Transformationsschritte verbunden. NiFi kann besonders in Kombination mit anderen Tools wie Spark Streaming den Data Engineering Prozess unterstützen, indem es den DataFlow automatisiert und mittels Spark die Daten verarbeitet werden. Die wohl größte Stärke NiFis stellt jedoch dessen Performance dar. Dies wird besonders dann ersichtlich, wenn NiFi im Cluster arbeitet und Daten im GB-Bereich transferiert werden.
Persönliches Fazit
Wie im Artikel ersichtlich wurde, existieren viele Tools welche sich für die Arbeitsschritte des Data Engineerings eignen. So können auch klassische ETL-Tools, welche evtl. bereits in einem Unternehmen im Einsatz sind, genutzt werden, um Daten für das Maschinelle Lernen vorzuverarbeiten und bereitzustellen.
Typischerweise werden jedoch eine Kombination verschiedener Pythonbibliotheken bevorzugt, da diese viel Freiraum zum Experimentieren mit den Daten bieten und im explorativen Bereich überzeugen. Bei den vorgefertigten Bausteinen/Prozessoren der ETL-Tools ist dies nur bedingt möglich. Zudem können nachträgliche Änderungen eines Jobs bei graphischen ETL-Tools sehr zeitintensiv sein. Demgegenüber ist die Wartbarkeit codebasierter Lösungen wie PySpark und Pandas mittels IDE einfacher und effizienter möglich.
Mich persönlich hat die Kombination zwischen PySpark und weiteren Pythonbibliotheken aus dem Bereich der Data Science am meisten überzeugt. So konnte sehr einfach durch ähnliche Syntax zwischen der Spark-API und Pandas hin und her gewechselt werden. Damit konnten PySparks Schwächen elegant durch Pandas Stärken ergänzt werden und vice versa. PySparks Unzulänglichkeit im explorativen Bereich konnte so durch Pandas bestens ausgeglichen werden. Die ORDIX AG bietet für alle im Blogartikel genannten Technologien (und natürlich auch noch viele weitere) Weiterbildungsmöglichkeiten an. Falls Sie für ihre Problemstellung eine individuelle Beratung zur Technologieauswahl im Bereich Data Science benötigen, sprechen Sie uns gerne an.
Sie haben Interesse an einer Weiterbildung oder Fragen zum Thema? Sprechen Sie uns an oder besuchen Sie einen unserer Kurse aus unserem Seminarshop:
Zu unseren Seminaren

MeetUp: Apache NiFi Germany
Tipp: Für den fachlichen Austausch empfehlen wir außerdem die MeetUp-Gruppe „Apache NiFi Germany“:
Kommentare