
Wenn KI den Spickzettel zückt (2/2): Schritt für Schritt zum RAG-System
Im ersten Teil dieser Blogreihe haben wir Retrieval Augmented Generation (RAG) eingeführt und erklärt, wie es große Sprachmodelle mit aktuellem Wissen erweitert. Jetzt geht es an die Praxis: In diesem Beitrag zeigen wir euch, wie ihr ein eigenes RAG-System umsetzen könnt. Schritt für Schritt erklären wir die notwendigen Komponenten und liefern Codebeispiele mit der Python-Library LangChain.
Anwendungsbeispiel: Ein Kundensupport-Chatbot für Seminarangebote
Stellt euch vor, Lisa hat das Seminar „Machine Learning Basics" bei ORDIX gebucht und möchte kurz vor dem Seminarbeginn noch ein paar Details klären: Wo genau findet das Seminar statt? Kann ich mein E-Auto vor Ort aufladen? Was muss ich eigentlich mitbringen? Statt umständlich auf der Seminar-Website nach diesen Informationen zu suchen, wäre es doch für Lisa viel einfacher, einen Chatbot zu nutzen, der diese Fragen schnell und unkompliziert beantwortet. Genau so einen Chatbot entwickeln wir im Folgenden Schritt für Schritt. Der Chatbot greift auf die aktuellen Seminarinformationen zu und kann dadurch kontextbezogene, präzise Antworten liefern – ganz ohne manuelle Recherche.
Aufbau eines RAG-Systems
Für die folgenden Codebeispiele nutzen wir LangChain als Framework. LangChain ist ein Open-Source-Toolkit für die Entwicklung von Anwendungen, die auf großen Sprachmodellen (LLMs) basieren, insbesondere auch im Bereich RAG. Es bietet eine Vielzahl an Modulen für die nahtlose Integration von Sprachmodellen, Vektordatenbanken und Retrieval-Mechanismen.
Unabhängig vom gewählten Framework – sei es LangChain, Haystack oder LlamaIndex – bleiben die Grundprinzipien von RAG gleich, sodass sich die nachfolgenden Schritte in sehr ähnlicher Weise in jeder Implementierung wiederfinden.
Schritt 1: Datenvorverarbeitung
Bevor wir mit dem Retrieval-Prozess beginnen, müssen wir geeignete Datenquellen identifizieren und die Dokumente in eine verarbeitbare Form bringen. Die benötigten Informationen können aus unterschiedlichen Quellen stammen – etwa Datenbanken, APIs oder strukturierten Dateien. In unserem Beispiel nutzen wir eine YAML-Datei, die häufige Fragen und Antworten zu den Seminaren enthält.
Ein beispielhafter Auszug aus einer solchen YAML-Datei könnte folgendermaßen aussehen:
faq:
- question: Wie lautet die Adresse des Seminarzentrums in Wiesbaden?
answer: >
Die Adresse unseres Wiesbadener Seminarzentrums lautet:
Kreuzberger Ring 13, 65205 Wiesbaden, 2. OG.
- question: Gibt es E-Ladestationen am Seminarzentrum?
answer: >
Am Seminarzentrum stehen vier Elektro-Ladestationen zur
Verfügung, die Sie kostenlos nutzen können.
Damit unser RAG-System die Seminarinformationen durchsuchen kann, wandeln wir die Daten in ein passendes Format um. LangChain verwendet hierfür das Document-Format, das es ermöglicht Inhalte mit Metadaten zu verknüpfen. Jedes LangChain-Dokument enthält:
- page_content: Dieser Text wird verwendet, um die Vektorrepräsentation (Embedding) zu erstellen.
- metadata: Zusätzliche Metadaten, auf die bei späteren Abrufen des Dokuments zugegriffen werden kann.
import yaml
with open("seminar_faq.yaml", "r", encoding="utf-8") as file:
faq_data = yaml.safe_load(file)
from langchain_core.documents import Document
documents = [ Document(page_content=entry["question"], metadata={"answer": entry["answer"]}) for entry in faq_data["faq"] ]
Schritt 2: Embeddings erstellen
Als Nächstes wandeln wir die Texte in numerische Vektoren um und speichern sie in einer Vektordatenbank, um eine effiziente Suche zu ermöglichen.
Für die Umwandlung benötigen wir ein Embedding-Modell. In unserem Fall greifen wir auf ein frei verfügbares Modell von HuggingFace zurück, das lokal ausgeführt werden kann. Dieses Modell wandelt jeden Eingabetext in einen 384-dimensionalen Vektor um, der die semantische Bedeutung des Textes widerspiegelt.
Als Vektordatenbank nutzen wir ChromaDB. Sie bietet eine einfache Integration in LangChain. Mit der from_documents () -Methode können wir direkt eine Vektordatenbank aus den vorbereiteten Dokumenten des vorherigen Schrittes erstellen und die Vektoren abspeichern.
from langchain_huggingface import HuggingFaceEmbeddings from langchain_chroma import Chroma embeddings = HuggingFaceEmbeddings(model_name="intfloat/multilingual-e5-small") vector_store = Chroma.from_documents( documents, collection_name="seminar_faq", persist_directory="./chroma_db", embedding=embeddings )
Schritt 3: Retrieval-Mechanismus implementieren
Nachdem die Texte in Vektoren umgewandelt und in der Datenbank gespeichert wurden, müssen wir nun einen Mechanismus schaffen, um relevante Dokumente für eine Nutzeranfrage zu finden.
Dafür nutzen wir einen Retriever, der die Vektordatenbank nach den am besten passenden Einträgen durchsucht. LangChain bietet hier eine standardisierte Schnittstelle, um verschiedene Vektordatenbanken auf die gleiche Weise abzufragen:
retriever = vector_store.as_retriever(search_kwargs={"k": 1})
doc = retriever.invoke("Wie lautet die Adresse für mein Seminar? ")
Dabei läuft der Vorgang folgendermaßen ab:
- Da
k=1gesetzt ist, gibt der Retriever nur den relevantesten Treffer zurück.
- Die Nutzeranfrage wird in einen Vektor umgewandelt (mithilfe desselben Embedding-Modells wie zuvor).
- Die Vektordatenbank sucht nach den ähnlichsten gespeicherten Vektoren und liefert das passendste Dokument zurück.
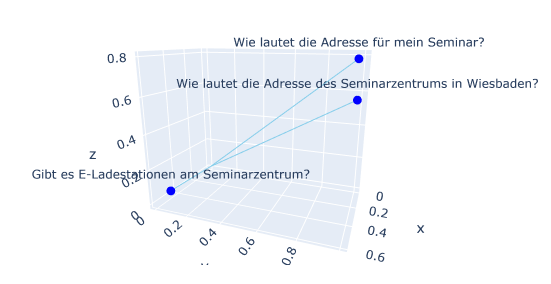
Die Suche nach den ähnlichsten Dokumenten kann sich anhand des Bildes vorgestellt werden. Stellen wir uns vor, dass wir sowohl die Dokumente als auch unsere Anfrage als Vektoren in ein Koordinatensystem eintragen. Zur besseren Veranschaulichung gehen wir hier vereinfacht von drei Dimensionen aus — in der Realität können es jedoch hunderte oder sogar tausende Dimensionen sein. Jeder blaue Punkt im Bild repräsentiert einen dieser Vektoren, also ein Dokument. Auch unsere Anfrage wird in diesen gemeinsamen Raum übertragen. Anschließend wird berechnet, welche Dokumente den geringsten Abstand zum Anfragevektor haben. Je kleiner dieser Abstand, desto größer die semantische Ähnlichkeit. In unserem Beispiel liegt der Vektor des Dokuments „Wie lautet die Adresse für mein Seminar?" am nächsten an der Anfrage „Wo findet mein Seminar statt?". Daher wird dieses Dokument als Ergebnis zurückgegeben.
Außerdem definieren wir uns noch eine Hilfsfunktion, um aus dem abgerufenen Dokument die Metadaten zu extrahieren. Diese stellen wir später dem Sprachmodell bei der Generierung zur Verfügung.
def extract_metadata(docs):
return docs[0].metadata.get("answer", "Keine Antwort gefunden.")
Diese Funktion nimmt die Liste der gefundenen Dokumente (enthält in unserem Beispiel nur ein Dokument) und gibt den gespeicherten Antworttext zurück. Falls kein Dokument gefunden wird, wird eine Standardnachricht („Keine Antwort gefunden") ausgegeben.
Schritt 4: Generationsmodell integrieren
Nachdem wir die relevantesten Dokumente gefunden haben, müssen wir eine natürliche und verständliche Antwort generieren. Hierfür nutzen wir ein Large Language Model (LLM), das auf Basis des bereitgestellten Kontexts eine menschenähnliche Antwort formuliert.
Um das Modell effizient zu steuern, erstellen wir eine Prompt-Vorlage, in die später automatisch die relevante Information aus der Datenbank und die Nutzerfrage eingefügt wird.
from langchain_core.prompts import PromptTemplate
prompt = PromptTemplate(
input_variables=["context", "question"],
template="""
Du bist ein hilfreicher Assistent. Beantworte die folgende Frage auf Basis des angegebenen Kontexts.
Kontext:
{context}
Frage:
{question}
Antwort:
"""
)
Wir verwenden hier das Modell GPT-4o-mini von OpenAI, das als Closed-Source-Lösung über eine API von OpenAI bereitgestellt wird. Je nach vorhandener IT-Infrastruktur, oder Cloud-Ressourcen können OpenSource-Modelle wie Llama oder Mistral genutzt werden, um bei sensiblen Daten den Anforderungen an den Datenschutz gerecht zu werden.
from langchain_openai import ChatOpenAI llm = ChatOpenAI(model_name="gpt-4o-mini", api_key='your-openai-api-key')
Schritt 5: Ausführung der RAG-Pipeline
Nun setzen wir alle vorherigen Schritte zusammen, um eine funktionierende RAG-Pipeline zu erhalten. Die Pipeline besteht aus mehreren Verarbeitungsschritten, die nahtlos miteinander verbunden werden:
- Eingabe der Nutzeranfrage: Der/die Nutzer:in stellt eine Frage, die das System beantworten soll.
- Abruf relevanter Dokumente: Die Anfrage wird in einen Vektor umgewandelt und mit den gespeicherten Vektoren in der Vektordatenbank verglichen. Die ähnlichsten Dokumente werden abgerufen.
- Extraktion der relevanten Informationen: Die abgerufenen Dokumente enthalten zusätzliche Metadaten, z. B. Antworten aus der Wissensdatenbank. Diese Metadaten werden extrahiert und für die nächste Phase bereitgestellt.
- Generierung der Antwort: Das Sprachmodell erhält den abgerufenen Kontext sowie die ursprüngliche Frage und generiert darauf basierend eine präzise Antwort.
- Ausgabe der Antwort: Die generierte Antwort wird an den/die Nutzer:in zurückgegeben.
In LangChain setzen wir diese Schritte in einer sogenannten „Chain" um, die alle Komponenten miteinander verknüpft und den gesamten Prozess automatisiert:
from langchain_core.runnables.passthrough import RunnablePassthrough
rag_chain = {
"context": retriever | extract_metadata,
"question": RunnablePassthrough()
} | prompt | llm
rag_chain.invoke("Wie lautet die Adresse für mein Seminar?")
Bei Aufruf erhalten wir folgende Ausgabe des Sprachmodells:
AIMessage(content='Die Adresse für dein Seminar lautet: Kreuzberger Ring 13, 65205 Wiesbaden, 2. OG.')
Das ist die Antwort, die unsere Seminarteilnehmerin Lisa haben wollte, ohne lange suchen zu müssen. Der Chatbot durchsucht automatisch die FAQs, findet die relevante Information und gibt sie ansprechend aus.
Fortgeschrittene Methoden
Um unser System weiter zu optimieren, gibt es viele verschiedene Ansätze, dazu zählen:
- Hybrid-Retrieval: Hierbei wird die Vektorsuche mit einem klassischen Textsuchalgorithmus (beispielsweise BM25) kombiniert. So können beide Ansätze zusammenarbeiten, um bessere Ergebnisse zu liefern, die sowohl auf der Bedeutung von Wörtern als auch auf deren Häufigkeit basieren.
- Contextualized Retrieval: Dieser Ansatz berücksichtigt den Kontext, in dem eine Anfrage gestellt wird, um sicherzustellen, dass relevante Ergebnisse gefunden werden. So kann beispielsweise aus dem bisherigen Chatverlauf und der aktuellen Anfrage eine neue, optimierte Anfrage formuliert werden, welche die vorherige Konversation einbezieht. Besonders bei Chat-Anwendungen ist dies wichtig, wenn eine Folgefrage auf einem vorherigen Gespräch basiert.
- Self-RAG: Kombiniert Retrieval-Augmented Generation (RAG) mit einem Reflektions-Prozess, bei dem das Modell nach der Generierung einer Antwort diese eigenständig vor der Ausgabe prüft und optimiert, um z. B. die Relevanz sicherzustellen.
Fazit
Die Grundimplementierung eines RAG-Systems ist mit bestehenden Tools wie LangChain einfach umsetzbar. Die wahre Herausforderung liegt in der Optimierung und der Integration in bestehende Unternehmenssysteme. Für ein leistungsfähiges RAG-System sind nicht nur eine saubere technische Umsetzung und eine sorgfältige Auswahl relevanter Datenquellen entscheidend, sondern auch die präzise Abstimmung der Retrieval- und Generierungsprozesse sowie die Einhaltung von Datenschutz und Compliance-Richtlinien. Ergänzend können fortgeschrittene Ansätze wie Hybrid-Retrieval die Antwortqualität weiter steigern.
Dies führt zu der Frage, wie die Qualität von RAG-Systemen zuverlässig gemessen werden kann. Ein spannender Ansatz ist LLM-as-a-Judge – die Idee, KI-Modelle als Bewertungsinstanz einzusetzen. Wie das funktioniert und welche Chancen und Herausforderungen damit verbunden sind, beleuchten wir in einem der kommenden Blogartikel.
Wenn ihr nicht so lange warten möchtet, können wir euch den Blogartikel zu LangGraph empfehlen. LangGraph ist ein leistungsstarkes Framework zur Orchestrierung von KI-Workflows und damit auch für RAG-Systeme geeignet. Besonders bei der Umsetzung komplexer Abläufe wie Self-RAG hat es seine Stärken.
Falls ihr RAG in euren eigenen Workflows einsetzen möchtet, sprecht uns an – wir unterstützen euch gerne bei der Implementierung!
Seminarempfehlungen
GRUNDLAGEN MODERNER DATENNUTZUNG - DATA LITERACY DATA-LIT
Mehr erfahrenMACHINE LEARNING BASICS DB-AI-01
Mehr erfahrenJunior Consultant bei ORDIX
Kommentare