
Better be safe than sorry or how to "cluster" clusters. MySQL InnoDB ClusterSets
We have already reported several times about the MySQL InnoDB Cluster and the associated components such as the MySQL Shell and the MySQL Router (e.g., https://blog.ordix.de/mysql-shell-cluster-your-application-in-40-minutes). With version 8.0.28 there is another innovation in this "triumvirate". The InnoDB ClusterSets. This allows the DBA to comfortably set up an asynchronous replication between two InnoDB clusters with just a few commands.
Double trouble?
Let's assume that we are already running an InnoDB cluster for our "use-case" in a region like e.g., Germany. This cluster consists of three nodes, which are distributed over several locations (Frankfurt, Berlin, Hamburg). In addition to a write application, a "reporting" application also has read access to the cluster. The distribution (reading vs. writing application) is handled transparently by the MySQL router (Fig. 1 from PPT).
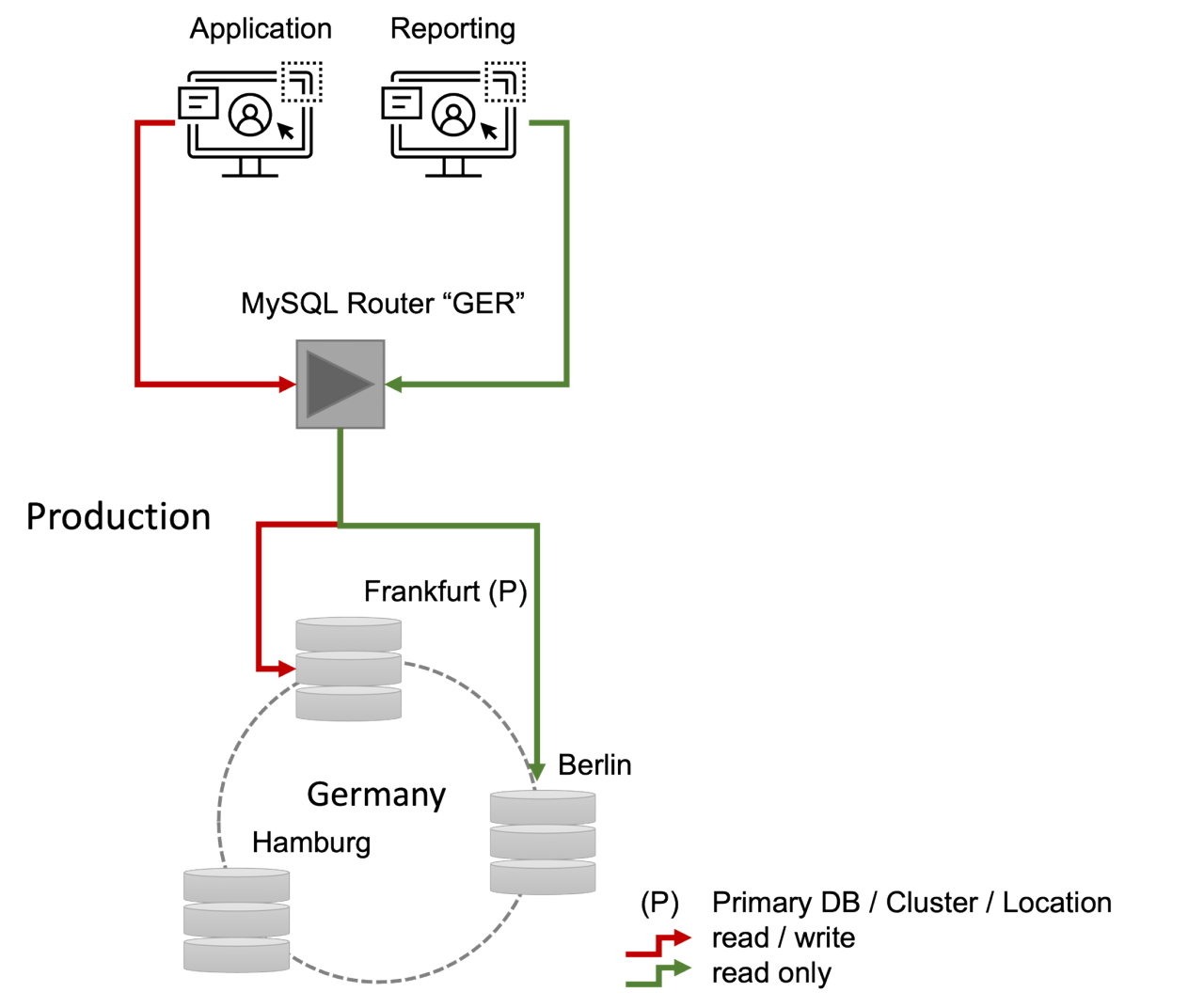
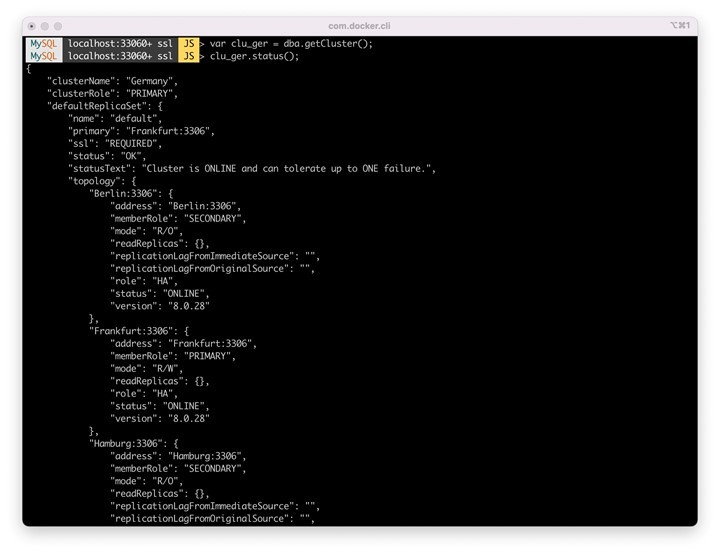
We can observe the current configuration of our cluster below. It consists of the three nodes mentioned above. The node "Frankfurt" is in the role "Primary" server and can be used for reading and writing.
Now we would like to expand our business model to the USA and operate a cluster locally there. Reasons for this could be an expansion of the DR (disaster recovery) concept and / or a better performance (for the reading) application.
Off to the "new world" ...
We assume that three databases have already been made available in the new region "America" (NewYork, Boston, LasVegas). At this point, these are three completely independent database instances that have no relationship to each other and especially not to the cluster in Germany.
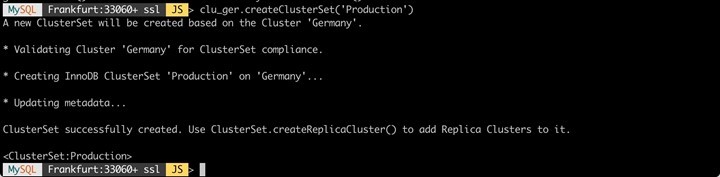
In the first step we use our existing cluster "Germany" and tell it that a "ClusterSet" "Production" should be built.
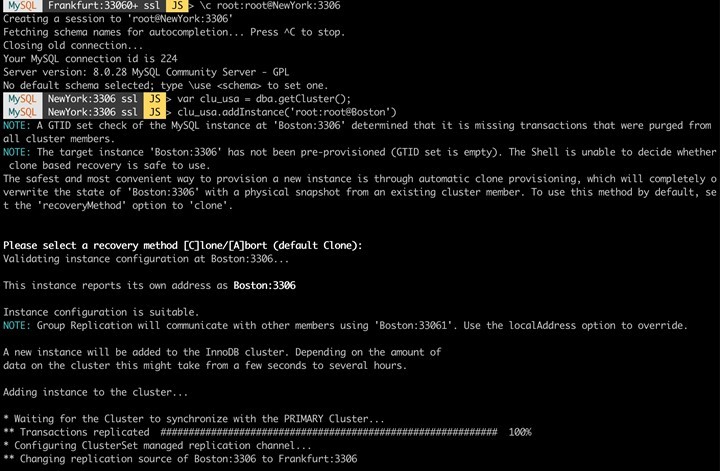
Currently, nothing has changed in the physical setup of the infrastructure (number of DB systems). For this reason, we are now adding the first (!) server from "overseas" to the Cluster "America" and attach the Cluster to the "ClusterSet".
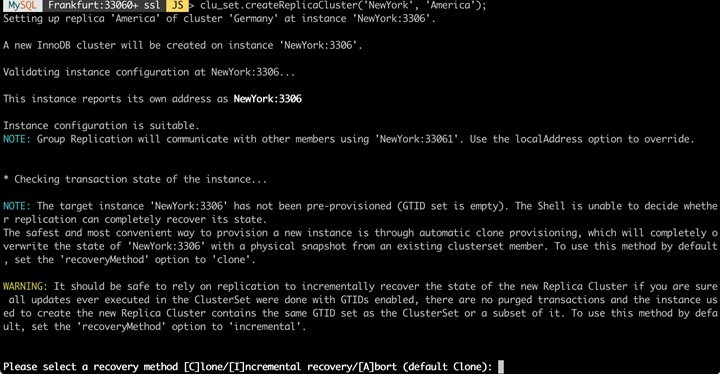
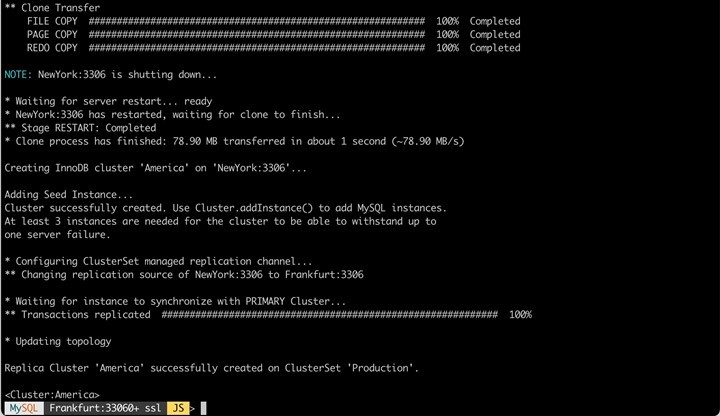
This way, an "American" cluster is "attached" to our "German" cluster, which currently consists of only one node "NewYork". We change this by adding two more nodes (here only the process for one node "Boston" is shown).
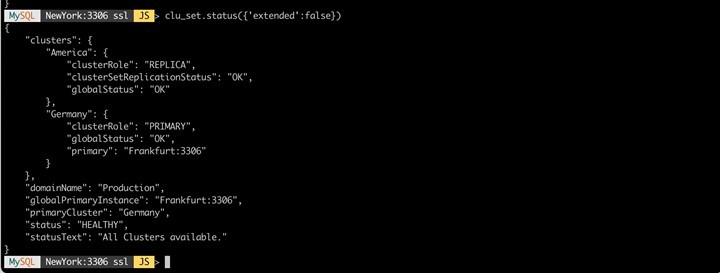
After the successful setup, our ClusterSet "Production" is now in operation with two clusters in two regions. It is clear to see that the "Germany" cluster is leading, and "America" is currently acting as a replica
Our setup looks like this:
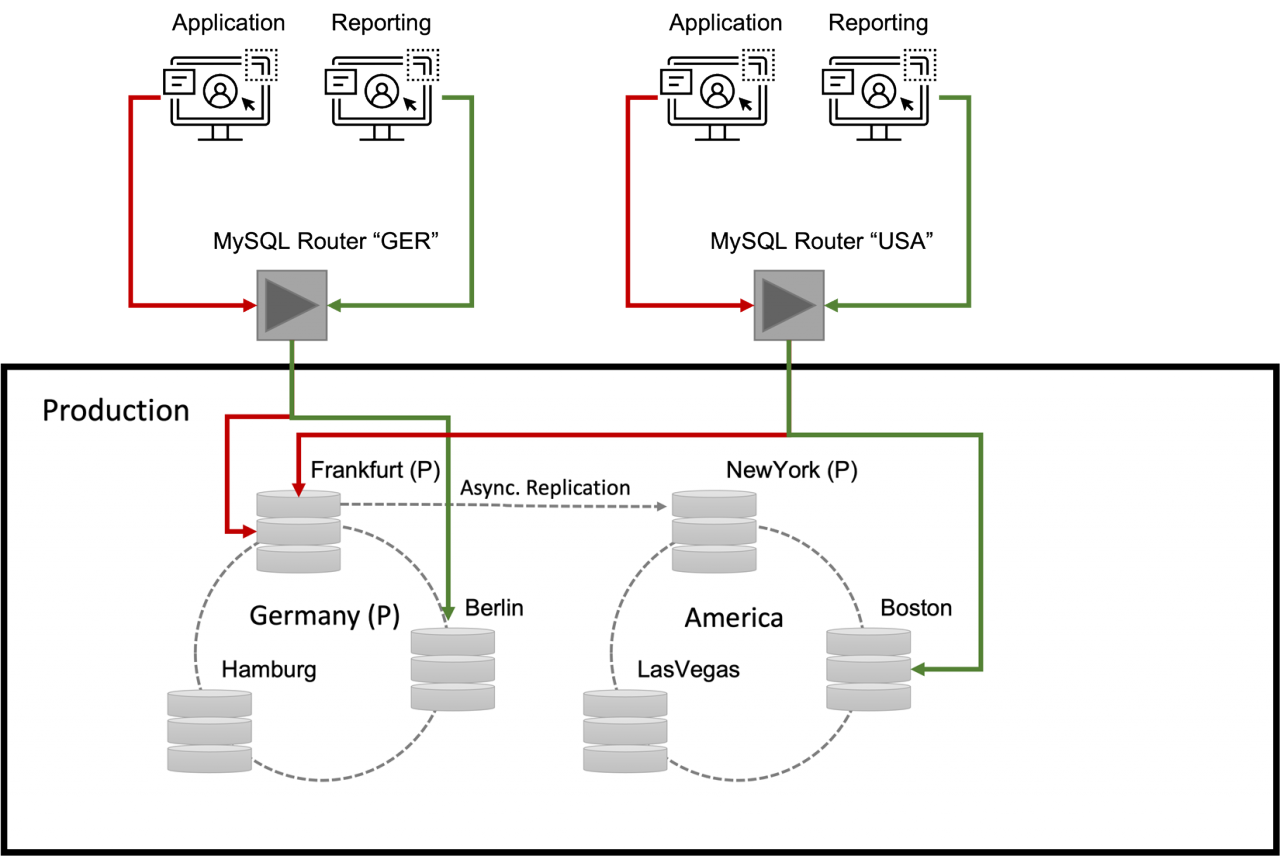
It should be noted that the connection between the two clusters "Germany" and "America" is asynchronous. This means that if the "Germany" region fails, a (highly) available environment (the cluster "America") is available again on the other side of the "big pond", but there may well have been a (minimal) loss of data during the failover there, so that a few transactions may not have made it to the "other side".
Route is calculated...
The routers (which are quasi mandatory in the context of clusters) are set up as usual in the simplest case. During bootstrapping, they recognize the setup of the cluster set and reliably route write requests to the primary (!) node in the primary (!) cluster. Other routers (e.g., for read requests) can optionally be pointed to the secondary nodes of the primary or secondary cluster. These routing strategies can also be defined directly via the MySQL shell.
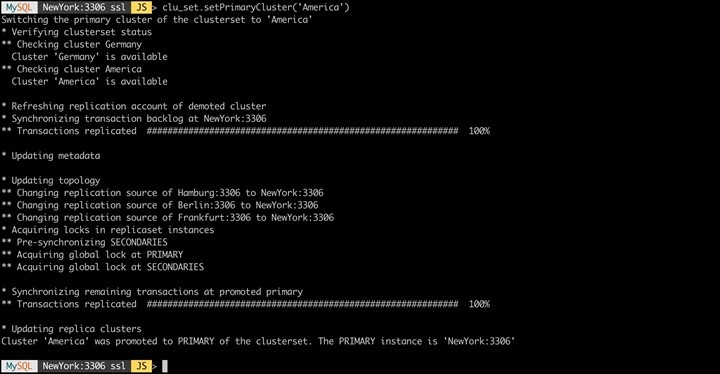
Of course, the roles of the databases in your clusters but also the roles of the clusters within the set can be changed. In case of failure, a reconfiguration is of course also done automatically. For example, if a node within a cluster fails, another instance becomes primary within the same set. If the primary cluster (!) fails, another set of the cluster (a ClusterSet can of course consist of more than two sets of clusters) is defined as primary. The routers detect these changes independently and redirect the corresponding applications accordingly.
Clustered, cluster?!
Once again, the functionality of the InnoDB cluster has been usefully extended. Of course, it should be noted that a replication set does not work synchronously and is thus more of a DR solution (from the perspective of the primary cluster) and not really a "clustered cluster".
Nonetheless, in this age of virtual and/or cloud environments, it is impressive how quickly and transparently such complex environments can be deployed and managed.
Do you have questions about running MySQL? Please contact us.
Principal Consultant bei ORDIX
Kommentare