
Wurzeln schlagen oder Brücken bauen? Wie migriere ich meine Oracle Datenbank nach PostgreSQL?
Immer häufiger werden wir mit der Frage konfrontiert, wie und ob man eine Oracle Datenbank nach PostgreSQL migrieren kann. Diese Frage ist nicht immer einfach zu beantworten. Technisch ist dies natürlich möglich. Ob es allerdings auch aus betriebswirtschaftlichen Gründen (Aufwand der Migration vs. Kostenersparnis Oracle) sinnvoll ist, steht auf einem anderen Blatt.
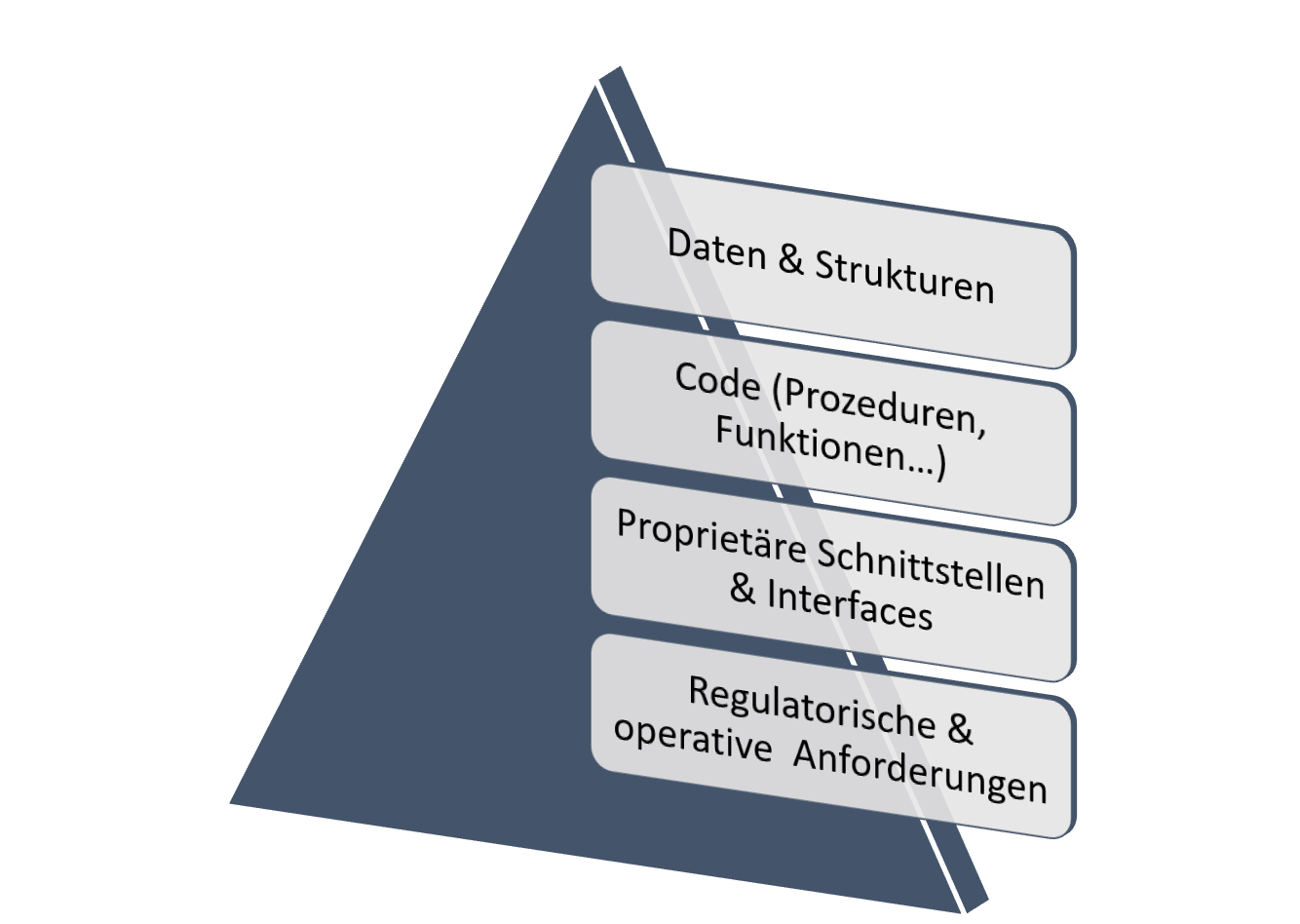
In diesem Beitrag soll es jedoch um den ersten Teil der Frage gehen. Dazu stellen wir Ihnen das GPL Tool ora2pg in einem einfachen Beispiel vor. Die komplette Dokumentationen mit allen Optionen und Facetten des Werkzeuges finden Sie hier: https://ora2pg.darold.net/documentation.html
Das Fundament: Die Installation von ora2pG
Bei dem Werkzeug ora2pg handelt es sich um eine Perl-Applikation, die sich dementsprechend einfach installieren lässt. Neben einer aktuellen Perl-Version, die auf den üblichen Linux-/Unix-Derivaten meist per Default installiert ist, benötigt die Applikation auch die notwendigen Treiber- und Client-Bibliotheken für den Zugriff auf die Oracle DB:
- DBD::Oracle; Perl Modul für den Oracle Zugriff
- Oracle (Instant) Client
Wer es sich an dieser Stelle einfach machen möchte, kann natürlich die Applikation auch auf dem Oracle Server installieren und die Oracle Perl Distribution verwenden. Dazu muss nur der Pfad so umgesetzt werden, dass diese Perl-Version auch gefunden wird.
bash> export $ORACLE_HOME/perl/bin:$PATH bash> type perl perl is hashed (/opt/oracle/product/18c/dbhomeXE/perl/bin/perl) bash> perl -e "use DBD::Oracle" && echo "Module exists"
Die Brückenpfeiler: Die Extraktion des Schemas & Daten
Vor einer Migration empfiehlt es sich, ein Projekt zu erzeugen. Generell sorgt dies dafür, dass alle Skripte und Konfigurationen für unsere Migration in einem Verzeichnis gekapselt werden.
bash> mkdir /home/oracle/hr_migration
bash> ora2pg --project_base /home/oracle/hr_migration --init_project hr_app
Creating project hr_app.
/home/oracle/hr_migration/hr_app/
schema/
dblinks/
directories/
functions/
...
tables/
...
views/
sources/
functions/
...
triggers/
types/
...
data/
config/
reports/
Generating generic configuration file
Creating script export_schema.sh to automate all exports.
Creating script import_all.sh to automate all imports.
Unterhalb dieser Dateistruktur befindet sich auch die Konfigurationsdatei. Hier lassen sich umfangreiche Einstellungen vornehmen. Unter anderem muss hier die DB-Verbindung (zu Oracle) definiert werden. Zusätzlich lassen sich beispielsweise alle möglichen Filter (z.B. für DB-Objektname und/oder -typen) aber auch andere Einstellungen (Character-Sets, Umgang mit Constraints, Parallelität, ...) festlegen.
Im Folgenden sehen Sie einige wenige Ausschnitte der Konfiguratio:
bash> vi /home/oracle/hr_migration/hr_app/config/ora2pg.conf ... # Set the Oracle home directory ORACLE_HOME /opt/oracle/product/18c/dbhomeXE # Set Oracle database connection (datasource, user, password) ORACLE_DSN dbi:Oracle:host=localhost;service_name=XEPDB1;port=1521 ORACLE_USER hr ORACLE_PWD hr ... # Export Oracle schema to PostgreSQL schema EXPORT_SCHEMA 1 # Oracle schema/owner to use SCHEMA hr
Oracle-kundige Leser werden gesehen haben, dass wir das Beispiel-Schema "hr" aus der Oracle Datenbank exportieren wollen. Es enthält einige Objekte (Tabellen, Views, Sequenzen, Trigger, Prozeduren, ...) und auch ein paar Datensätze. Wir exportieren dieses Schema aus einer pluggable Databases (XEPDB1) aus Oracle 18c Instanz mit dem Namen "XE".
Der Bauplan: Lohnt das überhaupt?
Mit der Extraktion des Schemas (und der Daten – es kann übrigens auch nur das Schema oder die Daten extrahiert werden), erstellt ora2pg einen übersichtlichen Report.
Unter anderem wird bestimmt, welche Objekte migriert werden und ob es beim Prozess zu Problemen und/oder Workarounds kommt. In dem Beispiel-Report ist u.a. zu sehen, dass es zahlreiche Synonyme gibt, die durch Views ersetzt werden sollen (dazu später mehr). Probleme werden mit Kosten gewichtet.
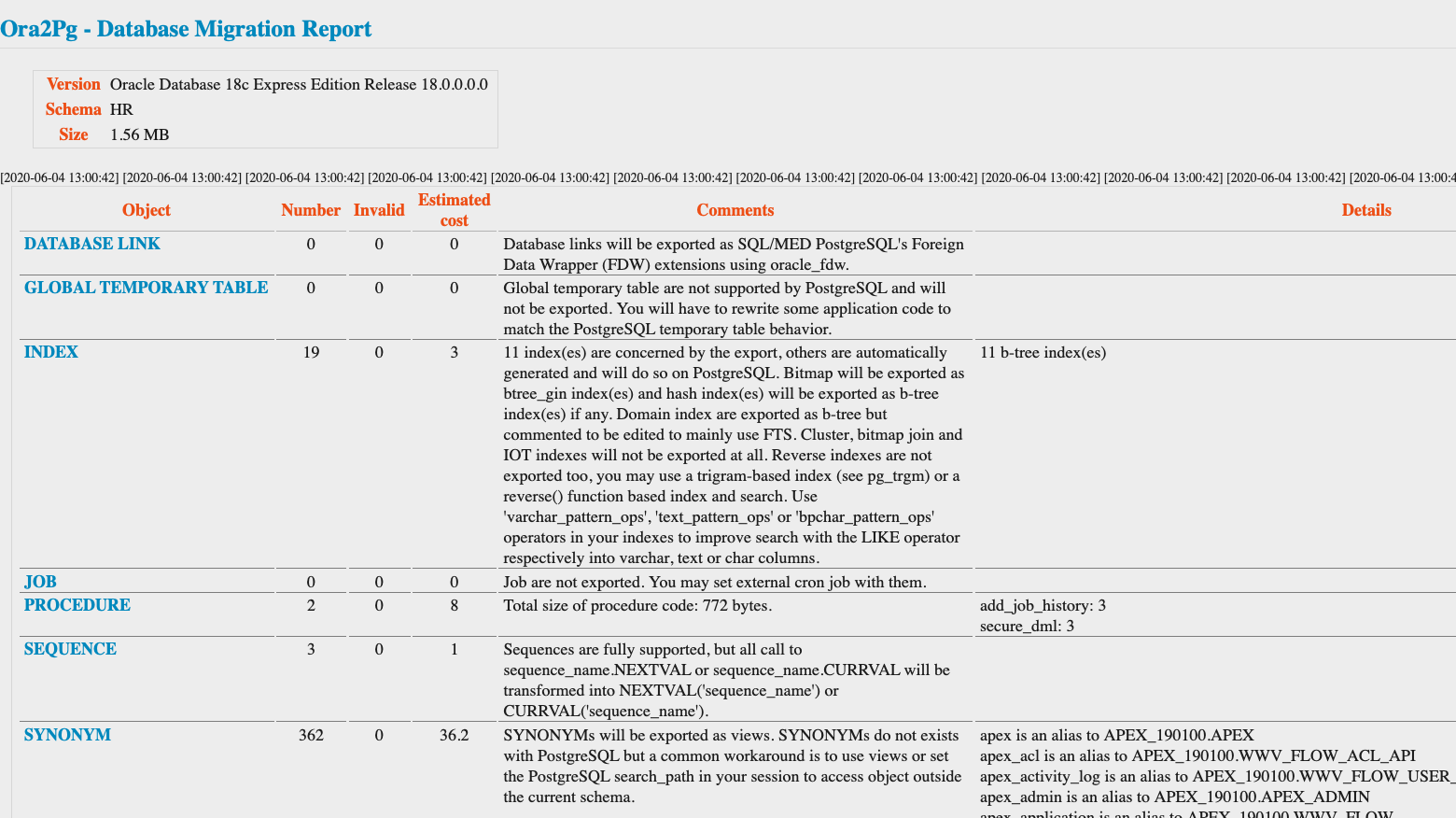
Am Ende des Reports ist zu sehen, mit welchen Problemen und Kosten bei der Migration (z.B. durch Nacharbeiten) zu rechnen ist. Natürlich ist dies nur ein grober Richtwert. Bei einer großen Anzahl von Oracle-Systemen, die migriert werden sollen, kann dies aber bereits ein erster Anhaltspunkt sein, wo sich die "Low-hanging Fruits" befinden.

In unserem einfachen Beispiel wird der Aufwand als "A-3" klassifiziert. Die Migration sollte damit weitestgehend automatisch ("A") und mit einem moderaten technischen Skill ("3") möglich sein.
Der Brückenschlag
Der Bau der eigentlichen Brücke besteht aus drei Teilen. Zunächst erfolgt der Export des Schemas. Dies geschieht über den unspektakulären folgenden Aufruf eines Kommandos (Ausgabe stark gekürzt):
bash> ./export_schema Running: ora2pg -p -t TABLE -o table.sql -b ./schema/tables -c ./config/ora2pg.conf [2020-06-04 13:00:42] Ora2Pg version: 20.0 [2020-06-04 13:00:42] Trying to connect to database: dbi:Oracle:host=localhost;service_name=XEPDB1;port=1521 [2020-06-04 13:00:42] Isolation level: SET TRANSACTION ISOLATION LEVEL SERIALIZABLE [2020-06-04 13:00:42] Looking forward functions declaration in schema HR. [2020-06-04 13:00:43] Retrieving table information... [2020-06-04 13:01:11] [1] Scanning table COUNTRIES (25 rows)... ... [2020-06-04 13:01:17] Dumping table COUNTRIES... . [2020-06-04 13:01:17] Dumping constraints to one separate file : CONSTRAINTS_table.sql [2020-06-04 13:01:17] Dumping foreign keys to one separate file : FKEYS_table.sql ... To extract data use the following command: ora2pg -t COPY -o data.sql -b ./data -c ./config/ora2pg.conf
Der zweite Teil besteht aus dem Export der Daten. Das Kommando wird vom vorherigen Befehl geliefert (Ausgabe stark gekürzt):
bash> ora2pg -t COPY -o data.sql -b ./data -c ./config/ora2pg.conf [2020-06-04 13:05:16] Ora2Pg version: 20.0 [2020-06-04 13:05:16] Trying to connect to database: dbi:Oracle:host=localhost;service_name=XEPDB1;port=1521 [2020-06-04 13:05:16] Isolation level: SET TRANSACTION ISOLATION LEVEL SERIALIZABLE [2020-06-04 13:05:16] Retrieving table information... [2020-06-04 13:05:43] [1] Scanning table COUNTRIES (25 rows)... ... [2020-06-04 13:06:08] Renaming temporary file ./data/tmp_REGIONS_data.sql into ./data/REGIONS_data.sql [2020-06-04 13:06:08] Total time to export data from 7 tables (0 partitions, 0 sub-partitions) and 215 total rows: 25 wallclock secs ( 0.11 usr + 0.05 sys = 0.16 CPU) [2020-06-04 13:06:08] Speed average: 8.60 rows/sec
Der dritte Teil besteht nun darin, die Daten (das Projekt-Verzeichnis) auf den PostgreSQL Server zu kopieren und zu laden. Dies passiert ebenfalls über ein Skript, welches von ora2pg generiert wurde.
# Daten wurden auf den PG Server bereits kopiert bash> cd /pg_import/hr_app bash> ls -l total 40 drwxr-xr-x 2 501 dialout 4096 Jun 4 12:57 config drwxr-xr-x 2 501 dialout 4096 Jun 4 13:06 data -rwx------ 1 501 dialout 2010 Jun 4 12:45 export_schema.sh -rwx------ 1 501 dialout 16061 Jun 4 12:45 import_all.sh drwxr-xr-x 2 501 dialout 4096 Jun 4 12:55 reports drwxr-xr-x 17 501 dialout 4096 Jun 4 12:45 schema drwxr-xr-x 10 501 dialout 4096 Jun 4 12:45 sources
Beim Import in den PostgreSQL-Server ist der DB-Name (-d), die Liste der zu ladenden Schemata (oder auch nur eines; -n) und der DB-Owner (-o) zu spezifizieren. Alle weiteren Parameter können dialogorientiert eingegeben werden (oder natürlich auch als Parameter; Ausgabe wieder stark gekürzt):
bash> ./import_all.sh -Upostgres -dhr -nhr -ohr Database owner hr already exists, skipping creation. Would you like to drop the database hr before recreate it? [y/N/q] y Running: dropdb -U postgres hr Running: createdb -U postgres -E UTF8 --owner hr hr Would you like to create schema hr in database hr? [y/N/q] y Running: psql -U hr -d hr -c "CREATE SCHEMA hr;" CREATE SCHEMA Would you like to change search_path of the database owner? [y/N/q] y Running: psql -U postgres -d hr -c "ALTER ROLE hr SET search_path TO hr,public;" ALTER ROLE Would you like to import TABLE from ./schema/tables/table.sql? [y/N/q] y Running: psql --single-transaction -U hr -d hr -f ./schema/tables/table.sql SET ALTER SCHEMA SET CREATE TABLE ... CREATE TABLE Would you like to import VIEW from ./schema/views/view.sql? [y/N/q] y Running: psql --single-transaction -U hr -d hr -f ./schema/views/view.sql SET ... ... Would you like to import SYNONYM from ./schema/synonyms/synonym.sql? [y/N/q] n Would you like to process indexes and constraints before loading data? [y/N/q] n Would you like to import data from ./data/data.sql? [y/N/q] y Running: psql -U hr -d hr -f ./data/data.sql SET BEGIN ALTER TABLE ... COMMIT Would you like to import indexes from ./schema/tables/INDEXES_table.sql? [y/N/q] y Running: psql -U hr -d hr -f ./schema/tables/INDEXES_table.sql ... CREATE INDEX Would you like to import constraints from ./schema/tables/CONSTRAINTS_table.sql? [y/N/q] y Running: psql -U hr -d hr -f ./schema/tables/CONSTRAINTS_table.sql
Auf zwei Besonderheiten soll bei diesem Import hingewiesen werden:
- Zum einen wurde auf den Import von Synonymen verzichtet, da PostgreSQL keine Synonyme unterstützt (das Tool legt als Workaround Views an). In unserem Beispiel wurden nur die üblichen Synonyme von Oracle APEX exportiert, die für die Anwendung keine Rolle spielen.
- Zum anderen wurden vor dem Laden der Daten die Constraints und Indizes deaktiviert. Die Daten werden nicht zwangsläufig gemäß der richtigen Reihenfolge (also erst die PK- und dann die FK-Datensätze) geladen). Bei aktivierten Constraints beim Import kann das zum Abbruch aufgrund der Verletzung der referentiellen Integrität führen. Die Constraints werden aber zum Schluss des Prozesses nachträglich aktiviert.
Fazit
Das Werkzeug ora2pg ist ein nützlicher Helfer bei der Migration von Datenbanken von Oracle (oder MySQL) zu PostgreSQL. Es hilft initial bei der Analyse der Quellsysteme und verschafft einen ersten (!) Eindruck darüber, wie aufwändig eine Migration wohl werden kann. Dies hilft gerade bei großen Landschaften, wo hunderte oder tausende von Systemen betrachtet werden sollen. Auch beim eigentlichen Prozess (Schema- und Datenmigration) kann ora2pg sinnvoll unterstützen. Eine Betrachtung von ora2pg lohnt sich auf jeden Fall, wenn man sich mit einem solchen Migrationsvorhaben beschäftigt.
Sie haben Fragen zu PostgreSQL oder anderen Datenbanken? Dann sprechen Sie uns an!
Principal Consultant bei ORDIX
Kommentare