
ksqlDB, the superpower in the Kafka universe - Part 2
KsqlDB is an event streaming database for building stream processing applications on top of Apache Kafka. In the previous article, ksqlDB was introduced and the benefits, and reasons for the existence of another solution within the Kafka universe to build stream processing applications were outlined. KsqlDB proposes a different approach to Kafka Streams.
This article will deepen the presentation and provide a detailed picture of ksqlDB architecture and concepts necessary for a better understanding. As with the first article, the goal is to provide an understanding of the differences between stream processing solutions within the Kafka ecosystem (Kafka Streams and ksqlDB).
This article is part of a three-part series. It is recommended to read the previous article before reading this one. At the end of this article, you should gain a better understanding of ksqlDB and the use cases and issues it aims to address.
ksqlDB architecture
ksqlDB provides an SQL-like interface to data streams, allowing for filtering, aggregations and even joins across data streams. ksqlDB uses Kafka as the storage engine and to work as the compute engine. A solution with ksqlDB can be considered as a simple two-tier architecture with a compute layer and a storage layer, ksqlDB and Kafka. Data is stored in Kafka and the processing of data happens in ksqlDB. Figure 1 displays this simple two-tier architecture. It is important to note that both layers and infrastructure can be elastically scaled independently of the other.
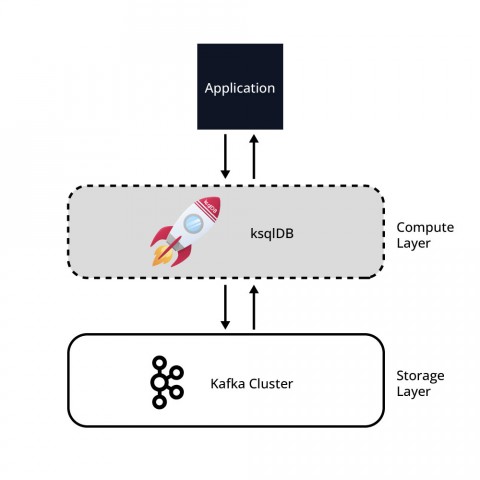
ksqlDB is made of four components divided into two main groups of components: ksqlDB server and ksqlDB clients: a SQL engine, a REST service, a command line interface and a user interface.
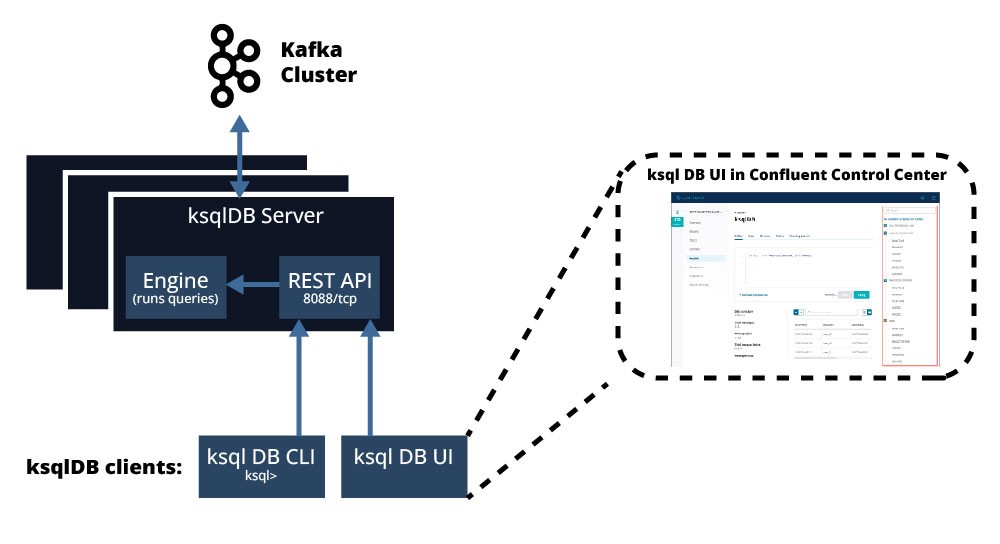
The Figure 2 taken from the official documentation, gives an overview of all these components
ksqlDB Server, made up of …
- SQL Engine
- und ksqlDB REST Service
- ksqlDB cli
- ksqlDB UI
Inside the ksqlDB Server
The ksqlDB server is responsible for running stream processing applications. When you deploy your ksqlDB application, it runs on ksqlDB Server instances that are independent, fault-tolerant, and scalable.
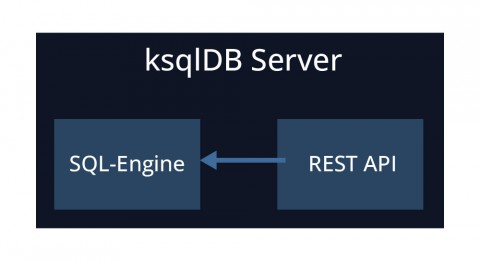
A ksqlDB server is made up of an SQL engine and a rest API. ksqlDB servers are deployed separately from the Kafka cluster (usually on separate machines/containers). The following picture gives an overview of a ksqlDB server.
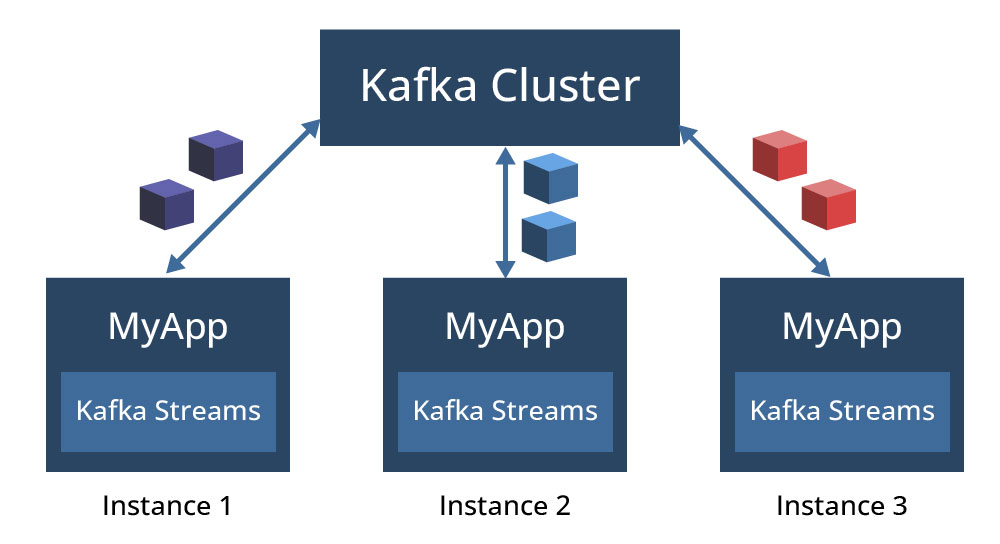
A query submitted to ksqlDB is compiled into a Kafka Streams application that is executed in the background, following the same execution model of Kafka Streams applications. A Kafka Streams application instance is run in a Java Virtual Machine (JVM) on a machine and multiple instances of an application are executed either on the same machine or spread across multiple machines. Each application instance runs in their own JVM process and is mapped to one or more partition, based on how many partitions the input topic has. This is depicted in Figure 4, where different instances of a Kafka Streams application MyApp process different partitions of a topic, with each instance running in a separate JVM process.
ksqlDB follows a similar approach for parallelism and workload distribution among ksqlDB server instances. A submitted query can be executed on multiple instances (ksqlDB servers), and each instance will process a portion of the input data from the input topic(s) as well as generate portions of the output data to output topic(s).
Workloads created by a specific query set can be distributed across multiple ksqlDB servers using the ksql.service.id configuration. The service id configuration is used to define if a ksqlDB server instance belongs to a specific ksqlDB cluster: If multiple ksqlDB servers connect to the same Kafka cluster with the same ksql.service.id they form a ksqlDB cluster and share the workload. Otherwise, if multiple ksqlDB servers connect to the same Kafka cluster but don't share the same ksql.service.id, then each ksqlDB server gets a different command topic and forms separate ksqlDB clusters based on the ksql.service.id configuration. This is shown in Figure 5, where 3 ksqlDB servers share different ksql.service.ids, building 2 different ksqlDB clusters. It is important here to notice that a ksqlDB cluster here refers to a group of cooperating ksqlDB servers, processing the same workload. In this example, the assignment of more ksqlDB servers to the "finance" cluster can be useful to enhance the processing of workloads.
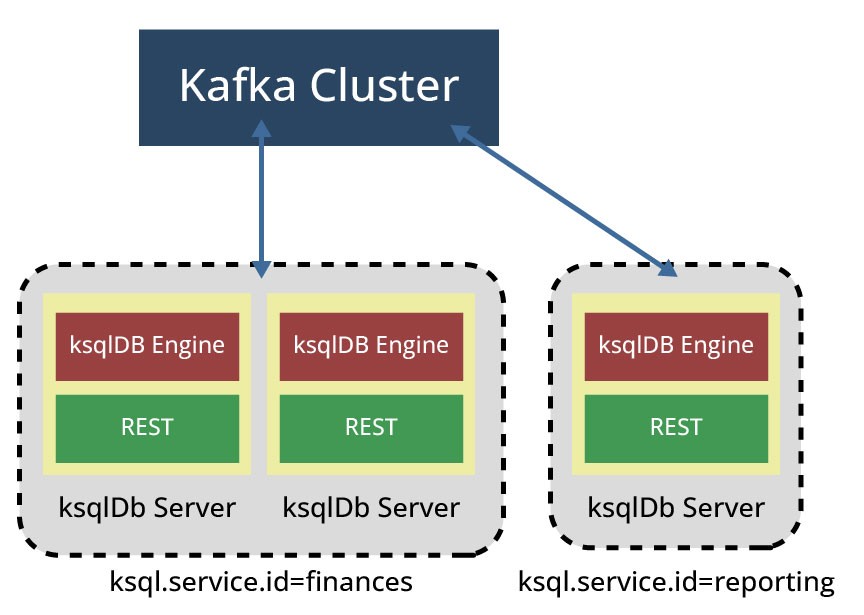
Since ksqlDB servers with the same service ID are members of the same consumer group, Kafka automatically handles the reassignment/distribution of workload as new ksqlDB servers are added or removed (removal could be manual or automatic, e.g., due to a system fault).
Running additional instances with the same service id will grant your application additional processing capacity. Scaling down, removing ksqlDB servers can be done at any time. In all cases, ksqlDB server instances communicate with Kafka clusters so that changes can be conducted without a necessary restarting of the application.
SQL-Engine
The SQL engine is part of the ksqlDB server responsible for parsing SQL statements, converting the statements into Kafka Streams topologies, and ultimately running the Kafka Streams applications and queries. A visualization of this process is shown in Figure 6.
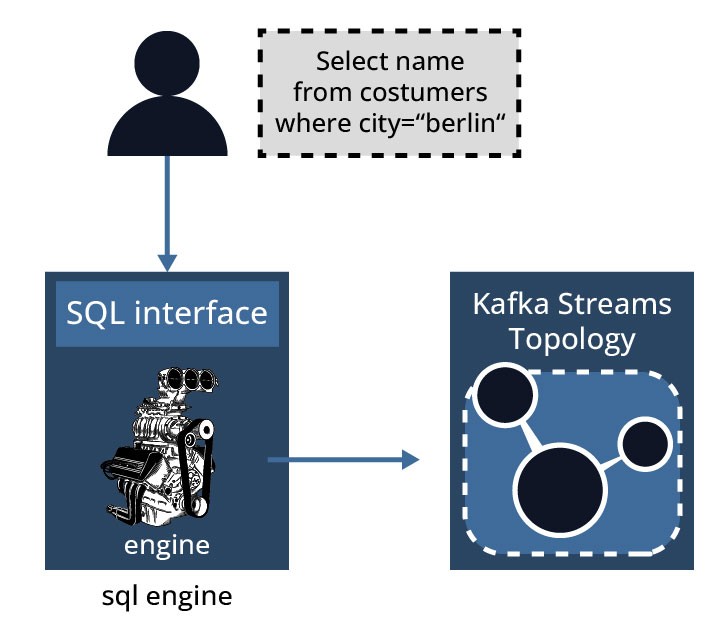
At the beginning of the process, the desired application logic is translated into SQL statements which are build and run by the engine on available ksqlDB servers. Each ksqlDB Server instance runs a ksqlDB engine. The ksqlDB engine is implemented in the KsqlEngine.java class.
KsqlDB Rest Service/REST Interface
ksqlDB includes a REST interface that allows clients to interact with the SQL engine. It enables communication from the ksqlDB command line interface (CLI), ksqlDB UI, Confluent Control Center, or from any other REST client. Over the REST interface, clients can submit different types of queries, like DML statements, and execute different tasks like checking the cluster status/health of the cluster and much more. By default, the rest interface listens on port 8088 and communicates over HTTP, but the endpoint's port can be changed using the listener's config. Communication over HTTPs can be enabled using the ssl configs.
The REST API is optional and can be entirely disabled depending on the operation/deployment mode. If ksqlDB is used interactively, it must be activated.
The ksqlDB clients
Confluent provides different clients for interacting with ksqlDB and ksqlDB servers.
ksqlDB CLI
The ksqlDB CLI (ksqlDB command line interface) is a command-line application that allows interactions with a running ksqlDB server. Through a console with interactive sessions, users can submit queries, inspect topics, adjust ksqlDB configurations, thus experimenting with ksqlDB and developing streaming applications. The ksqlDB CLI is designed to be familiar to users of MySQL, Postgres, and similar applications. The ksqlDB CLI is implemented in the io.confluent.ksql.cli package.
It is distributed as a Docker image (confluentinc/ksqldb-cli) and is part of various Confluent Platform distributions (fully managed on Confluent Cloud, or through a self-managed deployment).
ksqlDB UI
The Confluent Platform also includes a UI for interacting with ksqlDB. This UI is a commercial feature, only available for the commercially licensed version of Confluent Platform and Confluent Cloud. More than a visualization of queries and submitted queries, it also allows additional operations like the visualization of the data flow of data, the creation of streams and tables using web forms.
Deployment modes
- Depending on the level of interactivity with ksqlSB servers, ksqlDB provides two different deployment modes:
- Interactive mode
- Headless mode
Interactive deployment mode
Interactive mode is the default deployment mode for ksqlDB, and no special configuration is necessary to run in this mode.
In this mode, the REST interface is used by the various clients (favorite REST clients, ksqlDB CLI or Confluent Control) to connect to. Clients can submit new queries anytime, on the fly, interacting with ksqlDB servers through the REST interface (see Figure 7). For example, A user can explore the existing topics in the Kafka cluster, write queries, and inspect their results in real time. This mode also allows any number of server nodes to be dynamically started, and persistent queries to be added or removed without restarting the servers.
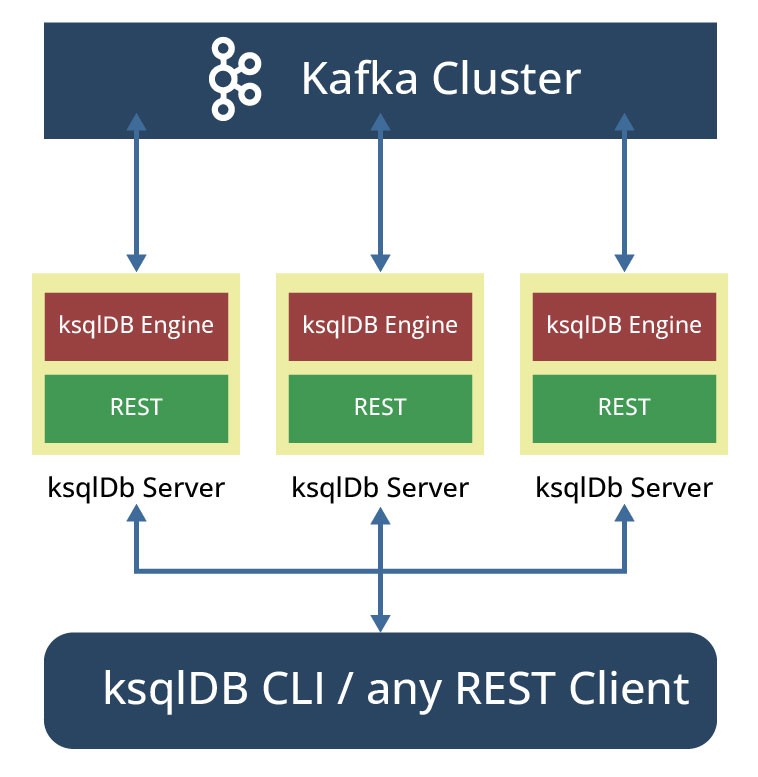
The sharing of statements with servers in the cluster is only possible with the help of an internal topic called the command topic. All queries submitted to the SQL engine (via the REST API) are written to this topic. This topic auto created and managed by ksqlDB, stores besides SQL statements, some metadata to ensures that statements are built compatibly across ksqlDB restarts and upgrades. KsqlDB servers in the same cluster (sharing the same ksql.service.id) are able to share statements being executed, and the workloads associated with them.
The command topic's name is inferred from the ksql.service.id setting in the server configuration file.
Headless deployment mode
The headless mode, also called application mode, doesn't allow clients interactively submitting queries against the ksqlDB cluster. All queries are written in a SQL file, and ksqlDB started with this file as an argument: ksqlDB server instances will use this file and each server instance will read the given SQL file, compile the ksqlDB statements into Kafka Streams applications and start execution of the generated applications (see Figure 8).
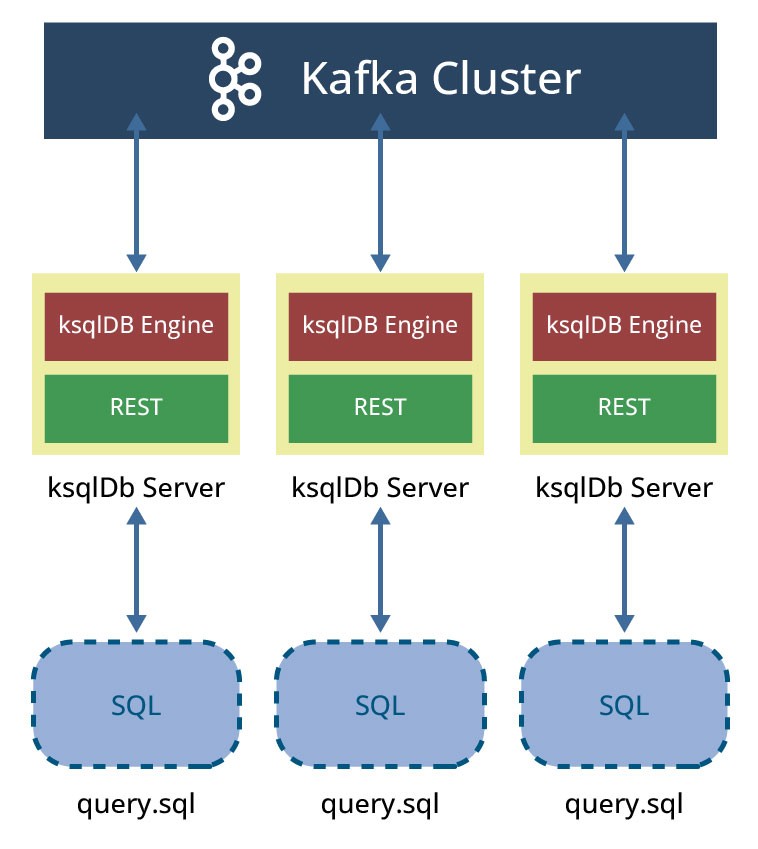
Unlike interactive deployment, headless mode does not use the command topic for statement-based replication. However, it does write some internal metadata to a config topic. Headless Though any number of server nodes can be started in headless mode, it is important to note that these nodes cannot be started dynamically at will.
This mode can be interesting for scenarios where isolation is required, for example when a production environment is to lockdown, to ensure that no changes and additional workload is made to the running queries.
A deep dive in the SQL
ksqlDB combines SQL databases constructs to Kafka Streams data abstraction, allowing to read, filter, transform, or process streams and tables of events, which are backed by Kafka topics. Like a conventional RDBMS, ksqlDB includes SQL grammar, a parser, and an execution engine. The SQL dialect implemented in KSQL (and subsequently ksqlDB) extends classical SQL to support streams and streams related abstractions. This dialect contains language constructs as SELECT for projection, FROM for defining sources, WHERE for filtering, JOIN for joining. Like traditional SQL, it offers support for DDL and DML operations with streams and tables as equivalent "collections" to tables in traditional relational databases.
Data Definition Language (DDL) statements
- In databases, DDL statements are responsible for modifying metadata only and don't operate on data. Following an example of DDL statements:
- CREATE STREAM for creating a table equivalent collection
- CREATE TABLE for creating a table equivalent collection
- DROP STREAM
- DROP TABLE
- SHOW STREAMS | TABLES
- DESCRIBE (EXTENDED) STREAMS
- DESCRIBE (EXTENDED) TABLES
- CREATE STREAM AS SELECT (CSAS)
- CREATE TABLE AS SELECT (CTAS)
Data Manipulation Language (DML) statements
- In contrast to DDL statements, Data Manipulation Language statements modify data only and don't change metadata. The ksqlDB engine compiles DML statements into Kafka Streams applications, which run on a Kafka cluster. The DML statements include:
- SELECT
- INSERT INTO
- INSERT INTO VALUES
Data manipulation language (DML) statements, like UPDATE and DELETE, aren't available.
Views
Just as in traditional databases, KSQL and ksqlDB offer materialized views which are named objects that contain the results of a query. In known traditional RDBMS, views can be updated either lazily (update is queued to be applied later) or eagerly (update is applied whenever new data arrives). Views in ksqlDB are eagerly maintained.
Schemas, types, and operators
ksqlDB support schemas. Data sources like streams and tables have an associated schema. This schema defines the columns available in the data, just like columns in a traditional SQL database table. KsqlDB supports user-defined types as well. Custom types can be defined to specify a group of field names and their associated data types, and then later used in queries to reference the same collection of fields. The following command can be used to create a custom type:
Create a custom type CREATE TYPE <type_name> AS <type>;
- ksqlDB supports various types and includes a rich set of functions and operators for working with data, like the following specified operators:
- arithmetic operators (+,-, /, *, %)
- String concatenation operators (+, ||)
- operators for accessing array indices or map keys ([])
- -struct dereference operators (->).
- ARRAY<element-type> A collection of elements of the same type (e.g., ARRAY<STRING>)
- BOOLEAN A Boolean value
- INT 32-bit signed integer
- BIGINT 64-bit signed integer
- DOUBLE Double precision (64-bit) IEEE 754 floating-point number
- DECIMAL (precision, scale) A floating-point number with a configurable number of total digits (precision) and digits to the right of the decimal point (scale)
- MAP <key-type, element-type> An object that contains keys and values, each of which coincides with a data type (e.g., MAP<STRING, INT>)
- STRUCT<field-name field-type [, ...]> A structured collection of fields (e.g., STRUCT <FOO INT, BAR BOOLEAN>)
- VARCHAR or STRING
ksqlDB provides additionally an interface for defining own functions (user defined functions) implemented in Java to process user-defined types as well.
Push and pull queries
ksqlDB introduced the concept of push queries, marking a difference with its former version, KSQL. Push Queries represents one of the main differences between KSQL and ksqlDB.
Pull queries, used so far in KSQL, correspond to known queries in traditional databases, where the current state of a database is returned after a keyed lookup work. A select statement in a traditional database illustrates this.
The query issued by a client is processed to retrieve a result as of "now" and terminates as that state is returned to the client. In Figure 9, the query (SELECT * FROM orders;) returns all orders at the time of the query's processing. Ingoing order 23 in this case is not fully ingested and not returned in the result set.
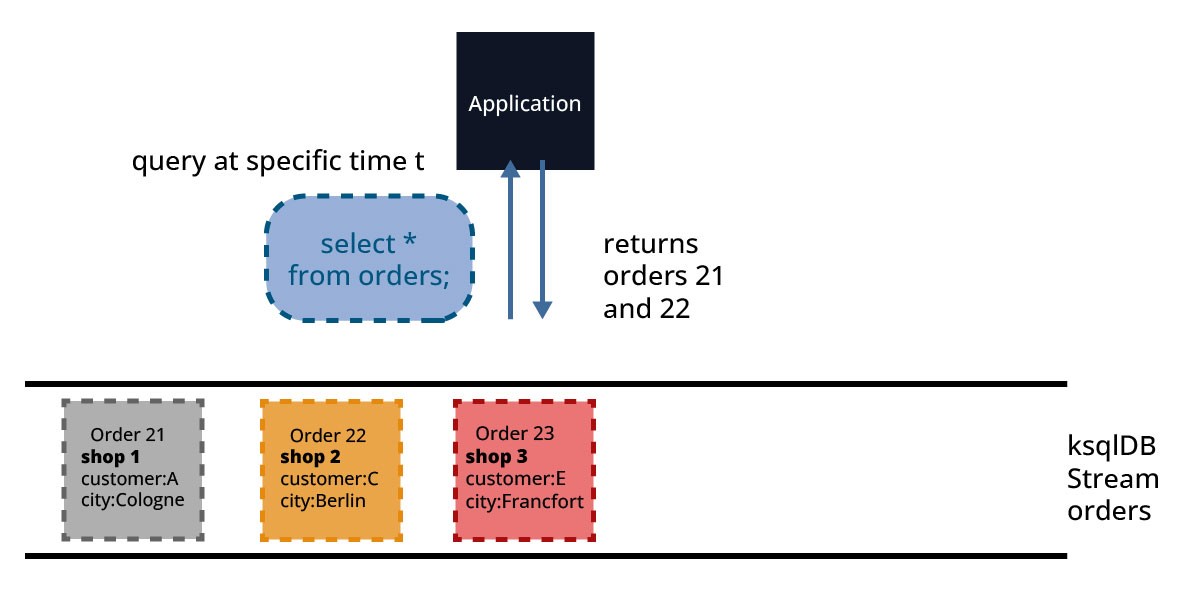
Pull queries are thus short-lived queries that are used to perform keyed lookups of data. They are a great match for request/response flows. They can be used by clients that need to work with ksqlDB in a synchronous/on-demand workflow.
Pull queries can only be used against materialized views or ksqlDB tables. Because materialized views are incrementally updated as new events arrive, pull queries run with predictably low latency.
A push query is a form of query issued by a client that subscribes to a result as it changes in real-time. Push queries, contrarily to pull queries, run continuously and emit results to clients whenever new data is available. "push" because the result of the query's conditions is pushed to the client as soon as new data fulfilling the query's conditions happen. Figure 10 illustrates this: after receiving the query (SELECT * FROM orders EMIT CHANGES;), ingested orders in the ksqlDB stream orders are returned as result to the Application.
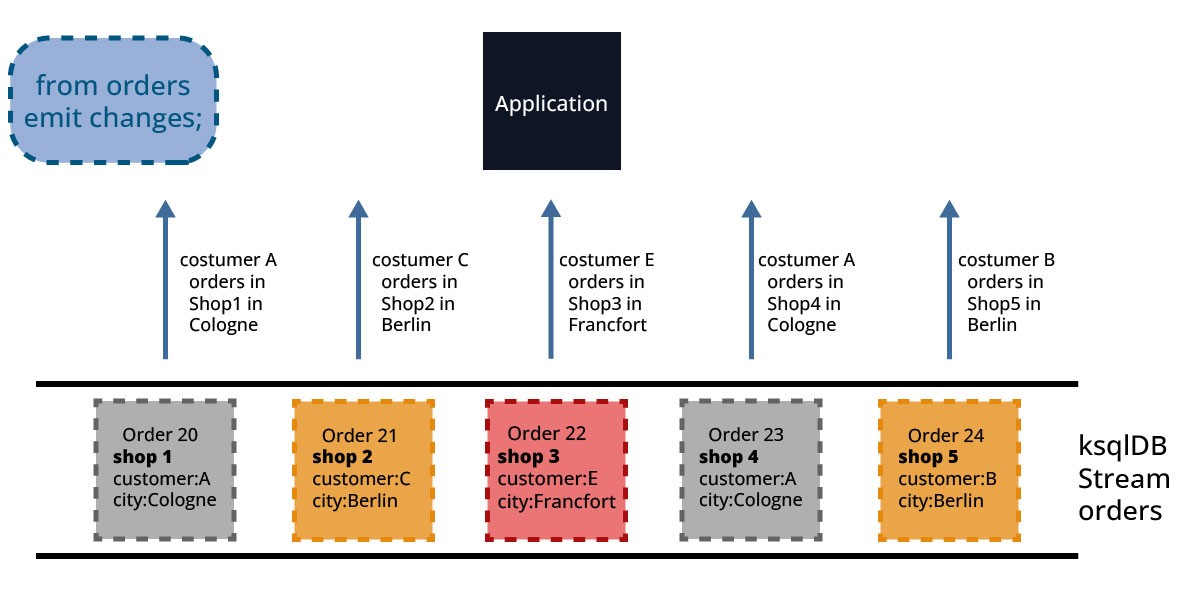
Push queries as pull queries are expressed using a SQL-like language and are identified by the EMIT CHANGES clause at the end of the queries. This syntax addition is incompatible with previous versions of KSQL. This means that a streaming query in KSQL will not be interpreted correctly as a streaming query in ksqlDB.
Contrarily to pull queries, push queries can be used to query either streams or tables for a particular key and are not limited to key look-ups assignments. Push queries enable the querying of a stream or materialized table with a subscription to the results. This subscription is not limited to a specific type of query output. It is for example possible to subscribe to the output of a query that returns a stream. A push query emits refinements to a stream or materialized table, which enables reacting to new information in real-time.
Push queries are a good match for asynchronous application workflows and event-driven microservices that need to observe and react to events quickly.
Figure 11 offers a good summary of the differences between pull and push queries.

Distributions von ksqlDB
ksqlDB is owned and maintained by Confluent Inc. as part of its Confluent Platform product. ksqlDB is available in 3 different distributions:
- standalone
- via confluent Cloud
- and via confluent Plattform
ksqlDB in standalone distribution is free to download and free to use under the Confluent Community License. The Confluent Community License does not fulfill all requirements defined by the Open-Source Initiative for open-source projects. In general, we recommend, that you should take a close look at Confluent's license policy before using the software.
Figure 12 gives an overview of the different licensing models used by various components in the Kafka universe.
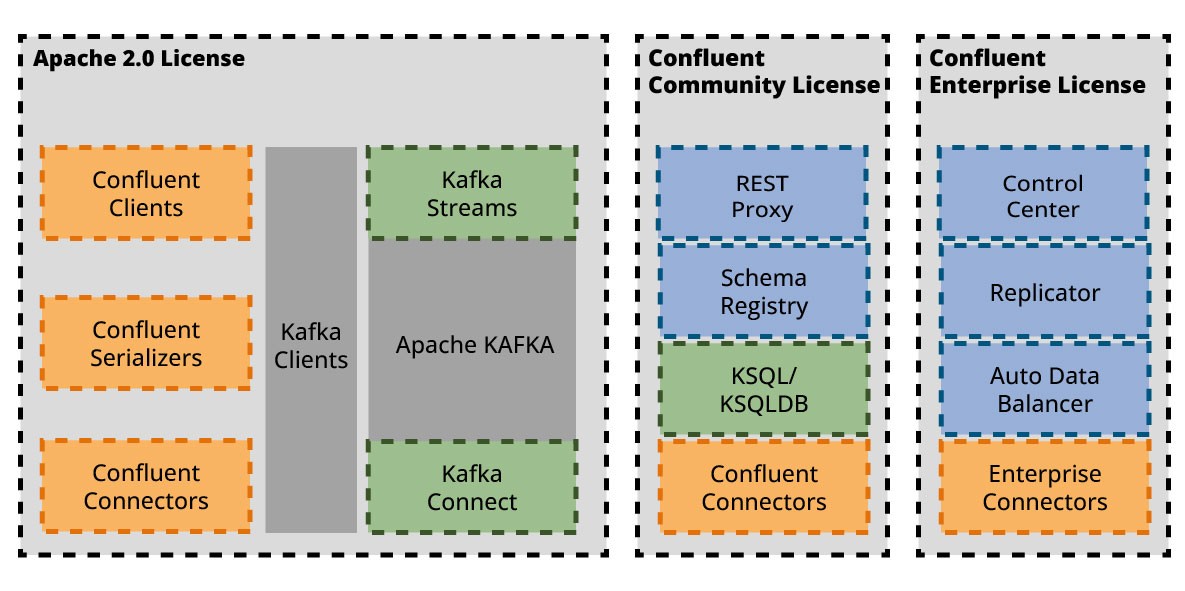
In standalone mode, different docker-compose files are provided to run ksqlDB in containers with existing Kafka installations or set up a Kafka installation with running ksqlDB. (See https://ksqldb.io/quickstart.html)
Standalone ksqlDB distribution has limited commercial support by Confluent.
The confluent cloud offers a fully managed cloud-native platform and service for Apache Kafka. In Confluent Cloud a ksqlDB cluster can be spined up based on a pay-as-you-go strategy. Instructions are available to launch Kafka and ksqlDB cluster in Confluence cloud (https://ksqldb.io/quickstart-cloud.html#quickstart-content)
KsqlDB can also be used in a self-managed setting as part of Confluent's Platform for Data in Motion. Confluent offers versions of ksqlDB tested and packaged with a complete set of components (Kafka, diverse connectors, schema management tools, and more). Commercial support is available through a subscription to Confluent Platform. Each new version of the Confluent Platform wraps a specific, previously shipped version of the standalone distribution.
Summary
Senior Chief Consultant bei ORDIX
Kommentare